标签:不同类 project 分发 调优 hold 写入 合并 分区 多次
转载自xiaorui
部分用户(尤其对外输出)使用MaxCompute(原Odps)时,由于对产品的使用层面和执行层面了解程度不同,导致提交的任务执行时间过长、占用了较多集群资源;严重的会导致失败、不仅需要投入支持同学精力协助解决、也影响了用户正常业务。 合并整理部分性能提升方法方便支持用户查询和优化Sql,提高效率;部分需要原来手动调优的如mapjoin、ppd谓词下推注意分区位置等原有的调优设置在不断衍进的产品中都已实现了自动化调优、 不同阶段的产品调优参数和细节会有不一致、但是熟悉了调优思路和方法后可以做到举一反三、逐步深入。
整体上,调优从底层到sql可以有多个层面的调优,随着产品的不断完善,部分调优已经实现了自动化。如果用户能熟悉常见的调优机制和执行原理,在开发执行sql、业务逻辑和相关参数设置调整来提高性能、可以做到事半功倍。
1. 硬件及操作系统层面调优:包括磁盘I/O调优(多路复用等)、网络调优(缓冲区大小、连接数放大等)、内存调优(虚拟内存设置、内存控制等);
2. 分布式计算平台及存储层面调优:存储格式设置、压缩格式设置、RPC调用设置、连接数控制设置、调度机制设置、block及分片设置、执行资源设置等;
3. 业务逻辑层面及参数调整,除整体执行的调优外,对不同类型的操作进行参数级别的调优、针对聚合、连接、一读多写等修改为不同的sql或者设置不同的参数可以极大的提高性能;
4. Sql层面及应用层面的调优,重构sql写法、合并sql,大小表连接修改为mapjoin等,在odps2.0中已处理了自动mapjoin等、目前未升级用户及对外输出的用户仍需要修改sql来支持;
不同层面调优及优缺点见下: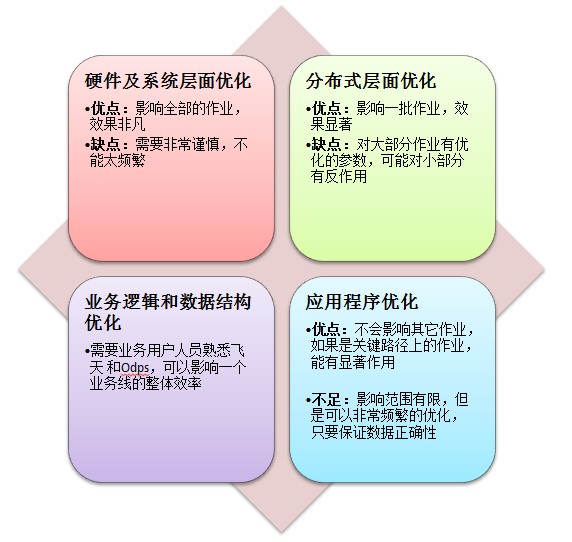
1. 大小表关联修改为mapjoin,增加Mapjoin hint
方法及注意事项:
2. 数据倾斜
数据倾斜表现:
任务进度长时间维持在99%,查看监控,只有少量 reduce 子任务未完成
单一 reduce 记录数与平均记录数差异多大,最长时长远大于平均时长
优化方法及注意事项:
3.小文件过多-动态分区生成,减少小文件的生成
方法及注意事项:
4. 小文件过多合并
方法及注意事项:
5. Map 端一读多写
场景及优化:
多次读取同一张物理表,执行不同操作,写入多张表;考虑与multiinsert 的联系和区别,是否合适做修改
建立临时表,实现临时表的并行化
注意事项:
6. 分区裁剪
场景:事实表很多分区,数据量大
优化:避免全表扫描,减少资源浪费;关注分区裁剪有无生效,见下注意事项:从表设计、使用上注意,尽量让分区裁剪生效
注意事项:
7. SQL 合并
场景:
1. 多次读取相同的数据且源数据数据量大、性能差、费用高
2. 统一业务流程前后关联sql或统计多种指标、筛选不同数据的sql
优化方法及注意事项:通过修改sql,合并为1个sql执行,尽量减少对相同数据源的读取次数,达到一次扫描计算多个基础统计量,一次扫描,处理多个筛选条件;以下调整列举:
8. 使用窗口函数优化SQL
窗口函数:
1. 可以进行灵活的分析处理工作
2. 使用 partition by 开窗,order by 排序
3. 可以用 rows 指定开窗范围
4. 丰富的开窗函数
优化及注意事项:合理使用窗口函数,可以减少Join次数,提高运行性能;不用窗口函数处理需要写复杂sql的功能,用开窗函数可以高效执行得到预期结果。
标签:不同类 project 分发 调优 hold 写入 合并 分区 多次
原文地址:http://www.cnblogs.com/libo66/p/6566637.html