标签:put excel表格 效率 1.5 需要 标签 height print ram
需求:采集网站中每一页的联系人信息
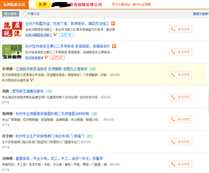
一、创建maven工程,添加jsoup和poi的依赖包
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.16-beta2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version> </dependency>
二、发送http get请求的客户端类
这里简单使用Jsoup.connect()访问url,也可以用HttpClient创建一个connection,设置长连接Connection:keep-alive,全部页面访问完成后再关闭connection,效率更高
package com.guods.contact; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; /** * 这里简单使用Jsoup.connect()访问url * 扩展:也可以创建一个connection,设置长连接Connection:keep-alive,全部页面访问完成后再关闭connection,效率更高 * @author guods * */ public class MyHttpClient { public Document get(String url){ try { return Jsoup.connect(url) .get(); } catch (IOException e) { e.printStackTrace(); } return null; } }
三、excel存取类,解析页面时提取联系人信息,存入excel文档。
package com.guods.contact; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import org.apache.poi.xssf.usermodel.XSSFCell; import org.apache.poi.xssf.usermodel.XSSFCellStyle; import org.apache.poi.xssf.usermodel.XSSFFont; import org.apache.poi.xssf.usermodel.XSSFRow; import org.apache.poi.xssf.usermodel.XSSFSheet; import org.apache.poi.xssf.usermodel.XSSFWorkbook; /** * excel * * @author guods * 扩展:excel读写数据可以模仿集合实现增删改查等方法,方便调用 * 如,把本类实现Iterable接口,再写个实现Iterator的内部类,就可以和集合一样迭代excel每一行的数据,这里用不到暂且不写 */ public class Excel { private String filePath; private XSSFWorkbook workbook; private XSSFSheet sheet; private XSSFCellStyle titleStyle, commonStyle; private int rowCount; //总记录数 /** * * @param file 文件名 * @param sheetName sheet名 * @param columnNames 第一行内容(标题) */ public Excel(String file, String sheetName, String[] columnNames) { super(); this.filePath = file; newSheet(sheetName, columnNames); } /** * 初始化excel表格,生成标题(第一行数据) * @param sheetName sheet标签名 * @param columnNames 列名 */ private void newSheet(String sheetName, String[] columnNames){ workbook = new XSSFWorkbook(); //设置标题字体 XSSFFont titleFont = workbook.createFont(); titleFont.setBold(true); titleFont.setFontName("黑体"); titleStyle = workbook.createCellStyle(); titleStyle.setFont(titleFont); //设置正文字体 XSSFFont commonFont = workbook.createFont(); commonFont.setBold(false); commonFont.setFontName("宋体"); commonStyle = workbook.createCellStyle(); commonStyle.setFont(commonFont); //创建sheet sheet = workbook.createSheet(sheetName); //设置初始记录行数 rowCount = 0; //创建标题行 insertRow(columnNames, titleStyle); } public void insertRow(String[] rowData){ insertRow(rowData, commonStyle); } /** * 插入一行数据 * @param rowData 数据内容 * @param style 字体风格 */ public void insertRow(String[] rowData, XSSFCellStyle style){ XSSFRow row = sheet.createRow(rowCount); for (int i = 0; i < rowData.length; i++) { XSSFCell cell = row.createCell(i); sheet.setColumnWidth(i, 5000); cell.setCellStyle(style); cell.setCellValue(rowData[i]); } rowCount++; } /** * excel文件存储到磁盘 */ public void saveFile(){ try { File file = new File(filePath); if (file.exists()) { file.delete(); } file.createNewFile(); FileOutputStream fileOutputStream = new FileOutputStream(file); workbook.write(fileOutputStream); } catch (FileNotFoundException e) { System.out.println(filePath + "保存文件错误:" + e.getMessage()); } catch (IOException e) { System.out.println(filePath + "保存文件错误:" + e.getMessage()); } } /** * 返回excel总行数 * @return */ public int size() { return rowCount; } }
四、页面解析类。解析MyHttpClient获取的页面,把有效数据存到excel。
分析html页面的标签结构,根据标签结构写页面的解析方法,取联系人信息对应的元素。
当然,如果采集的量比较多的话也可以把数据存到本地数据库作为自己的联系人库。方便起见先存到excel。
package com.guods.contact; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class PageParser { /** * 解析列表页面,根据页面的标签结构提取联系人信息 * VIP会员在列表中没有展示联系人信息,需要获取VIP会员的公司链接,抓取公司页面,在公司页面获取联系人信息 * @param document 获取的http页面 * @param excel 提取客户信息存到excel */ public void parseListPage(Document document, Excel excel){ if (document == null) { return; } Elements tbodys = document.getElementsByTag("tbody"); if (tbodys == null || tbodys.size() == 0) { return; } Element tbody = tbodys.get(0); Elements trs = tbody.getElementsByTag("tr"); for (int i = 0; i < trs.size(); i++) { //解析列表页面,获取列表信息 Elements tdivs = trs.get(i).getElementsByClass("tdiv"); if (tdivs.size() == 0) { continue; } //取描述字段 Element tdiv = trs.get(i).getElementsByClass("tdiv").get(0); String desc = tdiv.text(); //取标题字段 Element a = tdiv.getElementsByTag("a").get(0); String title = a.text(); //取客户名字段 Element seller = tdiv.getElementsByClass("seller").get(0); String sellerName = seller.text(); //取联系电话字段 Element yuyueVertop = trs.get(i).getElementsByClass("yuyue_vertop").get(0); String contact = yuyueVertop.attr("data-j4fe"); //excel插入记录,联系电话没有的数据不记录 if (contact != null && contact.trim() != "") { String[] rowData = {title, desc, sellerName, contact}; excel.insertRow(rowData); } } } }
五、采集数据
浏览器上复制页面的url,以url的页码数为界前后分开,把preUrl + 页码数 + postUrl拼接成完整的url,循环访问每个页面。
package com.guods.contact; import org.jsoup.nodes.Document; public class Main { public static void main( String[] args ) { //采集1-10页的数据 startWork(1, 10); } public static void startWork(int fromPage, int endPage){ StringBuffer urlBuffer = new StringBuffer(); String preUrl = "http://hz.58.com/shigongjl/pn"; String postUrl = "/?PGTID=0d306d36-0004-f163-ca53-0cdfddb146d0&ClickID=2"; MyHttpClient myHttpClient = new MyHttpClient(); Document document; //创建excel文档 String[] columnNames = {"标题", "描述", "名字", "联系方式"}; Excel excel = new Excel("d:\\contact.xlsx", "contact", columnNames); //创建一个解析器 PageParser parser = new PageParser(); //修改页码拼接请求,一次循环处理一个页面 for (int i = fromPage; i <= endPage; i++) { //清空urlBuffer,重新组装url if (urlBuffer.capacity() > 0) { urlBuffer.delete(0, urlBuffer.capacity()); } urlBuffer.append(preUrl).append(i).append(postUrl); //访问url,获取document document = myHttpClient.get(urlBuffer.toString()); //解析document parser.parseListPage(document, excel); System.out.println("第" + i + "页列表采集完成。。。"); } //数据存档 excel.saveFile(); System.out.println("采集完成,列表总共:" + excel.size() + "条"); } }
六、运行结果:
第1页列表采集完成。。。 第2页列表采集完成。。。 第3页列表采集完成。。。 第4页列表采集完成。。。 第5页列表采集完成。。。 第6页列表采集完成。。。 第7页列表采集完成。。。 第8页列表采集完成。。。 第9页列表采集完成。。。 第10页列表采集完成。。。 采集完成,列表总共:317条
第一次发博,亲测可用。
Jsoup抓取、解析网页和poi存取excel综合案例——采集网站的联系人信息
标签:put excel表格 效率 1.5 需要 标签 height print ram
原文地址:http://www.cnblogs.com/guods/p/6636801.html