标签:定向 哪些 str end sea utf-8 head 保留 handle
原文链接:
http://blog.csdn.net/tangxiaolang101/article/details/54670218
写在前面的话,这是一篇译文,阅读资料时顺带整理翻译的,原文地址:http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/
作为一个程序员,你应该对web应用是如何工作的有一个高水平的认识,它工作过程都包含了哪些技术:浏览器、HTTP、HTML、web server、 request handlers等等。
这篇文章,我们将会对当你访问一个URL时所发生的一系列事情进行深入的探讨。
当然,这是最点单的一个,例如:facebook.conm

浏览的第一步就是为访问域名计算出IP地址。DNS查找过程如下:
.com查找顶级域名服务器,然后再到 Facebook 的域名服务器。通常来说,DNS服务器都会有.com域名服务器的缓存,所以根域名服务器不是必须的。下面是一个DNS循环查找的图表: 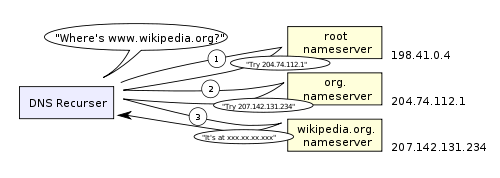
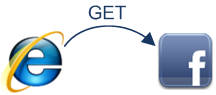
你可以确定 Facebook 的页面不是从浏览器缓存中取到的,因为动态页面会很快就过期失效的(把过期时间设置在过去)。
所以,浏览器将会向 Facebook 的服务器发送一个请求:
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]GET 关键字表示请求获取: http://facebook.com/。浏览器的自我标识(User-Agent),和请求接受什么类型的响应。(Accept和Accept-Encoding)。Connection关键字请求服务器保持TCP链接。
请求也会包含这个域名下的cookies。
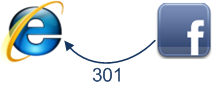
这是 Facebook 返回浏览器请求的响应:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0服务器响应通过301 Moved Permanently告诉浏览器访问 http://www.facebook.com/来代替http://facebook.com/.
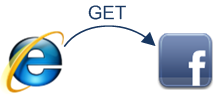 浏览器现在知道
浏览器现在知道http://www.facebook.com/是正确的URL地址,然后向这个地址发送了另一个GET请求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com请求头和上面的基本相同。
 服务器将会接收GET请求,然后处理它,并且对它做出响应。
服务器将会接收GET请求,然后处理它,并且对它做出响应。
这看起来是个简单的任务,实际上这里会发生许多有趣的事情,即使是访问像我博客这样简单的网站,更不用说像 Facebook 这样的大型网站了。
这是服务器返回的响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3
????????T?n?@????[...]整个响应是36KB。Content-Encoding关键字告诉了浏览器响应主体内容是通过 gzip 方式进行压缩的。通过解压后,就可以看到你期盼已久的HTML了。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"
lang="en" id="facebook" class=" no_js">
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-language" content="en" />处理压缩方式外,响应头还指定了是否缓存页面,通过哪种方式缓存,cookies如何设置,隐私数据如何处理等等信息。
在浏览器接收整个 HTML 文档之前,网站已经开始渲染了。
浏览器渲染HTML时,会注意的哪些需要发起请求的标准。然后发送GET请求为它们获取文件。
下面是我访问 Facebook ,浏览器做的请求:
每个请求都会和请求HTML页面一样,走相似的流程。所以,浏览器会在DNS中查找域名,发送请求URL,重定向等等。
当然,静态文件是可以让浏览器缓存的。一些文件可以直接从缓存中获得,不用连接服务器。浏览器知道这些特有文件缓存多长时间,因为响应头的Expires关键字设置了这个文件的有效期。除此之外,每一个响应可能也会保留一个ETag头,它就像版本号一样。如果浏览器发现这个文件的ETag号已经存在了,它可以立即停止请求。
AJAX请求 在 web2.0 的时代,客户端可以在页面渲染完成之后继续和服务器进行交互。
在 web2.0 的时代,客户端可以在页面渲染完成之后继续和服务器进行交互。
例如,当你的好友登录或登出时,Facebook聊天会持续更新你的在线好友列表。为了更新你的在线好友列表, JavaScript 已经向服务器发送了 AJAX 请求了。
到此,当你访问一个URL时会发生什么基本到涉及到了,当然,里面的技术详细来讲还有太多太多了,比如:DNS服务器解析来做高并发、负载均衡,AJAX异步请求等等。但是,因为这些都不是这篇文章的主题,就不再补充了,以后遇到相关好的文章可以再翻译了哈!
前端:从 URL 输入到页面展现发生了什么?(What really happens when you navigate to a URL)
标签:定向 哪些 str end sea utf-8 head 保留 handle
原文地址:http://www.cnblogs.com/ltchu/p/6601702.html