标签:strong 建立 tps 权重 神经网络 lock 等于 技术 span
这里把按[1]推导的BP算法(Backpropagation)步骤整理一下,备忘使用。[1] 中直接使用矩阵微分的记号进行推导,整个过程十分简洁。而且这种矩阵形式有一个非常大的优势就是对照其进行编程实现时非常方便。
但其实用标量计算推导也有一定的好处,比如可以清楚地知道某个权重是被谁所影响的。
记号约定:
$L$:神经网络的层数。输入层不算。
$n^l$:第 $l$ 层神经元的个数。偏置神经元不算在内。
$W^{l}\in\mathbb R^{n^l\times n^{l-1}}$:第 $l-1$ 层到第 $l$ 层的权重矩阵。其中,$W_{ij}^{(l)}$ 表示第 $l-1$ 层第 $j$ 个神经元到第 $l$ 层第 $i$ 个神经元的权重。
$\textbf b^{(l)}\in\mathbb R^{n^l}$ :第 $l$ 层的偏置。
$\textbf z^{(l)}\in\mathbb R^{n^l}$ :第 $l$ 层各个神经元的输入。
$f_l(\cdot)$ :第 $l$ 层的激活函数。对于分类任务来说,最后一层为softmax。
$\textbf a^{(l)}\in\mathbb R^{n^l}$ :第 $l$ 层各个神经元的输出,也就是活性值。对于输入层(第0层),$\textbf a^{(0)}=\textbf x$。
下图给出了相应的图示。
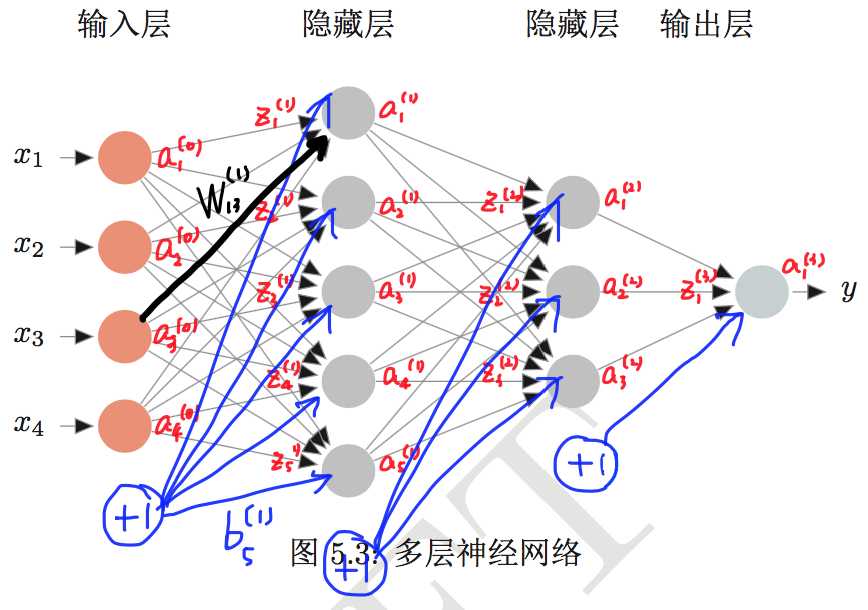
图片来源:[1]
下面可以开始推导了。首先是前向传播,计算网络输出:
$$\textbf z^{(l)}=W^{(l)}\textbf a^{(l-1)}+\textbf b^{(l)}$$
$$\textbf a^{(l)}=f_l(\textbf z^{(l-1)})$$
$$\textbf a^{(L)}=f(\textbf x;W,\textbf b)$$
整个网络实际上就可以看作是一个函数 $f$ ,1989年已经有人证明了单隐层网络可以逼近任意函数。
既然是完成从输入到输出的映射,那么网络除了可以看作分类器之外,还可以看作是特征提取器,再将网络的输出作为分类器的输入,相当于把原特征 $\textbf x$ 映射成了新的特征 $\textbf a^{(L)}$ 。
如果把网络看作分类器,那么最后一层的神经元个数 $n^L$ 应等于类别个数 $C$ ,且 $f_L(\cdot)=\text{softmax}(\cdot)$ ,归一化成概率分布:
$$\hat{\textbf y}=\textbf a^{(L)}=\text{softmax}(\textbf z^{(L-1)})$$
给定样本 $(\textbf x,\textbf y)$ ,其中 $\textbf y\in\mathbb R^C$ 是one-hot向量,那么使用交叉熵损失函数,得到网络对一个样本的损失为
$$\mathcal L(\textbf y,f(\textbf x;W,\textbf b))=-\textbf y^{\top}\log\hat{\textbf y}=-\textbf y^{\top}\ln\text{softmax}(\textbf z)=-\textbf y^{\top}\ln\frac{\exp(\textbf z)}{\textbf 1^{\top}\exp(\textbf z)}$$
设训练样本数为 $N$ ,那么经验风险为
$$R=\frac1N\sum_{i=1}^N\mathcal L(\textbf y_i,f(\textbf x_i;W,\textbf b))$$
如果使用权重矩阵的Frobenius范数作为正则项
$$||W||_F=\biggl(\sum_{l=1}^L\sum_{i=1}^{n^l}\sum_{j=1}^{n^{l-1}}(W_{ij}^{(l)})^2\biggr)^{\frac12}$$
那么结构风险为
$$R=\frac1N\sum_{i=1}^N\mathcal L(\textbf y_i,f(\textbf x_i;W,\textbf b))+\frac12\lambda||W||_F^2$$
一般来说,偏置是不加正则的。
现在考虑结构风险最小化,使用梯度下降法来更新权重矩阵和偏置。只需要求取模型对一个样本的损失的梯度 $\frac{\partial \mathcal L(\textbf y,f(\textbf x;W,\textbf b))}{\partial W^{(l)}}$(因为对多个样本的梯度就是对一个样本的梯度的累加):
$$W^{(l)}=W^{(l)}-\alpha \frac{\partial R}{\partial W^{(l)}}$$
$$\frac{\partial R}{\partial W^{(l)}}=\frac1N\sum_{i=1}^N\frac{\partial \mathcal L(\textbf y,f(\textbf x;W,\textbf b))}{\partial W^{(l)}}+\lambda W^{(l)}$$
对偏置的就不写了。
四个重要公式
好了,墨迹了半天,重点终于来了。下面就是要求解 $\dfrac{\partial\mathcal L(\textbf y,f(\textbf x;W,\textbf b))}{\partial W^{(l)}}$ 、$\dfrac{\partial\mathcal L(\textbf y,f(\textbf x;W,\textbf b))}{\partial \textbf b^{(l)}}$ 。为了简单起见,直接记作 $\dfrac{\partial \mathcal L}{\partial W^{(l)}}$ 、$\dfrac{\partial \mathcal L}{\partial \textbf b^{(l)}}$ 。
我所有的符号都是沿用的 [1] ,后面的推导过程也是。
首先摆上一些公式复习一下:
$$\frac{\partial A^{\top}\textbf x}{\partial\textbf x}=\frac{\partial \textbf x^{\top}A}{\partial\textbf x}=A$$
$$\frac{\partial \textbf y^{\top}\textbf z}{\partial\textbf x}=\frac{\partial \textbf y}{\partial\textbf x}\textbf z+\frac{\partial \textbf z}{\partial\textbf x}\textbf y$$
$$\frac{\partial \textbf y^{\top}A\textbf z}{\partial\textbf x}=\frac{\partial \textbf y}{\partial\textbf x}A\textbf z+\frac{\partial \textbf z}{\partial\textbf x}A^{\top}\textbf y$$
$$\frac{\partial y\textbf z}{\partial\textbf x}=\frac{\partial y}{\partial\textbf x}\textbf z^{\top}+y\frac{\partial \textbf z}{\partial\textbf x}$$
$$\frac{\partial \text{tr}AB}{\partial A}=B^{\top}\quad\quad\frac{\partial \text{tr}AB}{\partial A^{\top}}=B$$
$$\frac{\partial f(A)}{\partial A^{\top}}=(\frac{\partial f(A)}{\partial A})^{\top}$$
然后是链式法则(chain rule):
$$\frac{\partial \textbf z}{\partial \textbf x}=\frac{\partial \textbf y}{\partial \textbf x}\frac{\partial \textbf z}{\partial \textbf y}$$
$$\frac{\partial z}{\partial X_{ij}}=(\frac{\partial z}{\partial\textbf y})^{\top}\frac{\partial\textbf y}{\partial X_{ij}}$$
$$\frac{\partial z}{\partial X_{ij}}=\text{tr}\biggl((\frac{\partial z}{\partial Y})^{\top}\frac{\partial Y}{\partial X_{ij}}\biggr)$$
以及逐元素计算的函数 $f$ (其导函数为 $f‘$ )及其梯度:
$$\frac{\partial f(\textbf x)}{\partial\textbf x}=\text{diag}(f‘(\textbf x))$$
这里需要声明一点,上面这套计算体系里,都是使用的分母布局,也就是说:维度为 $p$ 的列向量对维度为 $q$ 的列向量求导后得到的矩阵维数为 $q\times p$ 。
关于矩阵求导,可以参见[3]。
又墨迹了半天,下面开始求 $\dfrac{\partial \mathcal L}{\partial W^{(l)}}$ 、$\dfrac{\partial \mathcal L}{\partial \textbf b^{(l)}}$ 。
根据链式法则,
$$\frac{\partial\mathcal L}{\partial W_{ij}^{(l)}}=(\frac{\partial\mathcal L}{\partial \textbf z^{(l)}})^{\top}\frac{\partial \textbf z^{(l)}}{\partial W_{ij}^{(l)}}$$
现在定义误差项 $\delta^{(l)}=\dfrac{\partial\mathcal L}{\partial \textbf z^{(l)}}\in\mathbb R^{n^l}$ ,用来表征第 $l$ 层的神经元对于误差的敏感程度。现在先求 $\frac{\partial \textbf z^{(l)}}{\partial W_{ij}^{(l)}}$ :
$$\frac{\partial \textbf z^{(l)}}{\partial W_{ij}^{(l)}}=\frac{\partial W^{(l)}\textbf a^{(l-1)}}{\partial W_{ij}^{(l)}}=(0,...,a_j^{(l-1)},...,0)^{\top}$$
其中只有第 $i$ 行的元素非零。既然这样,那么
$$\frac{\partial\mathcal L}{\partial W_{ij}^{(l)}}=\delta_i^{(l)}a_j^{(l-1)}$$
从这个式子可以看出,如果神经元的输出值 $a_j^{(l-1)}$ 很小,那么它连向下一层的权重 $W_{ij}^{(l)}$ 的更新就会很缓慢。
写成矩阵的形式,就是下面的式子:
$$\frac{\partial\mathcal L}{\partial W^{(l)}}=\delta^{(l)}(\textbf a^{(l-1)})^{\top}$$
$$\frac{\partial\mathcal L}{\partial \textbf b^{(l)}}=\delta^{(l)}$$
下面的问题就是如何计算误差项 $\delta^{(l)}$ 。对于误差项的计算,需要分两种情况考虑,一种情况是输出层,另一种情况是隐层。
对于输出层来说,
$$\begin{aligned}\delta^{(L)}&=\frac{\partial \mathcal L}{\partial \textbf z^{(L)}}\\&=\frac{\partial \textbf a^{(L)}}{\partial \textbf z^{(L)}}\frac{\partial \mathcal L}{\partial \textbf a^{(L)}}\\&=\text{diag}(f_L‘(\textbf z^{(L)}))\frac{\partial \mathcal L}{\partial \textbf a^{(L)}}\\&=f_L‘(\textbf z^{(L)})\odot \frac{\partial \mathcal L}{\partial \textbf a^{(L)}}\end{aligned}$$
对于隐层来说,
$$\begin{aligned}\delta^{(l)}&=\frac{\partial \mathcal L}{\partial \textbf z^{(l)}}\\&=\frac{\partial \textbf a^{(l)}}{\partial \textbf z^{(l)}}\frac{\partial\textbf z^{(l+1)}}{\partial \textbf a^{(l)}}\frac{\partial \mathcal L}{\partial \textbf z^{(l+1)}}\\&=\text{diag}(f_l‘(\textbf z^{(l)}))(W^{(l+1)})^{\top}\delta^{(l+1)}\\&=f_l‘(\textbf z^{(l)})\odot \bigl((W^{(l+1)})^{\top}\delta^{(l+1)}\bigr)\end{aligned}$$
从这个式子就可以看出,误差项可以逐层往输入的方向传递,这就是所谓的误差反向传播。
多提一句,这里出现了激活函数的导函数。有以下两个常用关系:
$$\sigma‘(\cdot)=\sigma(\cdot)\odot (1-\sigma(\cdot))$$
$$\text{softmax}‘(\cdot)=\text{softmax}(\cdot)\odot (1-\text{softmax}(\cdot))$$
其中 $\sigma(\cdot)$ 代表logistic函数。
所以,BP算法归结到最后其实只有四个式子比较重要:
$$\delta^{(L)}=f_L‘(\textbf z^{(L)})\odot \frac{\partial \mathcal L}{\partial \textbf a^{(L)}}$$
$$\delta^{(l)}=f_l‘(\textbf z^{(l)})\odot \bigl((W^{(l+1)})^{\top}\delta^{(l+1)}\bigr)$$
$$\frac{\partial \mathcal L}{\partial W^{(l)}}=\delta^{(l)}(\textbf a^{(l-1)})^{\top}$$
$$\frac{\partial \mathcal L}{\partial \textbf b^{(l)}}=\delta^{(l)}$$
我也用标量的形式推导过,过程如下……

无论标量形式还是矩阵形式,关键就是一点 —— chain rule。
实际举例
上面四个式子只是形式化地给出了反向传播算法的梯度形式。下面求取:对于分类问题,也就是 $f_L(\cdot)=\text{softmax}(\cdot)$ ,并且使用交叉熵损失函数 $\mathcal L(\textbf y,f(\textbf x;W,\textbf b))=-\textbf y^{\top}\log\hat{\textbf y}$ 时,$\delta^{(L)}=\dfrac{\partial \mathcal L}{\partial \textbf z^{(L)}}$ 到底是个什么形式。
其实到这里问题已经很清楚了:这和Softmax回归模型是一样一样的,这里的 $\delta^{(L)}$ 在Softmax回归模型的求梯度过程中是一个中间结果。下面是基于文章[2]所给方法的完整求解过程。为了简洁起见,所有的 $\textbf z^{(L)}$ 都记作 $\textbf z$:
文章[2]介绍的是这样形式的求导:已知矩阵 $X$ ,函数 $f(X)$ 的函数值为标量,求 $\dfrac{\partial f}{\partial X}$ 。一种典型的例子就是求取损失对权重矩阵的导数。
对于一元微积分,$\text{d}f=f‘(x)\text{d}x$ ;多元微积分,$\text{d}f=\sum_i\dfrac{\partial f}{\partial x_i}\text{d}x_i=(\dfrac{\partial f}{\partial \textbf x})^{\top}\text{d}\textbf x$;由此建立矩阵导数和微分的联系:
$$\text{d}f=\sum_{i,j}\frac{\partial f}{\partial X_{ij}}\text{d}X_{ij}=\text{tr}((\frac{\partial f}{\partial X})^{\top}\text{d}X)$$
上式第二个等号成立是因为对于两个同阶方阵有 $\text{tr}(A^{\top}B)=\sum_{i,j}A_{ij}B_{ij}$ 。求解的流程就是,先求微分 $\text{d}f$ 表达式,然后再套上迹(因为标量的迹等于标量本身),然后再把表达式 $\text{tr}(\text{d}f)$ 和 $\text{tr}((\dfrac{\partial f}{\partial X})^{\top}\text{d}X)$ 进行比对,进而把 $\dfrac{\partial f}{\partial X}$ 给“挖”出来。
所以,问题就从求梯度转化成了求微分。求微分当然少不了很多法则和技巧,下面随着讲随着介绍。
首先求取 $\text{d} \mathcal L$ 。
$$\begin{aligned} \mathcal L&=-\textbf y^{\top}\ln\frac{\exp(\textbf z)}{\textbf 1^{\top}\exp(\textbf z)}\\&=-\textbf y^{\top}(\textbf z-\ln\begin{pmatrix}\textbf 1^{\top}\exp(\textbf z) \\ \textbf 1^{\top}\exp(\textbf z) \\ \vdots \\ \textbf 1^{\top}\exp(\textbf z)\end{pmatrix})\quad \textbf 1^{\top}\exp(\textbf z)\text{是标量}\\&=\ln(\textbf 1^{\top}\exp(\textbf z))-\textbf y^{\top}\textbf z\end{aligned}$$
根据法则 $\text{d}(g(X))=g‘(X)\odot\text{d}X$ 、$\text{d}(XY)=(\text{d}X)Y+X(\text{d}Y)$,可得
$$\text{d}(\ln(\textbf 1^{\top}\exp(\textbf z)))=\frac{1}{\textbf 1^{\top}\exp(\textbf z)}\odot\text{d}(\textbf 1^{\top}\exp(\textbf z))$$
$$\text{d}(\textbf 1^{\top}\exp(\textbf z))=\textbf 1^{\top}\text{d}(\exp(\textbf z))=\textbf 1^{\top}\odot (\exp(\textbf z)\text{d}\textbf z)$$
所以
$$\text{d} \mathcal L=\frac{\textbf 1^{\top}\odot (\exp(\textbf z)\text{d}\textbf z)}{\textbf 1^{\top}\exp(\textbf z)}-\textbf y^{\top}\text{d}\textbf z$$
现在可以套上迹,根据恒等式 $\text{tr}(A^{\top}(B\odot C))=\text{tr}((A\odot B)^{\top}C)=\sum_{i,j}A_{ij}B_{ij}C_{ij}$ ,可得
$$\begin{aligned}\text{d} \mathcal L&=\text{tr}(\frac{(\textbf 1\odot \exp(\textbf z))^{\top}\text{d}\textbf z}{\textbf 1^{\top}\exp(\textbf z)})-\text{tr}(\textbf y^{\top}\text{d}\textbf z)\\&=\text{tr}(\biggl(\frac{(\exp(\textbf z))^{\top}}{\textbf 1^{\top}\exp(\textbf z)}-\textbf y^{\top}\biggr)\text{d}\textbf z)\\&=\text{tr}((\hat{\textbf y}-\textbf y)^{\top}\text{d}\textbf z)\\&=\text{tr}((\frac{\partial\mathcal L}{\partial\textbf z})^{\top}\text{d}\textbf z)\end{aligned}$$
这样就得到了 $\delta^{(L)}$ 的形式:
$$\delta^{(L)}=\frac{\partial \mathcal L}{\partial \textbf z^{(L)}}=\hat{\textbf y}-\textbf y$$
这样就不难看出为什么将 $\delta^{(l)}$ 称为误差项了。
参考资料:
[1] 《神经网络与深度学习讲义》
[2] 《矩阵求导术(上)》
[3] Matrix_calculus
DL4NLP——神经网络(一)前馈神经网络的BP反向传播算法步骤整理
标签:strong 建立 tps 权重 神经网络 lock 等于 技术 span
原文地址:http://www.cnblogs.com/Determined22/p/6562546.html