标签:color 分享 请求方式 界面 pat 资料 地址 2.7 设置
Requests库是目前常用且效率较高的爬取网页的库
1.一个简单的例子
import requests #引入requests库
r = requests.get("http://www.baidu.com") #调用get方法获取界面
print(r.status_code) #输出状态码
print(r.text) #输出页面信息
通过以下代码,便可获取一个response对象

2.通用代码框架
import requests def getHtmlText(url): try: r = requests.get(url, timeout = 30) #设置响应时间和地址 r.raise_for_status() #获取状态码,如果不是200会引发HTTPERROR异常 r.encoding = r.apparent_encoding #apparent_encoding是识别网页的编码类型 return r.text except: return "产生异常" if __name__ == "__main__": url = ‘http://www.baidu.com‘ print(getHtmlText(url))
3.requests库的具体介绍
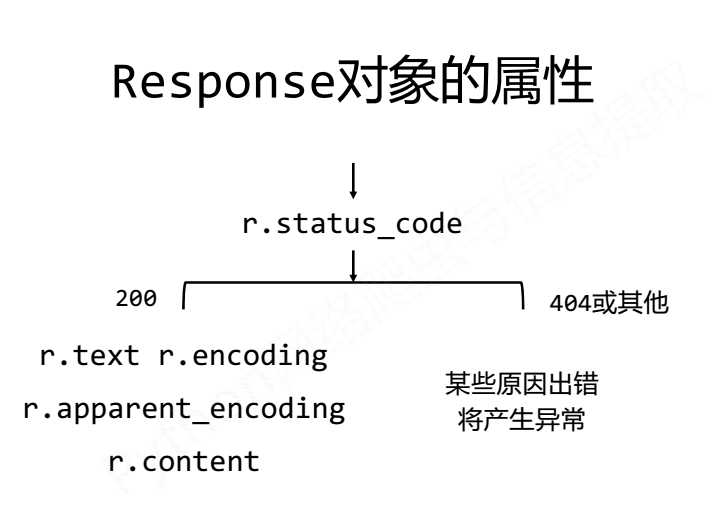
3.1 response属性介绍

属性逻辑结构:
3.2requests方法介绍
requests库对比http协议
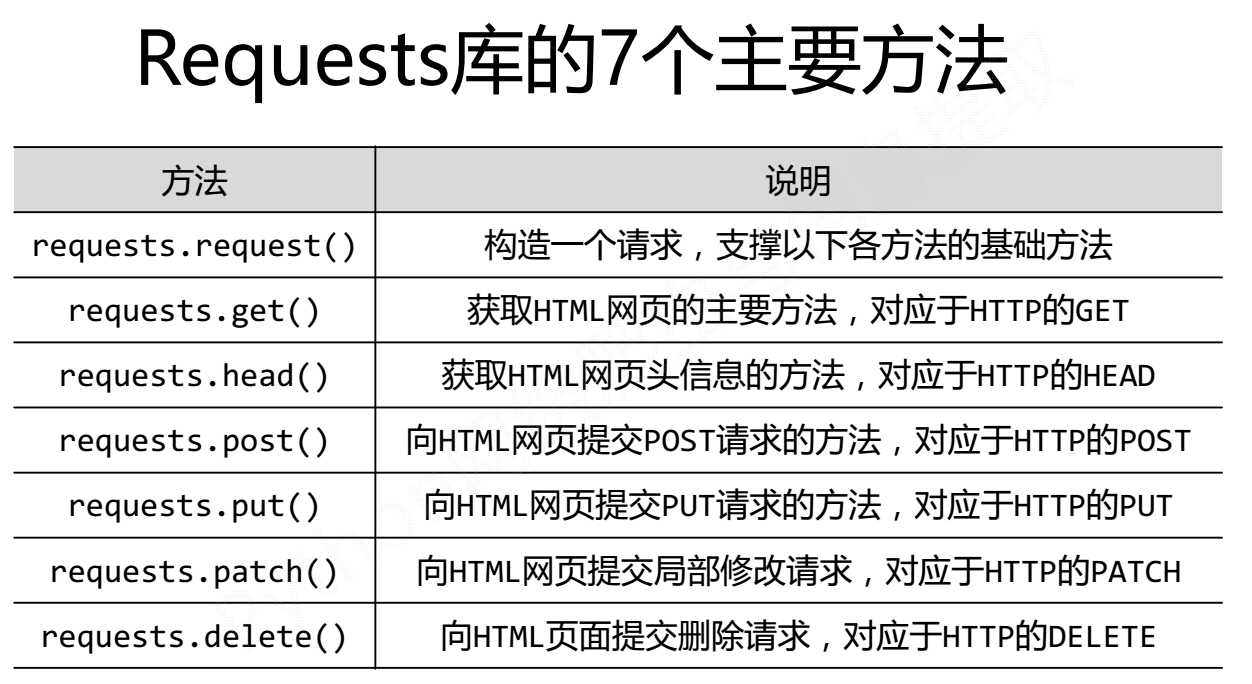
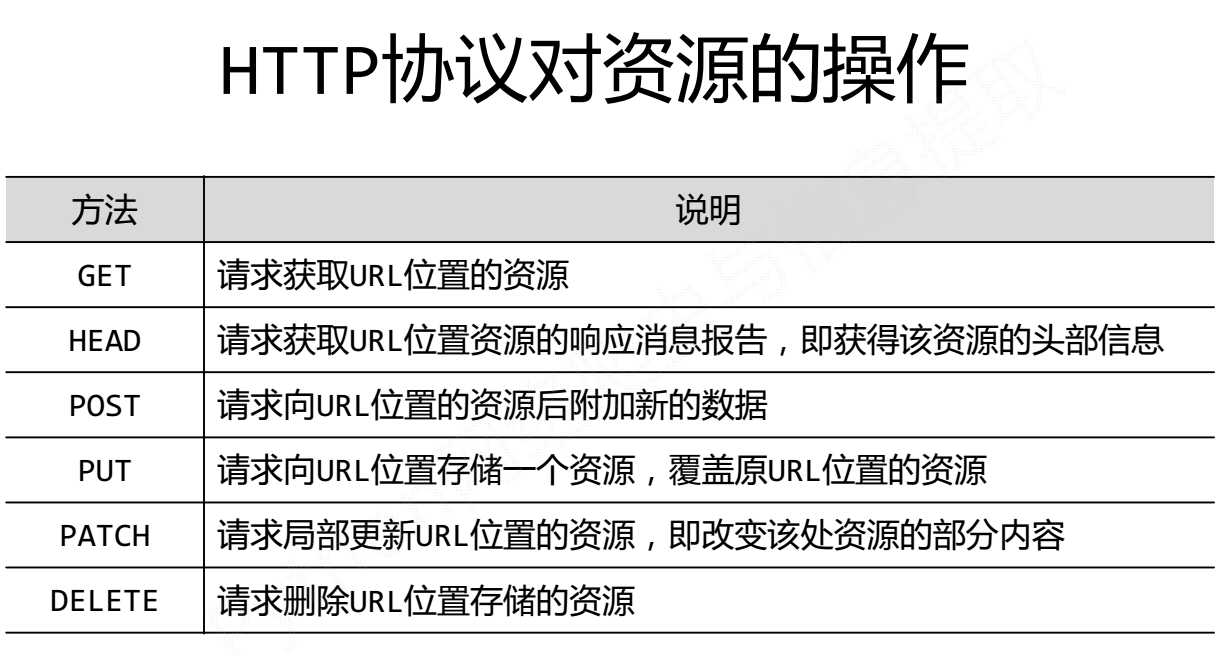
ps:在这些方法中,大致有三个参数,略有差别
3.2.1 get方法

r = requests.get(‘http://www.baidu.com‘) print(r.text)
3.2.2head方法

r = requests.head(‘http://www.baidu.com‘) print(r.headers)
3.2.3 post方法

payload = {‘key1‘: ‘value1‘, ‘key2‘ : ‘value2‘ }
r = requests.post(‘http://httpbin.org/post‘, data = payload)
print(r.text)
#输出结果
{...
"form": {
"key1": "value1",
"key2": "value2"
},
...}
3.2.4 put方法

payload = {‘key1‘: ‘value1‘, ‘key2‘ : ‘value2‘ }
r = requests.put(‘http://httpbin.org/post‘, data = payload) print(r.text) #向URL传一个字典,自动编码为表单
#........字符串,........data
#输出结果 {... "form": { "key1": "value1", "key2": "value2" }, ...}
3.2.5 reuqest方法--构造请求
requests.request(method, url, **kwrags) #method:请求方式,对应get/put/post等七种 #url : 链接 #**kwrags : 13个控制访问的参数
method请求方式:
requests.request(‘GET‘, url, **kwrags) requests.request(‘HEAD‘, url, **kwrags) requests.request(‘POST‘, url, **kwrags) requests.request(‘PUT‘, url, **kwrags) requests.request(‘PATCH‘, url, **kwrags) requests.request(‘DELETE‘, url, **kwrags) requests.request(‘OPTIONS‘, url, **kwrags)
**kwargs详解:

kv = {‘key1‘: ‘value1‘, ‘key2‘ : ‘value2‘ } #params
r = requests.request(‘POST‘, ‘http://python123.io/ws‘, data = kv)
data1 = ‘hellowrld‘ #data
r = requests.request(‘POST‘, ‘http://python123.io/ws‘, data = data1)
jso = {‘key1‘: ‘value1‘} #json
r = requests.request(‘POST‘, ‘http://python123.io/ws‘, json = jso)
hd = {‘key1‘: ‘value1‘} #headers
r = requests.request(‘POST‘, ‘http://python123.io/ws‘, headers = hd)

fs = {‘file‘ : open(‘data.xls‘,‘rb‘)} #files
r = requests.request(‘POST‘,‘http://python123.io/ws‘, files = fs)
#timeout
r = requests.request(‘POST‘,‘http://python123.io/ws‘, timeout = 10)
#proxies
pxs = {‘http‘: ‘http://usr:pass@10.10.10:1234‘,
‘https‘ : ‘https://10.10.10.1:4321‘}
r = requests.request(‘GET‘,‘http://www.baidu.com‘, proxies = pxs)
3.2.6 delete方法

3.2.7 patch方法

3.3PATCH和PUT的区别
.
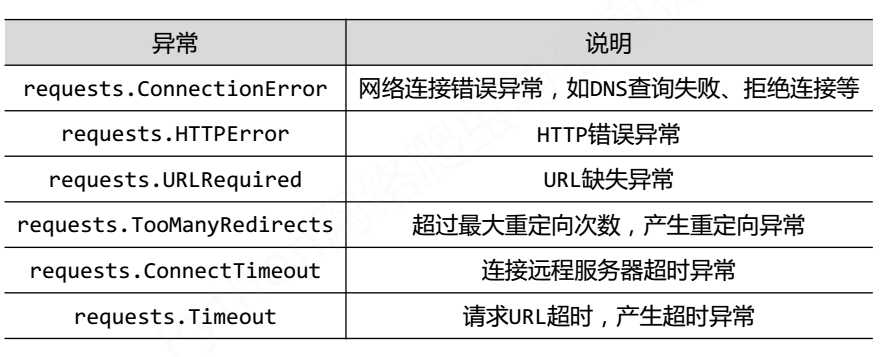
4.requests库的异常
本文是通过整合慕课网上的资料和网上相关资料完成
标签:color 分享 请求方式 界面 pat 资料 地址 2.7 设置
原文地址:http://www.cnblogs.com/helloandhey/p/6601534.html