标签:tail htm else csdn ddl log 时间复杂度 ram keyword
转载:http://www.cnblogs.com/jingmoxukong/p/4308823.html(很多排序代码)
http://blog.csdn.net/middlekingt/article/details/8446552
将待排序序列R[0...n-1]看成是n个长度为1的有序序列,将相邻的有序表成对归并,得到n/2个长度为2的有序表;将这些有序序列再次归并,得到n/4个长度为4的有序序列;如此反复进行下去,最后得到一个长度为n的有序序列。
综上可知:
归并排序其实要做两件事:
(1)“分解”——将序列每次折半划分。
(2)“合并”——将划分后的序列段两两合并后排序。
我们先来考虑第二步,如何合并?
在每次合并过程中,都是对两个有序的序列段进行合并,然后排序。
这两个有序序列段分别为 R[low, mid] 和 R[mid+1, high]。
先将他们合并到一个局部的暂存数组R2中,带合并完成后再将R2复制回R中。
为了方便描述,我们称 R[low, mid] 第一段,R[mid+1, high] 为第二段。
每次从两个段中取出一个记录进行关键字的比较,将较小者放入R2中。最后将各段中余下的部分直接复制到R2中。
经过这样的过程,R2已经是一个有序的序列,再将其复制回R中,一次合并排序就完成了。
掌握了合并的方法,接下来,让我们来了解 如何分解。
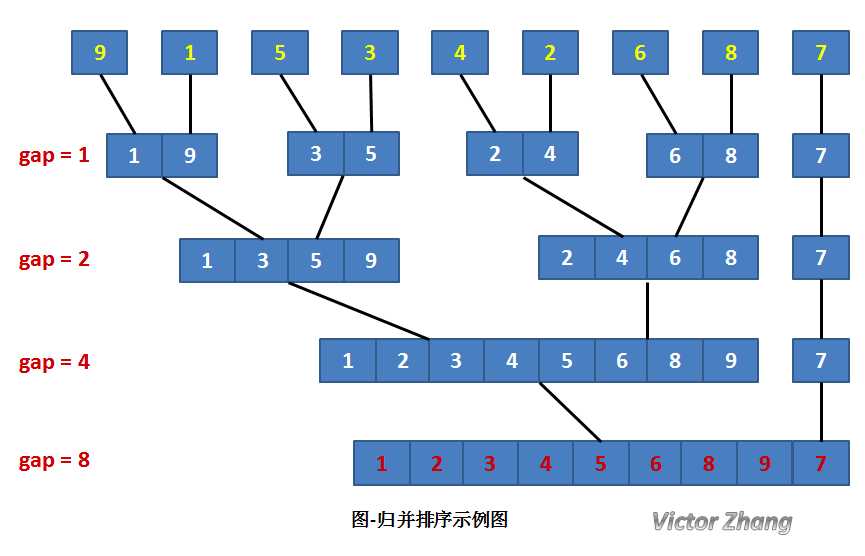
在某趟归并中,设各子表的长度为gap,则归并前R[0...n-1]中共有n/gap个有序的子表:R[0...gap-1], R[gap...2*gap-1], ... , R[(n/gap)*gap ... n-1]。
调用Merge将相邻的子表归并时,必须对表的特殊情况进行特殊处理。
若子表个数为奇数,则最后一个子表无须和其他子表归并(即本趟处理轮空):若子表个数为偶数,则要注意到最后一对子表中后一个子表区间的上限为n-1。
标签:tail htm else csdn ddl log 时间复杂度 ram keyword
原文地址:http://www.cnblogs.com/fanguangdexiaoyuer/p/6549702.html