标签:-- images oca 基于 关系 map span eve bsp
转载请标明出处http://www.cnblogs.com/haozhengfei/p/82c3ef86303321055eb10f7e100eb84b.html
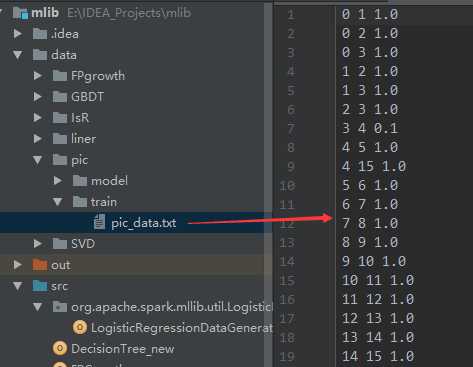

1 import org.apache.log4j.{Level, Logger} 2 import org.apache.spark.rdd.RDD 3 import org.apache.spark.{SparkConf, SparkContext} 4 import org.apache.spark.mllib.clustering.PowerIterationClustering 5 6 /** 7 * Created by hzf 8 */ 9 object PowerIterationClustering_new { 10 // E:\IDEA_Projects\mlib\data\pic\train\pic_data.txt E:\IDEA_Projects\mlib\data\pic\model 3 20 local 11 def main(args: Array[String]) { 12 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) 13 if (args.length < 5) { 14 System.err.println("Usage: PIC <inputPath> <modelPath> <K> <iterations> <master> [<AppName>]") 15 System.exit(1) 16 } 17 val appName = if (args.length > 5) args(5) else "PIC" 18 val conf = new SparkConf().setAppName(appName).setMaster(args(4)) 19 val sc = new SparkContext(conf) 20 val data: RDD[(Long, Long, Double)] = sc.textFile(args(0)).map(line => { 21 val parts = line.split(" ").map(_.toDouble) 22 (parts(0).toLong, parts(1).toLong, parts(2)) 23 }) 24 25 val pic = new PowerIterationClustering() 26 .setK(args(2).toInt) 27 .setMaxIterations(args(3).toInt) 28 val model = pic.run(data) 29 30 model.assignments.foreach { a => 31 println(s"${a.id} -> ${a.cluster}") 32 } 33 model.save(sc, args(1)) 34 } 35 }
E:\IDEA_Projects\mlib\data\pic\train\pic_data.txt E:\IDEA_Projects\mlib\data\pic\model 320 local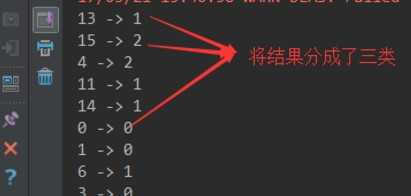
标签:-- images oca 基于 关系 map span eve bsp
原文地址:http://www.cnblogs.com/haozhengfei/p/82c3ef86303321055eb10f7e100eb84b.html
