标签:.com 通用 框架 ssi 梯度 时间 blog png bsp
机器学习算法可以说是不少的,如果死记硬背的话,只能当时记得推导过程和步骤,过一段时间就又想不起来了,只能依稀记得一些影子。所以,应该找到算法的一些通用的方法来理解算法的思路以及推导过程。
我认为,最大似然估计和损失函数,就是机器学习算法的通用框架,是掌握机器学习算法的钥匙。
以下,用实际算法来证实这两把钥匙的威力。
1.Linear Regression。可以转化为求
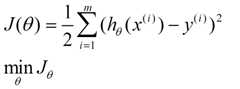
损失函数最小,来求解参数θ。
之后用梯度下降法来实际求解θ。除了梯度下降这一个工具外,还有拟牛顿法,拉格朗日乘子法重要工具。
2.Logistic Regression。有了模型
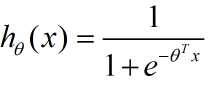
后,先求其最大似然函数:
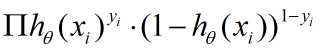
然后对这个似然函数取对数,就得到
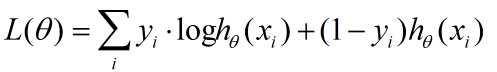
实际操作中,一般在前面加个负号,改为求最小。
3.SVM
标签:.com 通用 框架 ssi 梯度 时间 blog png bsp
原文地址:http://www.cnblogs.com/xubing-613/p/6593530.html