标签:log pac 工具 tab 检查 ima oracle replace 文件名
如何使用Navicat等数据库开发工具进行高效开发将是未来工作的重点。Navicat一来美观而来够操作够傻瓜,使用得当其强大功能与PL SQL不相上下。今天学习就是如何在Navicat中使用数据泵进行数据导入导出。
数据泵使用前事项:想使用数据泵必须以sys或system等dba角色进行
数据导出:
1、导出前必须先创建表目录,点击“其他”--“目录”可查看当前数据库所有目录。具体如下图:
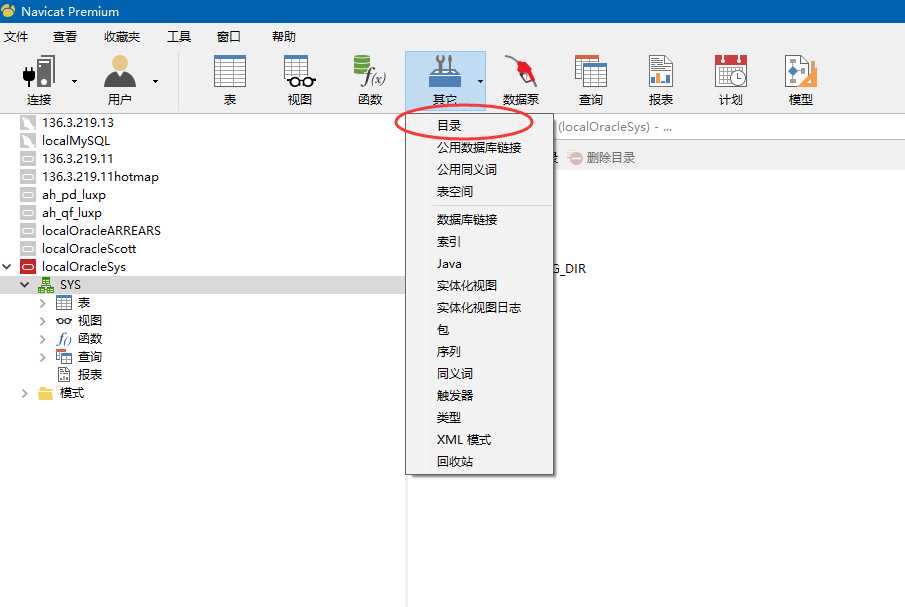
点击“新建目录”,进行目录新建,目录路径必须真实存在。路径填写完毕后点击保存即可。具体如下图:
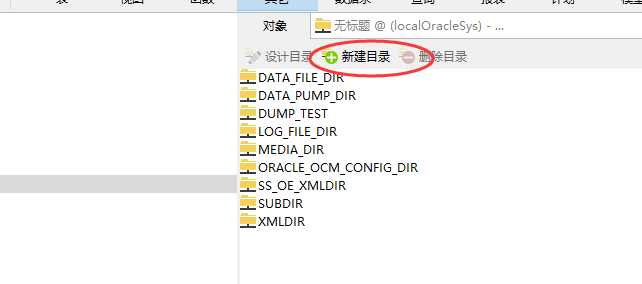
随后点击“数据泵”--“数据泵导出”进入数据泵导出界面;
接下来选择模式,按照模式(FULL--全部导出、TABLESPACE--表空间、SCHEMA--用户节点下对象集合、TABLE--表)可按相关指标导出数据;
本文的实现是以用户为单位,在导出数据下方的空白框中选择需要导出的用户对象,本例需导出的用户为ARREARS;
接下来在转储文件中,选择目录及保存的文件名,然后点击生成SQL。
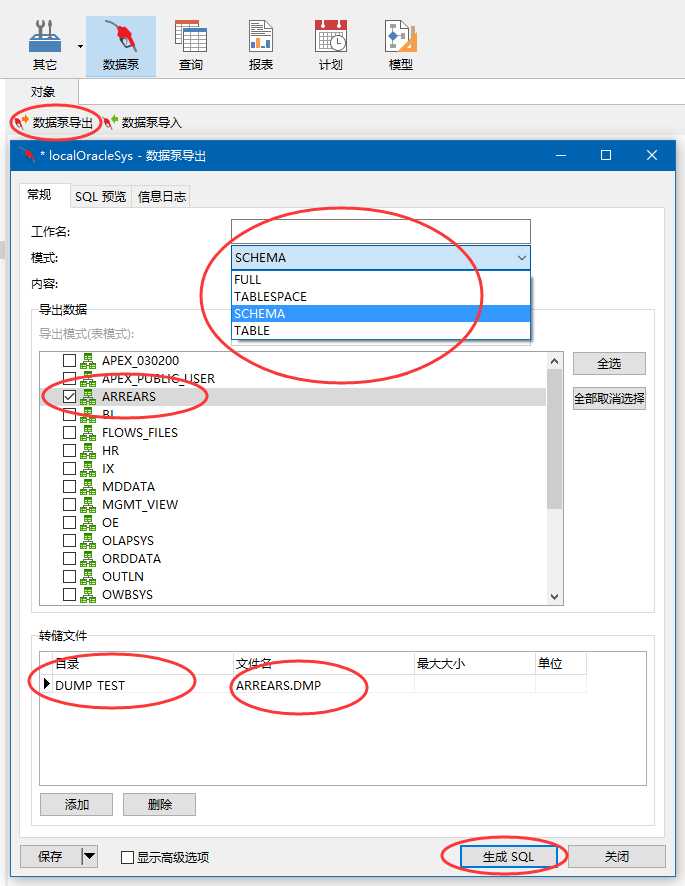
SQL预览中可以看到具体生成的SQL,确认SQL没啥问题后,点击运行(由于数据库水平有限,我是看不太出来是否有错误....惭愧...)
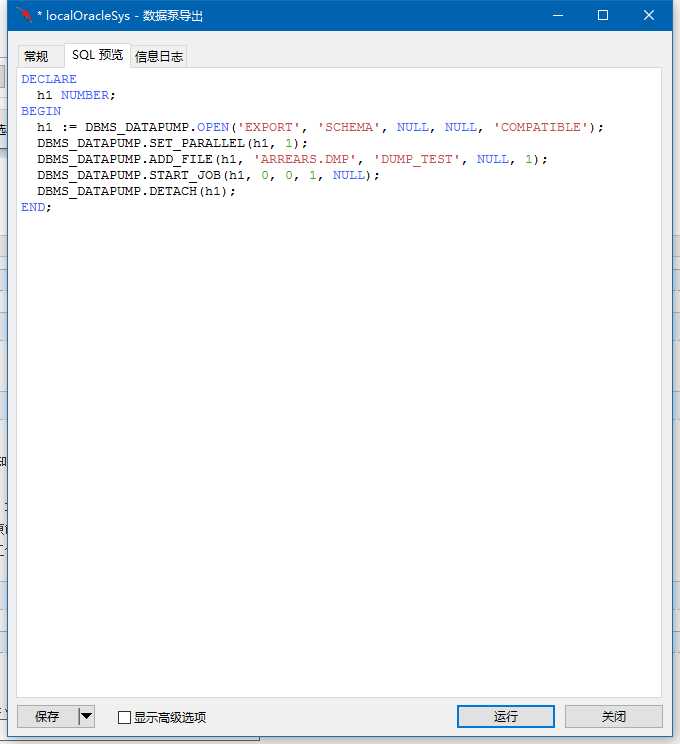
点击运行后,可看到如下运行过程:
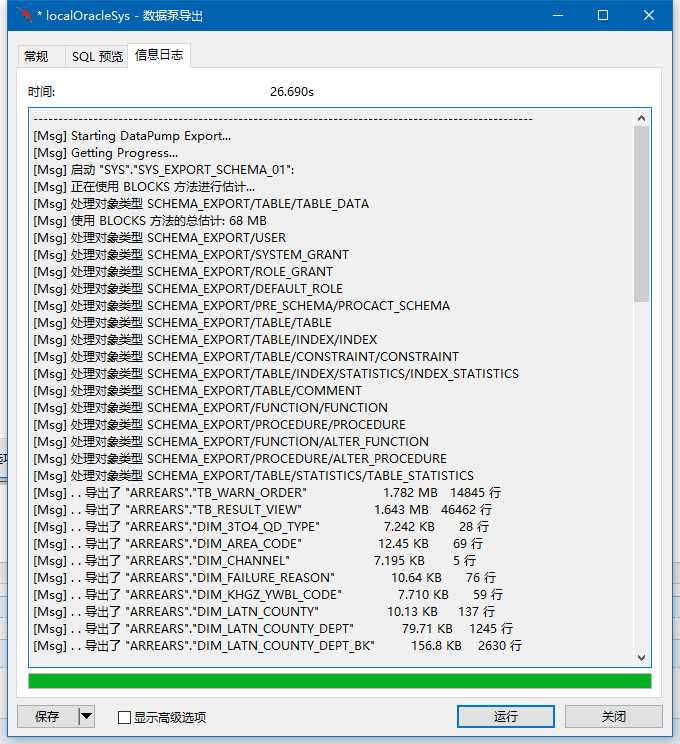
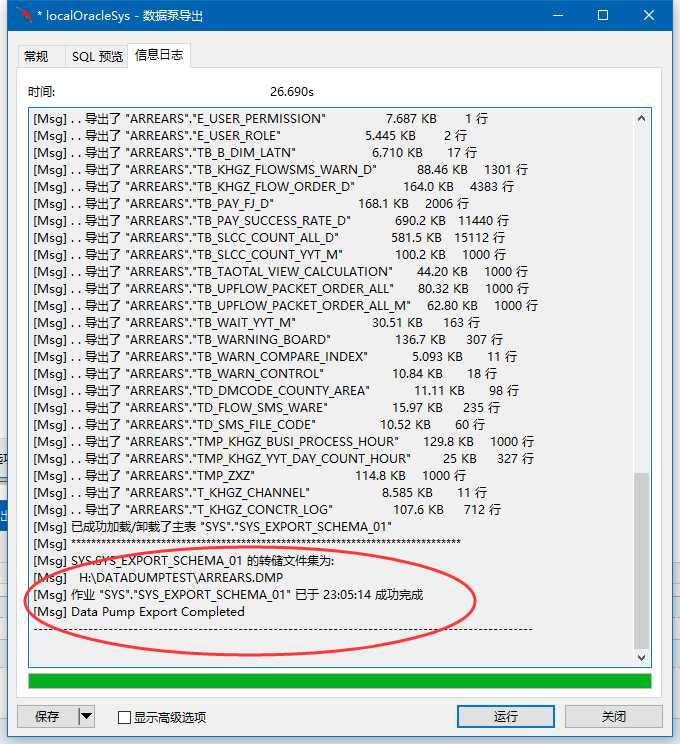
看到成功完成后表示数据导出已经完成,在对应目录中可以看到导出的DMP文件:
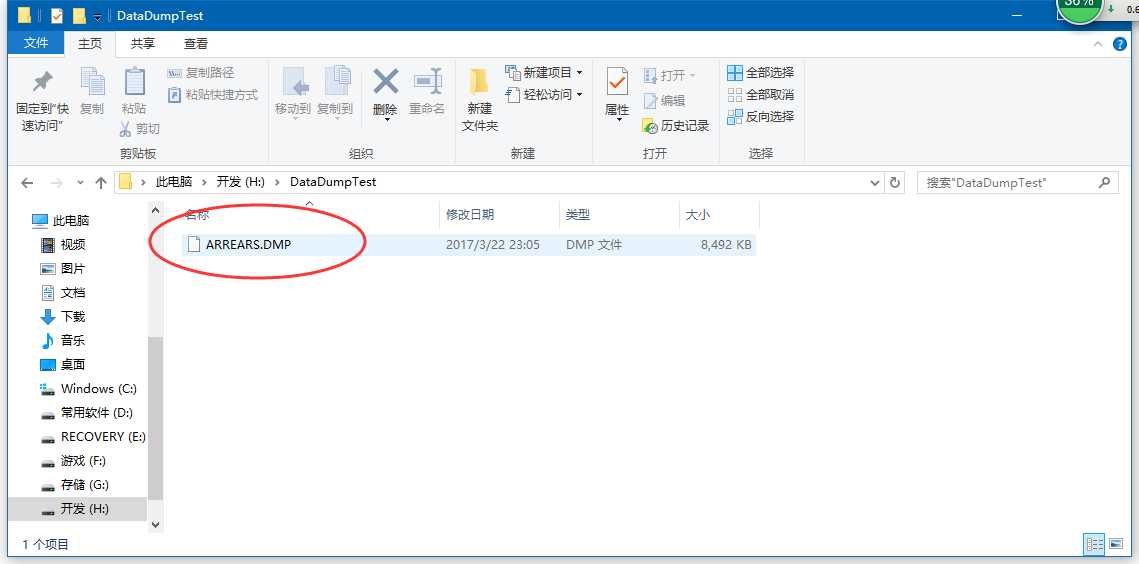
至此数据导出部分完成。
数据导入:
数据导出后下来可以进行数据导入了,话不多说继续:
点击“数据泵”--“数据泵导入”
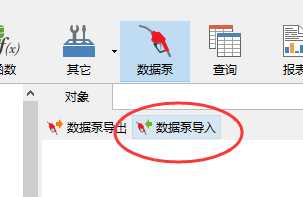
随后选择模式为“SCHEMA”(用户节点集合)
再选择 “表存在的动作”,表示的是若导入的用户下存在表名相同的表数据泵选择的操作,一共有“SKIP”--跳过、“APPEND”--追加、"TRUNCATE"--清空表、“REPLACE”--替换四种操作,
接下来在模式的输入框中输入需要将数据导入的用户节点名,此例为 ARREARS,
接下来再选择转储文件的目录和文件名(比较奇怪的是,前面导出的ARREARS.DMP文件名在可选列表中变成了ARREARS.DMP.DMP,不过好在可以修改,直接修改为实际文件名即可)
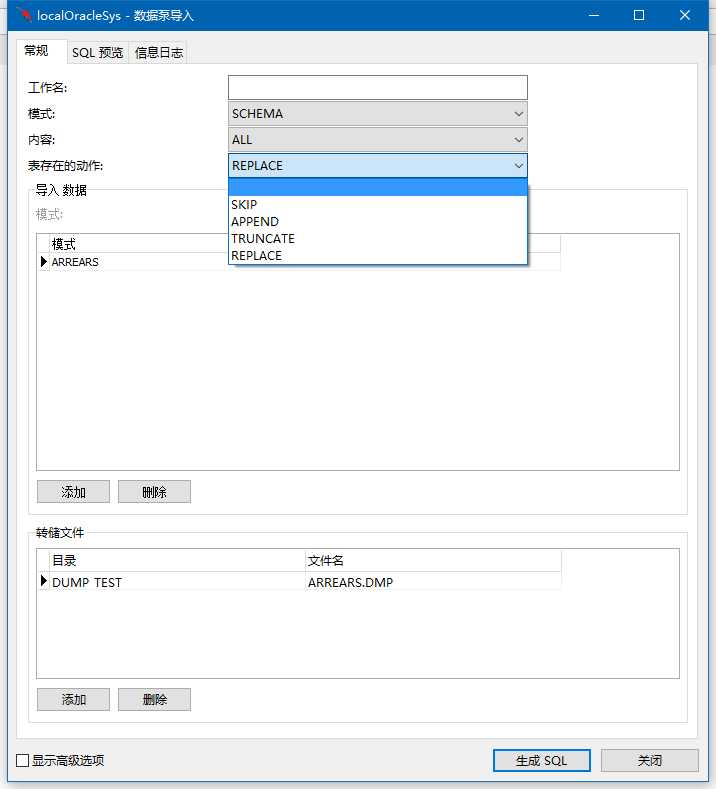
点击生成SQL后,检查SQL是否有异常:
点击运行后,看见xxxx时间运行成功说明导入完成了!
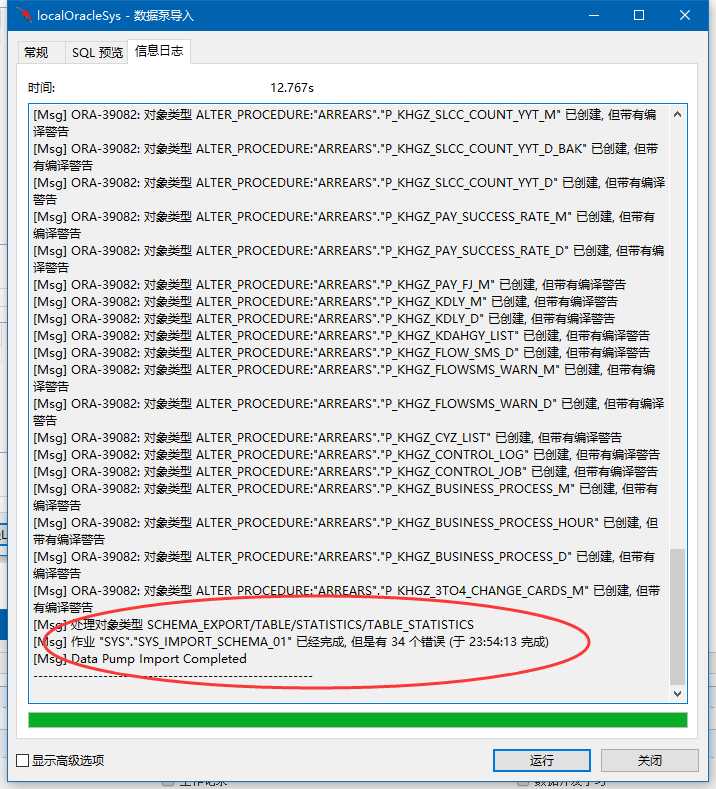
检查一下ARREARS用户下的表,都已经导进来了
标签:log pac 工具 tab 检查 ima oracle replace 文件名
原文地址:http://www.cnblogs.com/LasyisOriSin/p/6602946.html