标签:font sql优化 哪些 sel 转换 _id user 基于 集合
子查询是指在查询语句中嵌套另一个查询语句。
子查询外面的查询部分被称为外部查询。
子查询必须包含括号。
any、in、some
any关键字必须与一个比较操作符一起使用,它的意思是“与子查询中返回列的数值进行逐一对比,只要其中一个数值比较为true,则返回true”,我们来看一个查询实例,
select id_temp from t_user_collect where commodity_id > any (select id from t_commodity); 得到如下结果,
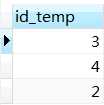
我们通过查看两张表的数据,来分析下为什么会得到以上结果,t_user_collect表的数据如下,

t_commodity表的数据如下,
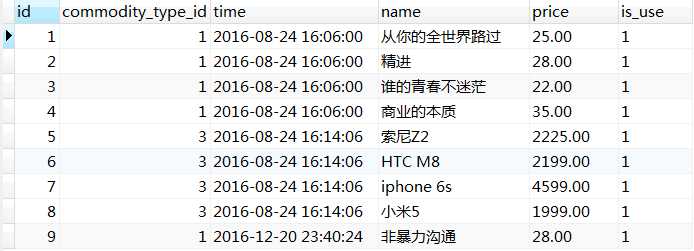
首先我们已经明确了any关键字的含义,t_user_collect表中commodity_id列会与t_commodity表中id列的数值进行逐一对比,只要commodity_id大于其中的一个id,则commodity_id列值所在行的id_temp列值就会被查询出来。
从表中数据能够看出,commodity_id列中为1的值是无法大于id列中任何一个值的,因此其(这里是指commodity_id列)所在行的id_temp列值不会被查询出来,而其它的commodity_id列值(6、3、4)在id列中均能找到大于的值,所以它们(这里是指commodity_id列)关联的id_temp列值会被查询出来。
in关键字的含义是“只返回包含这些值的记录”,它等价于“= any”,因此以下两个SQL是等价的,
select id_temp from t_user_collect where commodity_id = any (select id from t_commodity);
select id_temp from t_user_collect where commodity_id in (select id from t_commodity);
查询的结果为,
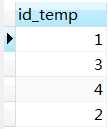
得到上述结果是因为commodity_id列中的值(1、6、3、4)在id列中均有包含。
为什么说“in”和“= any”是等价的呢,我们来分析一下,“= any”的含义是“只要等于指定值中的任何一个值就返回true”,和明显t_user_collect表中commodity_id列的值都能在t_commodity表的id列中匹配到相等的值。
some关键字和any关键字是等价的,之所以在有些条件下使用some,是为了表达“有部分不相等”的意思,因此以下SQL是等价的,
select id_temp from t_user_collect where commodity_id <> any (select id from t_commodity);
select id_temp from t_user_collect where commodity_id <> some (select id from t_commodity);
查询结果为,
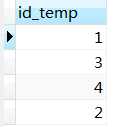
这里怎么理解,其实就是commodity_id列值与id列中值进行匹配时,只要有一个不相等,其(这里是指commodity_id列)所在行的id_temp列值就会被查询出来。
这里的“<> any”含义是“只要不等于指定值中的任何一个值就返回true”。
这里的“<> some”含义是“只要不等于指定值中的部分值就返回true”。
all
all关键字,也需要与比较操作符一起使用,其含义是“与子查询返回列中的值进行逐一对比,所有比较都为true,才返回true”,来看一个实例,
select uc.id_temp from t_user_collect uc where uc.commodity_id > all (select c.id from t_commodity c);
查询结果为,
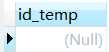
由于t_user_collect表commodity_id列的最大值为6,而t_commodity表id列的最大值为9,因此每一个commodity_id列的值都无法大于所有的id列值,故结果为Null
当我们对all使用<>符号时,是想得到那些外部查询中未包含在子查询中的数据,来看一个实例,
select uc.id_temp from t_user_collect uc where uc.commodity_id <> all (select c.id from t_commodity c);
查询结果为,
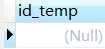
我们来理解下,只有当commodity_id列中的值不等于所有id列中的值时,其(这里是指commodity_id列)所在行的id_temp列值才会被查询出来,然而commodity_id列中的值与id列中的值均有匹配关系,因此查询出来的结果为Null。
其实<> all还有一个别名,就是not in,后者明显更易于理解,即不包含、不在里面的意思,那么对于刚刚的那个SQL就可以这么理解,“看commodity_id列中值有哪些是不在id列中的”,因此以下两个SQL是等价的,
select uc.id_temp from t_user_collect uc where uc.commodity_id <> all (select c.id from t_commodity c);
select uc.id_temp from t_user_collect uc where uc.commodity_id not in (select c.id from t_commodity c);
子查询的分类
按照期望值的数量可以将子查询分为:标量子查询、多值子查询
按照对外部查询的依赖可以将子查询分为:独立子查询、相关子查询
它们之间的关系是标量子查询和多值子查询可以是独立子查询也可以是相关子查询
标量子查询返回的是单个值,若标量子查询返回多个值,则MySQL会抛出错误提示“该子查询返回多行数据”;多值子查询返回的是多值集合。
独立子查询是不依赖于外部查询而运行的子查询。怎么理解呢,就是这个子查询可以单独运行,而不需要和外部查询有任何交互。
MySQL对于in子句的优化,如果不是显式的列表定义,如in (1,2,3,4,5),那么in子句一般都会被转换为exists子句,这一过程就是把独立子查询转换为了相关子查询。
相关子查询是指引用了外部查询列的子查询,例如下述这个SQL,
select id_temp from t_user_collect uc where exists (select * from t_commodity c where c.id=uc.commodity_id);
子查询中的“c.id=uc.commodity_id”就是引用了外部查询的commodity_id列,通过explain可以看到这个子查询的select_type是dependent subquery(相关子查询),

相关子查询会对外部查询的列进行多次比较,因此对于相关子查询的优化我们应该从减少与外部查询的多次比较入手。基于此,有时我们可以通过派生表来进行重写SQL。那么我们在确定是否需要对子查询进行优化时,可以通过使用explain来查看SQL的执行计划,不要被因数据量小导致SQL执行用时短的假象所蒙蔽,要尽可能的用大数据量去测试你的SQL。
EXISTS
用于检查指定的查询是否产生某些行,exists一般后接子查询,且子查询会关联外部查询。根据子查询是否返回行,exists仅会返回true或false,而不会出现返回unknown的情况。
通常不建议在SQL中使用*,但是在exists中我们可以这么做,这是因为exists只关心行是否存在,而不会去取各列的值。
额外知识点
“一个SQL优化建议,将语句中的in替换为exists”这句话是不是很耳熟?它是一个真理吗?可能在一些老版本的MySQL上确实是有益的,但是现阶段的MySQL对于in和exists在绝大多数情况下,两者都具有相同的执行计划,所以你会发现即便将in换成了exists效果是一样的。因此我们对于别人总结的定理,最好还是保有一颗求证的心,让事实来说服自己。
select id_temp from t_user_collect uc where commodity_id in (select id from t_commodity t);

select id_temp from t_user_collect uc where exists (select * from t_commodity t where t.id=uc.commodity_id);

派生表
派生表又被称为表子查询,这是什么意思呢,就是说派生表和其它表一样出现在from子句中。
那派生表是怎么产生的呢?它来自于子查询派生出的虚拟表。因此它是完全虚拟的,并没有被物理化地存于磁盘上。由于这个特性可能会导致对其执行explain时,需要消耗很长时间,这是因为优化器不知道这张表的信息。
它在使用上会有一些限制,
①列的名称必须是唯一的,以下这个SQL对于派生表是不支持的,
select id_temp from t_user_collect, (select id_temp as a, user_id_temp as a from t_user_collect) as t; MySQL会提示ERROR,“重复的列名”。

②在某些情况下派生表不支持使用limit,例如外部查询在使用in、all、any、some时;
③每个派生表必须有自己的别名,以下这个SQL对于MySQL会提示这个ERROR,
select id_temp from t_user_collect, (select id_temp as a, user_id_temp as a from t_user_collect);

额外知识点
子查询和派生表有什么关系?
其实两者从名称上来看就有比较大的差别,前者是一个查询语句,而后者是一张虚拟表。我们可以将子查询重写为派生表。当你确定你需要的是派生表时,那么你就应该给它起一个别名,而对于子查询,你则不需要这么做。
标签:font sql优化 哪些 sel 转换 _id user 基于 集合
原文地址:http://www.cnblogs.com/seker/p/6539656.html