标签:简介 理解 引入 about padding library 间接 关系型数据库 执行
最近我在用图形数据库来完成对一个初创项目的支持。在使用过程中觉得这种图形数据库实际上挺有意思的。因此在这里给大家做一个简单的介绍。
NoSQL数据库相信大家都听说过。它们常常可以用来处理传统的关系型数据库所难以解决的一系列问题。通常情况下,这些NoSQL数据库分为Graph,Document,Column Family以及Key-Value Store等四种。这四种类型的数据库分别使用了不同的数据结构来记录数据。因此它们所适用的场景也不尽相同。
其中最为特别的便是图形数据库了。可以说,它和其它的一系列NoSQL数据库非常不同:丰富的关系表示,完整的事务支持,却没有一个纯正的横向扩展解决方案。
在本文中,我们就将对业界非常流行的图形数据库Neo4J进行简单的介绍。
图形数据库简介
相信您和我一样,在使用关系型数据库时常常会遇到一系列非常复杂的设计问题。例如一部电影中的各个演员常常有主角配角之分,还要有导演,特效等人员的参与。通常情况下这些人员常常都被抽象为Person类型,对应着同一个数据库表。同时一位导演本身也可以是其它电影或者电视剧的演员,更可能是歌手,甚至是某些影视公司的投资者(没错,我这个例子的确是以赵薇为模板的)。而这些影视公司则常常是一系列电影,电视剧的资方。这种彼此关联的关系常常会非常复杂,而且在两个实体之间常常同时存在着多个不同的关系:

在尝试使用关系型数据库对这些关系进行建模时,我们首先需要建立表示各种实体的一系列表:表示人的表,表示电影的表,表示电视剧的表,表示影视公司的表等等。这些表常常需要通过一系列关联表将它们关联起来:通过这些关联表来记录一个人到底参演过哪些电影,参演过哪些电视剧,唱过哪些歌,同时又是哪些公司的投资方。同时我们还需要创建一系列关联表来记录一部电影中哪些人是主角,哪些人是配角,哪个人是导演,哪些人是特效等。可以看到,我们需要大量的关联表来记录这一系列复杂的关系。在更多实体引入之后,我们将需要越来越多的关联表,从而使得基于关系型数据库的解决方案繁琐易错。
这一切的症结主要在于关系型数据库是以为实体建模这一基础理念设计的。该设计理念并没有提供对这些实体间关系的直接支持。在需要描述这些实体之间的关系时,我们常常需要创建一个关联表以记录这些数据之间的关联关系,而且这些关联表常常不用来记录除外键之外的其它数据。也就是说,这些关联表也仅仅是通过关系型数据库所已有的功能来模拟实体之间的关系。这种模拟导致了两个非常糟糕的结果:数据库需要通过关联表间接地维护实体间的关系,导致数据库的执行效能低下;同时关联表的数量急剧上升。
这种执行效能到底低下到什么程度呢?就以建立人和电影之间的投资关系为例。一个使用关联表的设计常常如下所示:
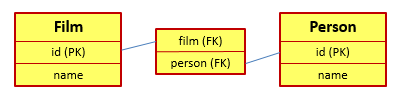
如果现在我们想要通过该关系找到一部电影的所有投资人,关系型数据库常常会执行哪些操作呢?首先,在关联表中执行一个Table Scan操作(假设没有得到索引支持),以找到所有film域的值与目标电影id相匹配的记录。接下来,通过这些记录中的person域所记录的Person的主键值来从Person表中找到相应的记录。如果记录较少,那么这步就会使用Clustered Index Seek操作(假设是使用该运算符)。整个操作的时间复杂度将变为O(nlogn):
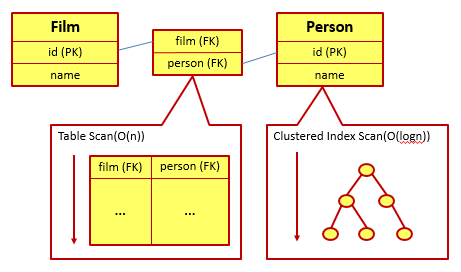
可以看到,通过关联表组织的关系在运行时的性能并不是很好。如果我们所需要操作的数据集包含了非常多的关系,而且主要是在对这些关系进行操作,那么可以想象到关系数据库的性能将变得有多差。
除了性能之外,关联表数量的管理也是一个非常让人头疼的问题。刚刚我们仅仅是举了一个具有四个实体的例子:人,电影,电视剧,影视公司。现实生活中的例子可不是这么简单。在一些场景下,我们常常需要对更多的实体进行建模,从而完整地描述某一领域内的关联关系。这种关联关系所涵盖的可能包含影视公司的控股关系,各控股公司之间复杂的持股关系以及各公司之间的借贷款情况及担保关系等,更可能是人之间的关系,人与各个品牌之间的代言关系,各个品牌与所属公司之间的关系等。
可以看到,在需要描述大量关系时,传统的关系型数据库已经不堪重负。它所能承担的是较多实体但是实体间关系略显简单的情况。而对于这种实体间关系非常复杂,常常需要在关系之中记录数据,而且大部分对数据的操作都与关系有关的情况,原生支持了关系的图形数据库才是正确的选择。它不仅仅可以为我们带来运行性能的提升,更可以大大提高系统开发效率,减少维护成本。
在一个图形数据库中,数据库的最主要组成主要有两种,结点集和连接结点的关系。结点集就是图中一系列结点的集合,比较接近于关系数据库中所最常使用的表。而关系则是图形数据库所特有的组成。因此对于一个习惯于使用关系型数据库开发的人而言,如何正确地理解关系则是正确使用图形数据库的关键。
但是不用担心,在了解了图形数据库对数据进行抽象的方式之后,您就会觉得这些数据抽象方式实际上和关系型数据库还是非常接近的。简单地说,每个结点仍具有标示自己所属实体类型的标签,也既是其所属的结点集,并记录一系列描述该结点特性的属性。除此之外,我们还可以通过关系来连接各个结点。因此各个结点集的抽象实际上与关系型数据库中的各个表的抽象还是有些类似的:

但是在表示关系的时候,关系型数据库和图形数据库就有很大的不同了:
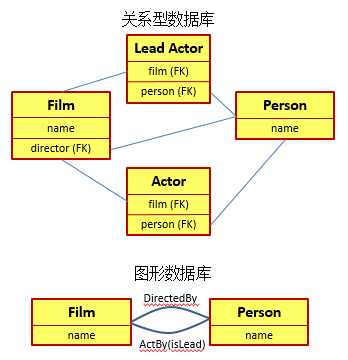
从上图中可以看到,在需要表示多对多关系时,我们常常需要创建一个关联表来记录不同实体的多对多关系,而且这些关联表常常不用来记录信息。如果两个实体之间拥有多种关系,那么我们就需要在它们之间创建多个关联表。而在一个图形数据库中,我们只需要标明两者之间存在着不同的关系,例如用DirectBy关系指向电影的导演,或用ActBy关系来指定参与电影拍摄的各个演员。同时在ActBy关系中,我们更可以通过关系中的属性来表示其是否是该电影的主演。而且从上面所展示的关系的名称上可以看出,关系是有向的。如果希望在两个结点集间建立双向关系,我们就需要为每个方向定义一个关系。
也就是说,相对于关系数据库中的各种关联表,图形数据库中的关系可以通过关系能够包含属性这一功能来提供更为丰富的关系展现方式。因此相较于关系型数据库,图形数据库的用户在对事物进行抽象时将拥有一个额外的武器,那就是丰富的关系:

因此在为图形数据库定义数据展现时,我们应该以一种更为自然的方式来对这些需要展现的事物进行抽象:首先为这些事物定义其所对应的结点集,并定义该结点集所具有的各个属性。接下来辨识出它们之间的关系并创建这些关系的相应抽象。
因此一个图形数据库中所承载的数据最终将有类似于下图所示的结构:

设计一个优质的图
在了解了图形数据库的基础知识之后,我们就要开始尝试使用图形数据库了。首先我们要搞清楚一个问题,那就是如何为我们的图形数据库定义一个设计良好的图?实际上这并不困难,您只需要了解图数据库设计时所使用的一系列要点即可。
首先就是,分清图中结点集,结点以及关系之间的相互联系。在以往的基于关系型数据库的设计中,我们常常会使用一个表来抽象一类事物。如对于人这个概念,我们常常会抽象出一个表,并在表中添加表示两个人的记录,Alice和Bob:

而在图数据库中,这里对应着两个概念:结点集和结点。在通常情况下,图形数据库中的数据展示并不使用结点集,而是独立的结点:

而如果需要在图中添加对书籍的支持,那么这些书籍将仍然被表示为一个结点:

也就是说,虽然在一个图数据库中常常拥有结点集的概念,但是它已经不再作为图数据库的最重要抽象方式了。甚至从某些图形数据库已经允许软件开发人员使用Schemaless结点这一点上来看,它们已经将结点集的概念弱化了。反过来,我们思考的角度就应该是结点个体,以及这些个体之间所存在的一系列关系。
那么我们是不是可以随便定义各个结点所具有的数据呢?不是的。这里最为常用的一个准则就是:Schemaless这种灵活度能为你带来好处。例如相较于强类型语言,弱类型语言可以为软件开发人员带来更大的开发灵活度,但是其维护性和严谨性常常不如强类型语言。同样地,在使用Schemaless结点时也要兼顾灵活性和维护性。
这样我们就可以在结点中添加多种多样的关系,而不用像在关系型数据库中那样需要担心是否需要通过更改数据库的Schema来记录一些外键。这进而允许软件开发人员在各结点间添加多种多样的关系:
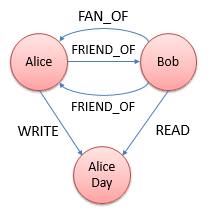
因此在一个图形数据库中,结点集这个概念已经不是最重要的那一类概念了。例如在某些图形数据库中,各个结点的ID并不是按照结点集来组织的,而是根据结点的创建顺序来赋予的。在调试时您可能会发现,某个结点集内的第一个结点的ID是1,第二个结点的ID就是3了。而具有2这个ID的结点则处于另一个结点集中。
那么我们应该如何为业务逻辑定义一个合适的图呢?简单地说,单一事物应该被抽象为一个结点,而同一类型的结点被记录在同一个结点集中。结点集内各结点所包含的数据可能有一些不同,如一个人可能有不同的职责并由此通过不同的关系和其它结点关联。例如一个人既可能是演员,可能是导演,也可能是演员兼导演。在关系型数据库中,我们可能需要为演员和导演建立不同的表。而在图形数据库中,这三种类型的人都是人这个结点集内的数据,而不同的仅仅是它们通过不同的关系连接到不同的结点上了而已。也就是说,在图形数据库中,结点集并不会像关系型数据库中的表一样粒度那么小。
一旦抽象出了各个结点集,我们就需要找出这些结点之间所可能拥有的关系。这些关系不仅仅是跨结点集的。有时候,这些关系是同一结点集内的结点之间的关系,甚至是同一结点指向自身的关系:
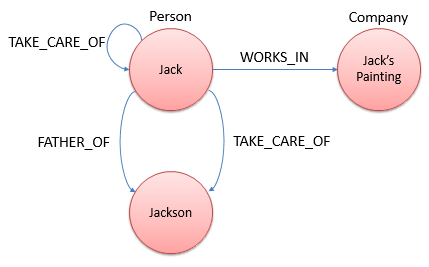
这些关系通常都具有一个起点和终点。也就是说,图形数据库中的关系常常是有向的。如果希望在两个结点之间创建一个相互关系,如Alice和Bob彼此相识,我们就需要在他们之间创建两个KNOW_ABOUT关系。其中一个关系由Alice指向Bob,而另一个关系则由Bob指向Alice:
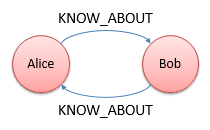
需要注意的一点就是,虽然说图形数据库中的关系是单向的,但是在一些图形数据库的实现中,如Neo4J,我们不仅仅可以查找到从某个结点所发出的关系,也可以找到指向某个结点的各个关系。也就是说,虽然图中的关系是单向的,但是关系在起点和终点都可以被查找到。
标签:简介 理解 引入 about padding library 间接 关系型数据库 执行
原文地址:http://blog.csdn.net/oeljeklaus/article/details/63685697