标签:tab 执行顺序 sql执行顺序 sql查询 tran from bsp msdn aik
原文链接:http://www.cnblogs.com/liuzhendong/archive/2011/10/27/2226805.html
1.笛卡尔积(Cartesian product)
顾名思义, 这个概念得名于笛卡儿. 在数学中,两个集合 X 和 Y 的笛卡儿积(Cartesian product),又称直积,表示为 X × Y,是其第一个对象是 X 的成员而第二个对象是 Y 的一个成员的所有可能的有序对.
假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以扩展到多个集合的情况。类似的例子有,如果A表示某学校学生的集合,B表示该学校所有课程的集合,则A与B的笛卡尔积表示所有可能的选课情况。
2.Join类型
cross join 是笛卡儿乘积就是一张表的行数乘以另一张表的行数.
inner join 只返回两张表连接列的匹配项.
left join 第一张表的连接列在第二张表中没有匹配是,第二张表中的值返回null.
right join 第二张表的连接列在第一张表中没有匹配是,第一张表中的值返回null.
full join 返回两张表中的行 left join+right join.
3.在对两表进行各种类型的join (cross, left, right, full, inner)时, 都需要构造笛卡尔积.
有时想想不可思议, 若两个特大表进行join, 难道sql就直接上笛卡尔积吗? 难道不事前进行on的条件过滤吗? 那数据量得多大?
4.查一下MSDN就清楚了整个SQL的执行顺序.
http://msdn.microsoft.com/en-us/library/ms189499(v=SQL.100).aspx
Processing Order of the SELECT statement
The following steps show the processing order for a SELECT statement.
1.FROM
2.ON
3.JOIN
4.WHERE
5.GROUP BY
6.WITH CUBE or WITH ROLLUP
7.HAVING
8.SELECT
9.DISTINCT
10.ORDER BY
11.TOP
也就是说, 先进行on的过滤, 而后才进行join, 这样就避免了两个大表产生全部数据的笛卡尔积的庞大数据.
这些步骤执行时, 每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回 给调用者。
如果没有在查询中指定某一子句,将跳过相应的步骤。
下面是<<Inside Microsoft SQL Server 2008 T-SQL Querying>>一书中给的一幅SQL 执行顺序的插图.
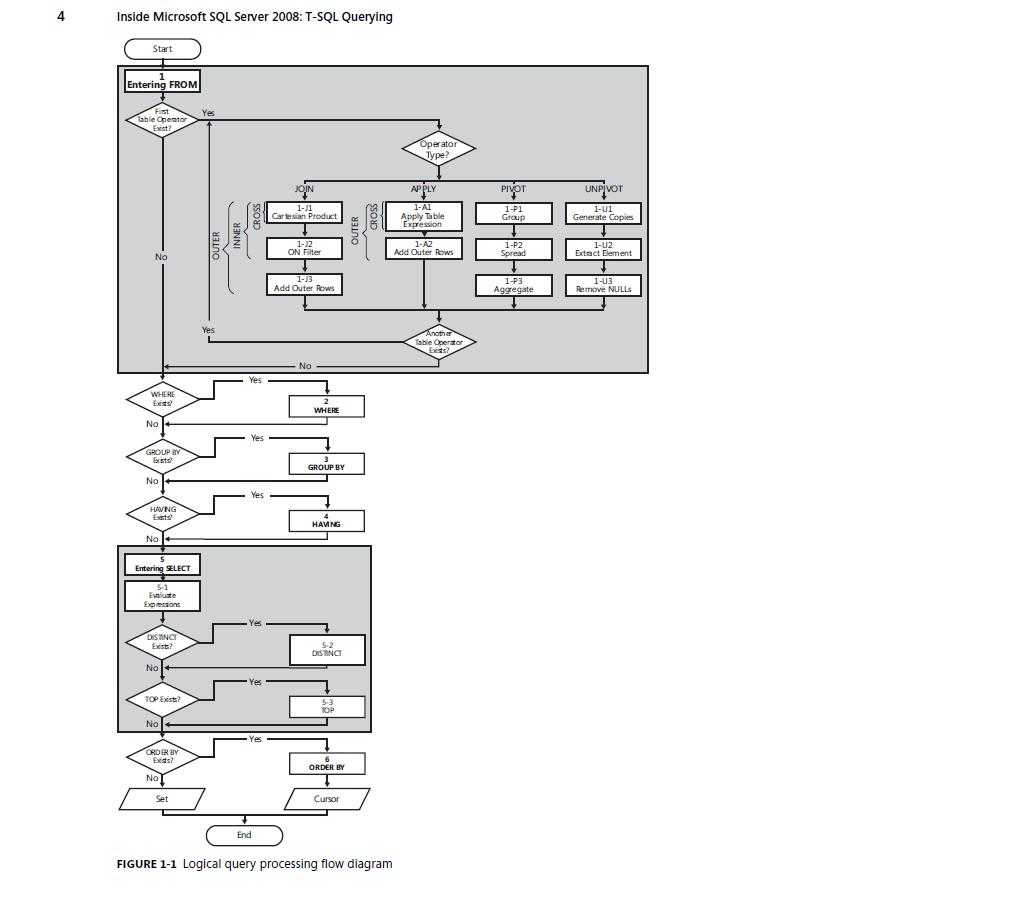
5.On的其余过滤条件放Where里效率更高还是更低?
select * from table1 as a
inner join table2 as b on a.id=b.id and a.status=1
select * from table1 as a
inner join table2 as b on a.id=b.id
where a.status=1
查查MSDN就清楚了. http://msdn.microsoft.com/en-us/library/ms189499(v=SQL.100).aspx
There can be predicates that involve only one of the joined tables in the ON clause. Such predicates also can be in the WHERE clause in the query. Although the placement of such predicates does not make a difference for INNER joins, they might cause a different result when OUTER joins are involved. This is because the predicates in the ON clause are applied to the table before the join, whereas the WHERE clause is semantically applied to the result of the join.
翻译之后是, 如果是inner join, 放on和放where产生的结果一样, 但没说哪个效率速度更高? 如果有outer join (left or right), 就有区别了, 因为on生效在先, 已经提前过滤了一部分数据, 而where生效在后.
综合一下, 感觉还是放在on里更有效率, 因为它先于where执行.
听说可以通过sql的查询计划来判别实际的结果, 明天再研究, 欢迎高手给与批评指正.
********************************************************************************************************
2011/11/21 最新体会
刚看到<<Microsoft SQL Server 2008技术内幕: T-SQL查询>>一书中对于连接的描述和我先前理解的不太一样;
Itzib在书上说先笛卡尔积, 然后再on过滤, 如果join是inner的, 就继续往下走, 如果join 是left join, 就把on过滤掉的左主表中的数据再添加回来; 然后再执行where里的过滤;
on中不是最终过滤, 因为后面left join还可能添加回来, 而where才是最终过滤.
只有当使用外连接(left, right)时, on 和 where 才有这个区别, 如果用inner join, 在哪里制定都一样, 因为on 之后就是where, 中间没有其它步骤.
********************************************************************************************************
参考资料:
SELECT (Transact-SQL)
http://msdn.microsoft.com/en-us/library/ms189499(v=SQL.100).aspx
FROM (Transact-SQL)
http://msdn.microsoft.com/en-us/library/ms177634(v=SQL.100).aspx
SQL Server 查询处理中的各个阶段(SQL执行顺序)
http://www.cnblogs.com/chinabc/articles/1597198.html
INNER JOIN时条件放在ON里还是WHERE里效率更高
http://social.msdn.microsoft.com/Forums/zh-CN/sqlserverzhchs/thread/e1198287-96d5-4e9e-b1d0-d2d4f5ba4e20
连接语句的运算顺序或原理
http://social.msdn.microsoft.com/Forums/zh-CN/sqlserverzhchs/thread/6f61bd10-6fb9-4035-bd51-d9cc13f7132a/
标签:tab 执行顺序 sql执行顺序 sql查询 tran from bsp msdn aik
原文地址:http://www.cnblogs.com/zuizui1204/p/6553870.html