标签:推荐算法 来源 计算 排序 dal tin imp size src
KNN算法,故名思议,K个最邻近值的分类算法。监督学习中的一种,典型的懒人算法,通过计算所有的预测样本到学习样本的距离,选取其中K个最小值加入样本组中,样本组中的样本隶属于那个分类的个数最多,那么我们就预测我们的预测样本是属于这个类型的。
学习来源某个pdf(别人的学习笔记):
第四章 KNN(k最邻近分类算法) 最邻近分类算法) 最邻近分类算法) 最邻近分类算法) 最邻近分类算法) 最邻近分类算法) 最邻近分类算法) 最邻近分类算法) 1.算法 思路 通过计算每个训练样例到待分类品的 距离,取和最近K个训练 样例, K个 样品中哪个类别 的训练例占多数,则待分就属于核心思想: 如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。 2.算法描述 1. 算距离 :给定测试对象,计它与训练集中的每个依公式计算 Item 与 D1、D2 … …、Dj 之相似度。得到Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)。 2. 将Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)排序,若是超过相似度阈值t则放入邻居案例集合NN。 找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻 3. 自邻居案例集合NN中取出前k名,依多数决,得到Item可能类别。 做分类:根据这k个近邻归属的主要类别,来对测试对象分类 3.算法步骤 ? step.1---初始化距离为最大值 初始化距离为最大值 ? step.2---计算未知样本和每个训练的距离 计算未知样本和每个训练的距离 dist ? step.3---得到目前 得到目前 K个最临近样本中的大距离 maxdist ? step.4---如果 dist小于 maxdist,则将该训练样本作为 K-最近邻样本 ? step.5---重复步骤 重复步骤 2、3、4,直到未知样本和所有训练的距离都算完 ? step.6---统计 K-最近邻样本中每个类标号出现的次数 ? step.7---选择出现频率最大的类标号 作为未知样本选择出现频率最大的类标号 作为未知样本该算法涉及 3个主要因素: 训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量训练集、 距离或相似的衡量k的大小。 的大小。 的大小。 4. k邻近模型三个基本要素 邻近模型三个基本要素 邻近模型三个基本要素 邻近模型三个基本要素 邻近模型三个基本要素 邻近模型三个基本要素 邻近模型三个基本要素 邻近模型三个基本要素 三个基本要素为 距离度量、 距离度量、 距离度量、 距离度量、 k值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 值的选择和分类决策规则 距离度量: 设特征空间 χ是 n维实数向量空间 ????,????,????∈??,????=(????(1),????(2),…,????(??))??, ????=(????(1),????(2),…,????(??))?? ????,????的????距离定义为: ????(????,????)=(Σ|????(??)?????(??)|??????=1)1/?? p≥1 p=2时为欧式距离: ??2(????,????)=(Σ|????(??)?????(??)|2????=1)1/2 p=1时为曼哈顿 距离: ??1(????,????)=Σ|????(??)?????(??)|????=1 p=∞时,它是各个坐标距离的最大值 ??∞(????,????)=max??|????(??)?????(??)| 5.算法优缺点 算法优缺点 算法优缺点 算法优缺点 1) 优点 ? 简单,易于理解实现无需估计参数训练; ? 适合样本容量比较大的分类问题 ? 特别适合于多分类问题 (multi-modal,对象具有多个类别标签 ),例如根据基因特征来判断其功能 分类, kNN比 SVM的表现要好 2) 缺点 ? 懒惰算法,对测试样本分类时的计量大内存开销评慢; ? 可解释性较差,无法给出决策树那样的规则 ? 对于样本量较小的分 类问题,会产生误6.常见问题 1)K值设定为多大 k太小,分类结果易受噪声点影响; k太大,近邻中又可能包含多的其它类别点。(对距离加 太大,近邻中又可能包含多的其它类别点。(对距离加 权,可以降低 k值设定的影响) k值通常是采用 交叉检验 交叉检验 交叉检验 来确定(以 k=1为基准) 经验规则: k一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 一般低于训练样本数的平方根 2)类别如何判定最合适 投票法没有考虑近邻的距离远,更也许应该决定最终分类所以加权更恰当一些。 3)如何选定合适的距离衡量 高维度对距离衡量的影响:众所周知当变数越多,欧式区分能力就差。 变量值域对距离的影响:越大常会在计算中占据主导作用,因此应先进行标准化。 4)训练样本是否要一视同仁 在训练集中,有些样本可能是更值得依赖的。 可以给不同的样本施加权重,强依赖降低信影响。 5)性能问题 kNN是一种懒惰算法,平时不好学习考试(对测样 是一种懒惰算法,平时不好学习考试(对测样 本分类)时才临阵磨枪(去找 k个近 邻)。 邻)。 懒惰的后果:构造模型很简单,但在对测试样本分类地系统开销大因为要扫描全部训练并计算距离。 已经有一些方法提高计算的效率,例如压缩训练样本量等。 6)能否大幅减少训练样本量,同时又保持分类精度? 浓缩技术 (condensing) 编辑技术 (editing) 6.KNN算法 Python实现例之电影分类 实现例之电影分类 实现例之电影分类 实现例之电影分类 实现例之电影分类 实现例之电影分类 实现例之电影分类 实现例之电影分类 电影名称 打斗次数 接吻次数 电影类型 California Man 3 104 Romance He’s Not Really into Dudes 2 100 Romance Beautiful Woman 1 81 Romance Kevin Longblade 101 10 Action Robo Slayer 3000 99 5 Action Amped II 98 2 Action 未知 18 90 Unknown 任务描述:通过打斗次数和接吻来界定电影类型 调用 Python的 sklearn模块求解 1. import numpy as np 2. from sklearn import neighbors 3. knn = neighbors.KNeighborsClassifier() #取得knn分类器 4. data = np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]]) # <span style="font-family:Arial, Helvetica, sans-serif;">data对应着打斗次数和接吻次数</span> 5. labels = np.array([1,1,1,2,2,2]) #<span style="font-family:Arial, Helvetica, sans-serif;">labels则是对应Romance和Action</span> 6. knn.fit(data,labels) #导入数据进行训练‘‘‘ 7. #Out:KNeighborsClassifier(algorithm=‘auto‘, leaf_size=30, metric=‘minkowski‘, 8. metric_params=None, n_jobs=1, n_neighbors=5, p=2, 9. weights=‘uniform‘) 10. knn.predict([18,90]) 说明: 首先,用 labels数组中的 数组中的 1和 2代表 Romance和 Aciton,因为 sklearn不接受字符数组作为标志,只 不接受字符数组作为标志,只 能用 1,2这样的 int型数据来表示,后面处理可以将 型数据来表示,后面处理可以将 1和 2映射到 Romance和 Action上来。 fit则是 用 data和 labels进行训练, 进行训练, data对应的是打斗次数和接吻构成向量,称之为特征。 labels则是这个数据所代表的电影属类型。调用 predict 进行预测,将未知 电影的特征向量代入,则能 分析出该未知电影所属的类型。此处计算结果为 1,也就是该未知电影属于 Romance,
容我水一发根据球星的得分数据(瞎编的,懒得去爬,后面可以写个系列啊,挖个坑,后面填),得出球星所打的位置是中锋还是后卫(没错,我就是在说rondo):
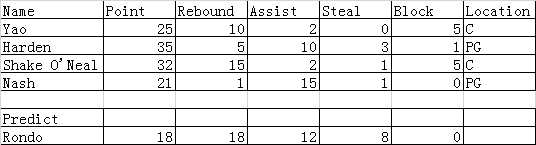
不废话,根据前面四个人的数据,预测下我多是否真是大中锋:
遇到问题:ValueError: Expected n_neighbors <= n_samples, but n_samples = 4, n_neighbors = 5,训练的样本数小于维度,那我再加几个样本。
#-*- coding:utf-8 -*- #导入sklearn,里面有knn框架,就不用自己去算了,虽然我曾经写过一个类似的推荐算法。 from sklearn import neighbors import numpy as np #建立knn模型,knn分类器 knn=neighbors.KNeighborsClassifier() #导入训练样本 data=np.array([[25,10,2,0,5],[35,5,10,3,1],[32,15,2,1,5],[21,1,15,1,0],[20,15,1,2,8],[30,10,10,1,8]]) #导入预测值 locations=np.array([‘C‘,‘PG‘,‘C‘,‘PG‘,‘C‘,‘PG‘]) #模型训练 knn.fit(data,locations) #进行预测 print ‘Rondo is %s‘%knn.predict([15,15,10,8,0])[0] #运行结果 #C:\Python27\lib\site-packages\sklearn\utils\validation.py:395: DeprecationWarning: Passing 1d arrays as data is deprecated in 0.17 and will raise ValueError in 0.19. Reshape your data either using X.reshape(-1, 1) if your data has a single feature or X.reshape(1, -1) if it contains a single sample.DeprecationWarning)
是不是很水,是的我多就是大中锋,不服来战。
标签:推荐算法 来源 计算 排序 dal tin imp size src
原文地址:http://www.cnblogs.com/AlwaysT-Mac/p/6640720.html