标签:unique server esc 使用 exec 压缩 constrain 聚集 compress
前期准备:
create table Employee (
ID int not null primary key,
Name nvarchar(4),
Credit_Card_ID varbinary(max)); --- 小心这种数据类型。
go
说明:本表上的索引,都会在创建下一个索引前删除。
-------------------------------------------------------------------------------------------------------------------------------------------------------------
操作 1、
创建聚集索引
方法 1、
alter table table_name add constraint cons_name priamry key(columnName ASC|DESC,[.....]) with (drop_existing = on);
alter table Employee
add constraint PK_for_Employee primary key clustered (ID);
go
这个是一种特别的方法,因为在定义主键的时候,会自动添加索引,好在加的是聚集索引还是非聚集索引是我们人为可以控制的。
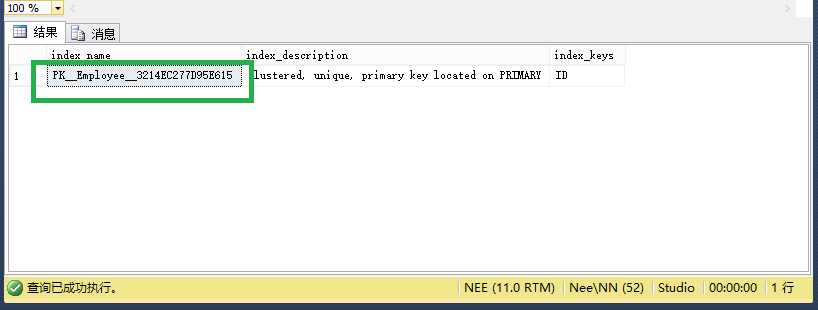
通过sp_helpindex 可以查看表中的索引
execute sp_helpindex @objname = ‘Employee‘;
go
注意、
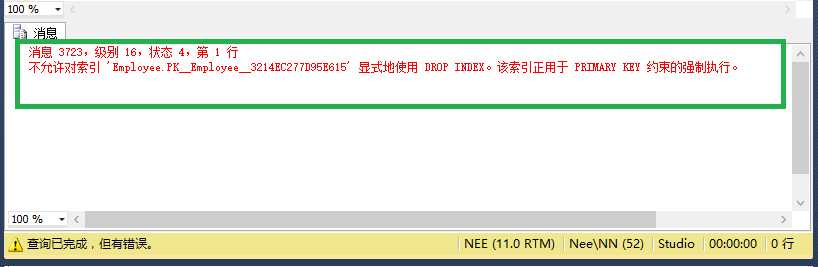
这个索引是无法删除的,不信! 你去删一下
drop index Employee.PK__Employee__3214EC277D95E615;
go
方法 2、
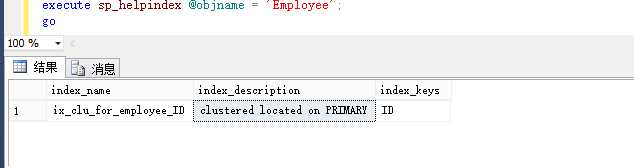
create clustered index ix_name on table_name(columnName ASC|DESC[,......]) with (drop_existing = on);方法
create clustered index ix_clu_for_employee_ID on Employee(ID);
go
查看创建的索引
操作 2、
创建复合索引
create index ix_com_Employee_IDName on Employee (ID,Name)with (drop_existing = on);
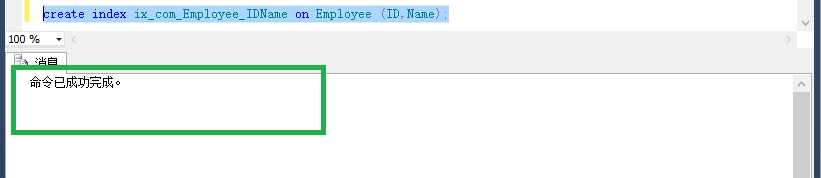
这样就算是创建一个复合索引了,不过脚下的路很长,我们看下一个复合索引的例句:
create index ix_com_Employee_IDCreditCardID on Employee(ID,Credit_Card_ID);
看到这句话,你先问一下自己它有没有错!
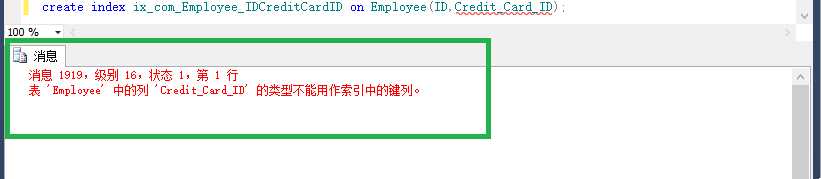
可以发现它错了,varbinary是不可以建索引的。
操作 3、
创建覆盖索引
create index index_name on table_Name (columnName ASC|DESC[,......]) include(column_Name_List)with (drop_existing = on);
create index ix_cov_Employee_ID_Name on Employee (ID) include(Name);
go
首先,覆盖索引它只是非聚集索引的一种特别形式,下文说的非聚集索引不包涵覆盖索引,当然这个约定只适用于这一段话,这样做的
目的是为了说明各中的区别。
首先:
1、非聚集索引不包涵数据,通过它找到的只是文件中数据行的引用(表是堆的情况下)或是聚集索引的引用,SQL Server
要通这个引用去找到相应的数据行。
2、正因为非聚集索引它没有数据,才引发第二次查找。
3、覆盖索引就是把数据加到非聚集索引上,这样就不需要第二次查找了。这是一种以空间换性能的方法。非聚集索引也是。
只是做的没有它这么出格。
操作 4、
创建唯一索引
create unique index index_name on table_name (column ASC|DESC[,.....])with (drop_existing = on);
正如我前面所说,在创建表上的索引前,我会删除表上的所有索引,这里为什么我要再说一下呢!因为我怕你忘了。二来这个例子用的到它。
目前表是一个空表,我给它加两行数据。
insert into Employee(ID,Name) values(1,‘AAA‘),(1,‘BBB‘);

这下我们为表加唯一索引,它定义在ID这个列上
create unique index ix_uni_Employee_ID on Employee(ID);
go -- 可以想到因为ID有重复,所以它创建不了。

结论 1、 如果在列上有重复值,就不可以在这个列上定义,唯一索引。
下面我们把表清空: truncate table Employee;

接下来要做的就是先,创建唯一索引,再插入重复值。
create unique index ix_uni_Employee_ID on Employee(ID);
go
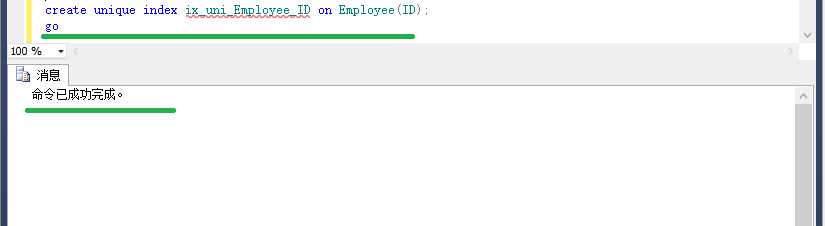
insert into Employee(ID,Name) values(1,‘AAA‘),(1,‘BBB‘);
go

结论 2、
定义唯一索引后相应的列上不可以插入重复值。
操作 5、
筛选索引
create index index_name on table_name(columName) where boolExpression;
create index ix_Employee_ID on Employee(ID) where ID>100 and ID< 200;
go
只对热点数据加索引,如果大量的查询只对ID 由 100 ~ 200 的数据感兴趣,就可以这样做。
1、可以减小索引的大小
2、为据点数据提高查询的性能。
总结:
BTree 索引有聚集与非聚集之分。
就查看上到聚集索引性能比非聚集索引性能要好。
非聚集索引分 覆盖索引,唯一索引,复合索引(当然聚集索引也有复合的,复合二字,只是说明索引,引用了多列),一般非聚集索引
就查看上到非聚集索引中覆盖索引的性能比别的非聚集索引性能要好,它的性能和聚集索引差不多,可是
它也不是’银弹‘ 它会用更多的磁盘空间。
最后说一下这个
with (drop_existing = on|off),加上这个的意思是如果这个索引还在表上就drop 掉然后在create 一个新的。特别是在聚集索引上
用使用这个就可以不会引起非聚集索引的重建。
with (online = on|off) 创建索引时用户也可以访问表中的数据,
with(pad_index = on|off fillfactor = 80); fillfactor 用来设置填充百分比,pad_index 只是用来连接fillfactor 但是它又不难少,
这点无语了。
with(allow_row_locks = on|off | allow_page_locks = on |off); 是否允许页锁 or 行锁
with (data_compression = row | page ); 这样可以压缩索引大小
标签:unique server esc 使用 exec 压缩 constrain 聚集 compress
原文地址:http://www.cnblogs.com/zxtceq/p/6606689.html