标签:size ups 并且 指定 str 导入表 system 结构 file
在先前的几篇随笔中已经介绍了Hadoop、Zookeeper、Hbase的分布式框架搭建方案,目前已经搭建完成了一个包含11个节点的分布式集群。而对于HBase数据库的使用仅限于测试性质的增删改查指令,为了进一步熟悉分布式框架的使用,本文介绍将已有的数据从关系型数据库SQL Server中导入到HBase中的方法。
要完成从关系型数据库到HBase数据的迁移,我们需要使用Sqoop工具,Sqoop是Apache的一个独立项目,设计目的即是在Hadoop(Hive)和传统数据库(MySQL、postgresql)之间进行数据的传递。Sqoop工具基于数据仓库工具Hive,通过Hive来将数据查询转换成MapReduce任务实现数据的传递。因此,要完成本次数据的迁移,我们需要以下几个准备:
①Hive:apache-hive-2.1.1-bin.tar.gz
②Sqoop:sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
③JDBC for SQL Server:sqljdbc_3.0.1301.101_enu.tar.gz
④Connector between SQL Server and Sqoop:sqoop-sqlserver-1.0.tar.gz
======================以下所有操作均在Master主机上并且以root用户执行======================
1、安装Hive
①建立hive目录
cd /home
mkdir hive
②解压安装包(安装包移至/home/hive下)
tar -zxvf apache-hive-2.1.1-bin.tar.gz
③设置环境变量
vi /etc/profile
追加以下:
export HIVE_HOME=/home/hive/apche-hive-2.1.1-bin
export PATH=$HIVE_HOME/bin:$PATH
export PATH
追加以下:
export HCAT_HOME=$HIVE_HOME/hcatalog
④使配置生效
source /etc/profile
2、安装sqoop
①建立sqoop目录
cd /home
mkdir sqoop
②解压安装包(安装包移至/home/sqoop下)
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
③设置环境变量
vi /etc/profile
追加以下:
export SQOOP_HOME=/home/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export SQOOP_CONF_DIR=$SQOOP_HOME/conf
export PATH=$SQOOP_HOME/bin:$PATH
export PATH
④使配置生效
source /etc/profile
3、配置JDBC
①解压(位置随意)
tar -zxvf sqljdbc_3.0.1301.101_enu.atr.gz
②复制jdbc到sqoop下
cp sqljdbc_3.0/enu/sqljdbc4.jar /home/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib
4、配置SQL Server sqoop Connector
①解压(位置随意,这里是/home)
tar -zxvf sqoop-sqlserver-1.0.tar.gz
②设置环境变量
vi /etc/profile
追加以下:
export MSSQL_CONNECTOR_HOME=/home/sqoop-sqlserver-1.0/
配置生效:
source /etc/profile
③配置到sqoop
cd sqoop-sqlserver-1.0
./install.sh
5、 配置sqoop
存在这部分工作的原因是sqoop的默认配置会有一些我们不需要用到的东西,在其配置文件$SQOOP_HOME/bin/configure-sqoop文件中,定义了许多需要预先配置的参数与环境,有些我们已经配置完成,但是另外有些是不需要用到的(目前还没意识到有什么作用),因此,为了防止运行时检查配置不通过,我们直接的处理办法就是取消这部分的配置检查。
注释ACCUMULO相关配置:在configure-sqoop文件中,注释掉与ACCUMULO_HOME相关的所有命令行,并保存退出。
6、目前的环境变量
值得注意的是,之前并没有加入HBase的环境变量,在这里是需要把HBase相关的环境变量加入的。
# /etc/profile # System wide environment and startup programs, for login setup # Functions and aliases go in /etc/bashrc # It‘s NOT a good idea to change this file unless you know what you # are doing. It‘s much better to create a custom.sh shell script in # /etc/profile.d/ to make custom changes to your environment, as this # will prevent the need for merging in future updates. pathmunge () { case ":${PATH}:" in *:"$1":*) ;; *) if [ "$2" = "after" ] ; then PATH=$PATH:$1 else PATH=$1:$PATH fi esac } if [ -x /usr/bin/id ]; then if [ -z "$EUID" ]; then # ksh workaround EUID=`id -u` UID=`id -ru` fi USER="`id -un`" LOGNAME=$USER MAIL="/var/spool/mail/$USER" fi # Path manipulation if [ "$EUID" = "0" ]; then pathmunge /sbin pathmunge /usr/sbin pathmunge /usr/local/sbin else pathmunge /usr/local/sbin after pathmunge /usr/sbin after pathmunge /sbin after fi HOSTNAME=`/bin/hostname 2>/dev/null` HISTSIZE=1000 if [ "$HISTCONTROL" = "ignorespace" ] ; then export HISTCONTROL=ignoreboth else export HISTCONTROL=ignoredups fi export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL # By default, we want umask to get set. This sets it for login shell # Current threshold for system reserved uid/gids is 200 # You could check uidgid reservation validity in # /usr/share/doc/setup-*/uidgid file if [ $UID -gt 199 ] && [ "`id -gn`" = "`id -un`" ]; then umask 002 else umask 022 fi for i in /etc/profile.d/*.sh ; do if [ -r "$i" ]; then if [ "${-#*i}" != "$-" ]; then . "$i" else . "$i" >/dev/null 2>&1 fi fi done unset i unset -f pathmunge export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131.x86_64 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin #hadoop export HADOOP_HOME=/home/hadoop/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/sbin export PATH=$PATH:$HADOOP_HOME/bin #zookeeper export ZOOKEEPER_HOME=/home/zookeeper/zookeeper-3.4.6/ export PATH=$ZOOKEEPER_HOME/bin:$PATH export PATH #HBase export HBASE_HOME=/home/hbase/hbase-1.2.4 export PATH=$HBASE_HOME/bin:$PATH export PATH #hive export HIVE_HOME=/home/hive/apache-hive-2.1.1-bin export PATH=$HIVE_HOME/bin:$PATH export PATH export HCAT_HOME=$HIVE_HOME/hcatalog #sqoop export SQOOP_HOME=/home/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha export SQOOP_CONF_DIR=$SQOOP_HOME/conf export PATH=$SQOOP_HOME/bin:$PATH export PATH export MSSQL_CONNECTOR_HOME=/home/sqoop-sqlserver-1.0/
7、数据迁移实验
在执行迁移命令之前,需要在Hbase中建立好对应的表
#hbase shell
进入hbase shell后执行
>create ‘test‘, ‘cf‘
然后在Terminal中执行
#sqoop import --connect ‘jdbc:sqlserver://<IP Address>;username=<username>;password=<password>;database=<database>‘ --table <sql server table name> --hbase-table <hbase table name> --column-family <hbase table column family name> --hbase-row-key <sql server table primary key>
需要注意:
①如果SQL Server的表是正常的单一主键的表结构,那么可以直接指定hbase-row-key执行上述命令,此时该命令会默认以多个mapreduce任务执行该指令
②如果SQL Server的表是联合主键,那么这样导入就会存在一个问题,无法根据主键分解查询任务,也就没有办法进行MapReduce,那么此时必须指定参数 ‘-m 1‘只用一个mapreduce任务
③针对没有主键的情况,若数据量巨大,必须分为多个mapreduce任务,那么需要找到一个拆分字段,从而hive可以根据该字段拆分任务。此时我们须在导入指令中添加‘--split-by <id>‘
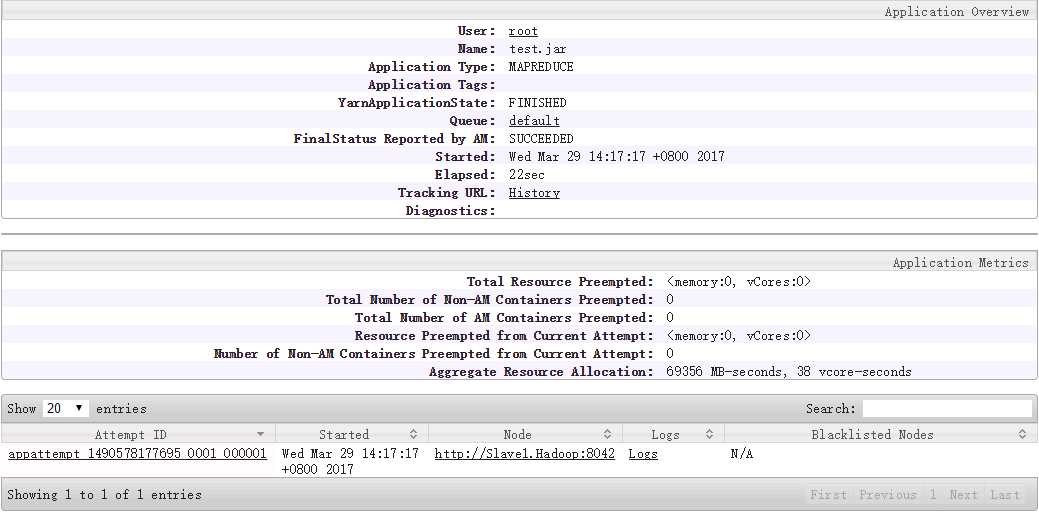
在我实际的操作中,SQL Server中的表结构是联合主键,第一次导入表中100条数据记录,根据这篇博客的介绍,配置了$SQOOP_HOME/conf/sqoop-site.xml,我指定了‘--hbase-row-key <id1>,<id2>‘,并指定‘-m 1‘,导入数据成功。(耗时22sec)
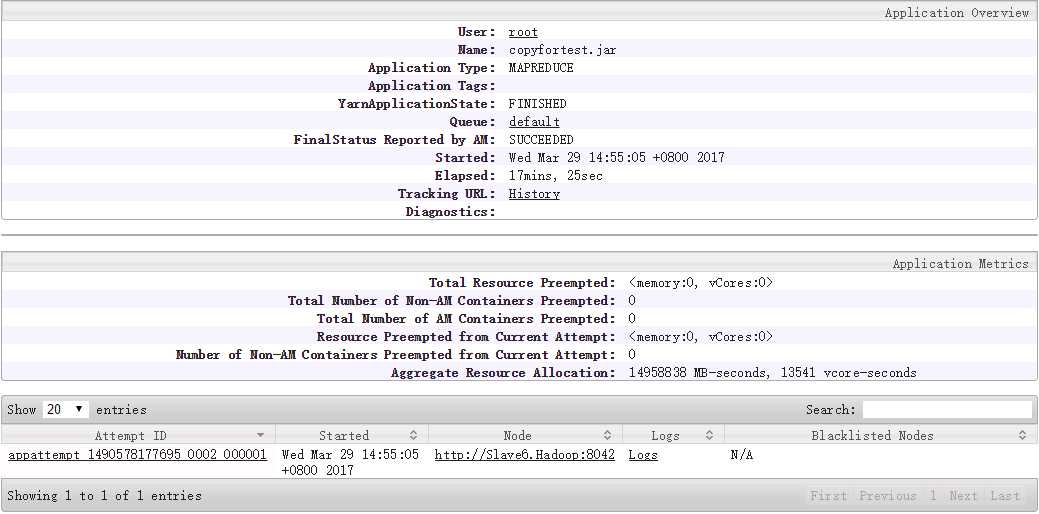
第二次尝试将数据库中的近160W条数据记录导入到HBase中,添加参数‘--split-by <id>‘,并指定‘-m 12‘,数据同样导入成功。(耗时17min25sec)
8、存在问题
对sqoop拆分任务的理解仍然不够深入,自己完成的实验虽然成功,但是并没有做对比实验确定真正的影响因素
9、参考文章
利用SQOOP将数据从数据库导入到HDFS - 我喂自己袋盐 - 博客频道 - CSDN.NET
Sqoop将SQLServer数据导入HBase - nma_123456的专栏 - 博客频道 - CSDN.NET
Centos 利用sqoop从sqlserver导入数据到HDFS或Hive - 王伟挺的专栏 - 博客频道 - CSDN.NET
sqoop并行导入数据 - 东杰书屋 - 博客频道 - CSDN.NET
sqoop针对联合主键的表导入hbase的简单控制技巧 - 黄刚的技术博客 - 博客频道 - CSDN.NET
参考链接
标签:size ups 并且 指定 str 导入表 system 结构 file
原文地址:http://www.cnblogs.com/zmt0429/p/6641783.html