标签:length 数组 key ret console art adk 约束 理解
本文以实例形式讲述了C#泛型的用法,有助于读者深入理解C#泛型的原理,具体分析如下:
首先需要明白什么时候使用泛型:
当针对不同的数据类型,采用相似的逻辑算法,为了避免重复,可以考虑使用泛型。
一、针对类的泛型
针对不同类型的数组,写一个针对数组的"冒泡排序"。
1.思路
● 针对类的泛型,泛型打在类旁。
● 由于在"冒泡排序"中需要对元素进行比较,所以泛型要约束成实现IComparable接口。
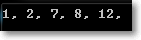
2.关于泛型约束
where T : IComparable 把T约束为实现IComparable接口
where T : class
where T : struct
where T : IComparable, new() 约束泛型必须有构造函数
3.关于冒泡算法
● 之所以for (int i = 0; i <= length -2; i++),这是边界思维,比如有一个长度为5的数组,如果0号位元素最终调换到4号位,每次调一个位,需要经过4次才能到4号位,即for(int i = 0; i <= 5-2, i++),i依次为0, 1, 2, 4,期间经历了4次。
● 至于for (int j = length - 1; j >= 1; j--)循环,即遍历从最后一个元素开始到索引为1的元素,每次与前一个位置上的元素比较。
4.关于比较
int类型之所以能比较,是因为int类型也实现了IComparable接口。
byte类型也一样实现了IComparable接口。
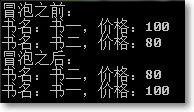
二、自定义一个类,使之也能实现冒泡算法
冒泡算法涉及到元素比较,所以自定义类必须实现IComparable接口。
三、针对方法的泛型
继续上面的例子,自定义一个类,并定义泛型方法。
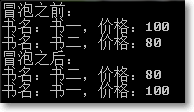
另外,使用泛型方法的时候,除了按以下:
还可以这样写:
可见,泛型方法可以根据数组实例隐式推断泛型是否满足条件。
四、泛型的其它优点
1.避免隐式装箱和拆箱
以下包含隐式装箱和拆箱:
2.能在编译期间及时发现错误
不使用泛型,在编译期不会报错的一个例子:
1.在当前文件中给泛型取别名
标签:length 数组 key ret console art adk 约束 理解
原文地址:http://www.cnblogs.com/zk-zhou/p/6634625.html