标签:size 细节 abstract orm 修改 类型 保存 table 大量
上一篇博文简介了java类集框架几大常见集合框架,这一篇博文主要分析一些接口特性以及性能优化。
一:List接口
List是最常见的数据结构了,主要有最重要的三种实现:ArrayList,Vector,LinkedList,三种List均来自AbstracList的实现,而AbstracList直接实现了List接口,并拓展自AbstractCollection。
在三种实现中,ArrayList和Vector使用了数组实现,可以认为这两个是封装了对内部数组的操作,操作这两个List等价于对内部对象数据的操作,这两个采用了几乎相同的算法,唯一的区别就是对多线程的支持,ArrayList没有对任何一个方法作线程同步,因此不是线程安全的,从理论上来说ArrayList性能好一些,但是实际相差不是非常明显。
LinkedList使用了循环双向链表数据结构,这跟List是截然不同的使用场景,下面我对比ArrayList跟LinkedList一些操作区别;
1.增加元素到列表尾端
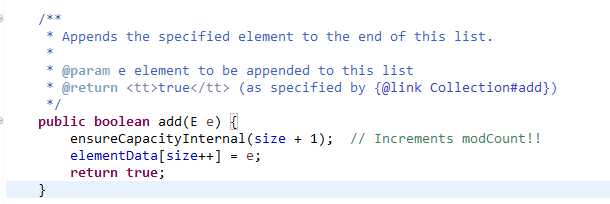
ArrayList的add()方法性能取决于ensureCapacityInternal()方法,实现如下:

可以看到,只要ArrayList当前容量足够大,add()操作效率非常高,如果容量需求超过当前数组大小,就会扩容,扩容产生大量的数组复制操作,而数组复制时最终调用System.arraycopy()方法,所以add()操作效率还是相当高的。
而LinkedList add()调用如下:
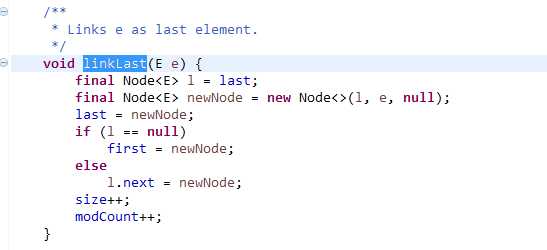
典型的链表结构,所以不用考虑容量的问题,这点比ArrayList有一定的性能优势,然而源码里很清楚,每次都要new新的Node对象,并进行更多的赋值操作,频繁的系统调用中,对性能会产生一定的影响,所以各有利弊。
分别用ArrayList和LinkedList测试循环50万次add()方法(在加大堆大小环境下 比如-Xmx512M -Xms512M) ,使用-Xmx512M -Xms512M目的是屏蔽GC对程序执行速度测量的干扰,最后结果是ArrayList相对耗时16ms,LinkedList31ms,,可见,不间断的生成新的对象还是占用了一定的系统资源,而因为数组的连续性,因此总是在尾端增加元素时,只有在空间不足时才会扩容和数组复制,所以绝大部分情况追加操作效率都很高。
如果测试使用默认JVM的堆大小,差别会更大,使用LinkedList对堆内存和GC要求更高。
2.随机访问元素(RandomAccess接口)
来看一下两种List的构造
LinkedList:
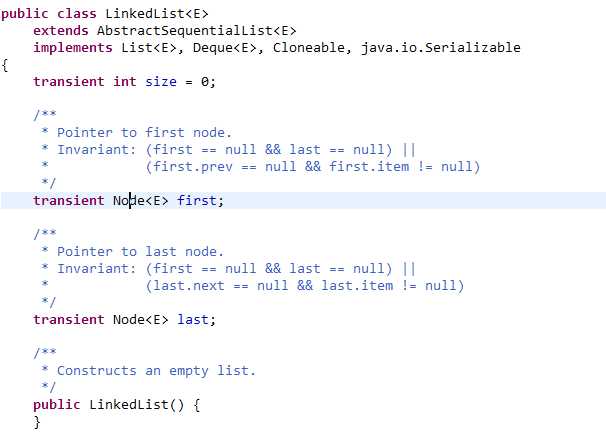
ArrayList:

可以看到ArrayList实现了RandomAccess接口而LinkedList没有实现此接口,那么RandomAccess接口有什么作用呢?
此接口的好处是可以在应用程序中知道正在处理的List对象是否可以快速随机访问,从而针对不同的list进行不同的操作,以提高程序的性能。
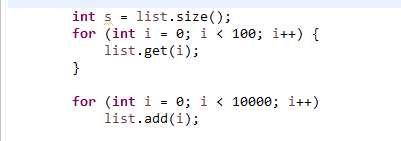
同样执行这段代码,LinkedList耗时16140ms,而ArrayList耗时32ms,就随机访问元素的相对速度而言,两者差了几个数量级,进一步可以通过LinkedList的get()方法实现来看一下:
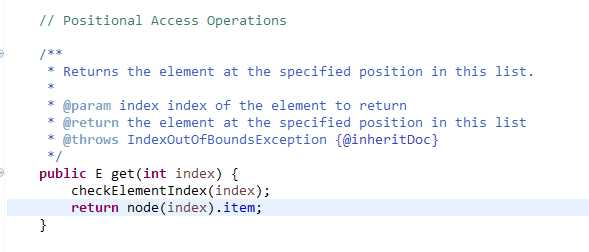
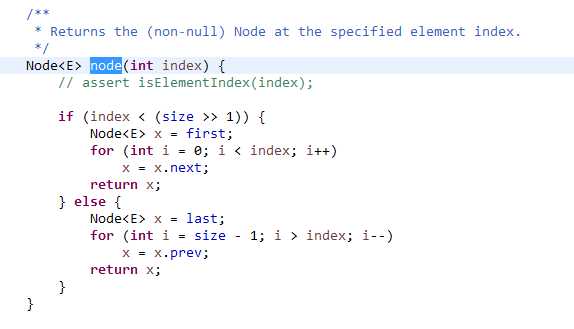
显而易见是个双向循环链表的二分查找,虽然二分可以减少时间,但是遍历过程还是消耗了大量的cpu时间,这相比ArrayList直接操作数组的下标
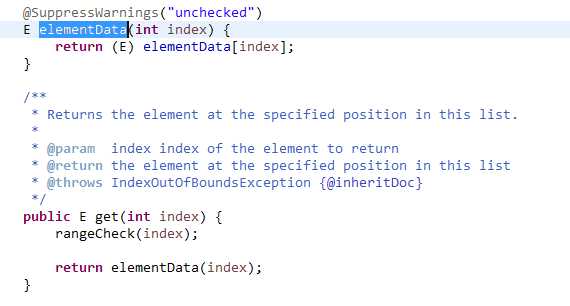
查找,性能差远了。
另外稍微提一下,(1)foreach比直接用迭代器性能差一点点,因为foreach底层同样是迭代器但是多了一步赋值的操作。
(2)集合的构造也最好使用有预估容量的方式,这样可以避免频繁的扩容,复制数据,跟上一篇StringBuffer的内容同理。
(3)ArrayList比LinkedList随机访问强大,但是增加元素和删除元素稍弱,两者使用场景不同。
二:Map和Set(主要针对hashcode的优劣和红黑二叉树跟Linked排序区别)
在上一篇讲类集框架的博客里我已经介绍了HashMap等,什么同步不同步,数据结构我就不重复讲了,这篇主要细节分析一下hashcode等东西。
HashMap,HashTable和Collections.synchronizedMap()三者性能差异不大,同样执行10万次get()方法,相对耗时很接近,可以认为三者并无明显差异,下面我只举例HashMap。
HashMap的高性能要保证以下几点:
1.hash算法必须高效
2.hash值到内存地址(数组索引)的算法是快速的
3.根据内存地址(数组索引)可以直接取得对应的值
从第一个说起,hash算法,来看一下HashMap的hash,首先是基于位运算的,所以是高效的

Object的hashcode()是native的
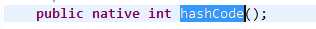
native是什么意思呢,native比一般的方法快,因为它直接调用操作系统本地连接库的API,由于hashcode()方法是可以重载的,因此为了保证hashmap的性能,需要确保你重载的hashcode方法是高效的,所以为什么很多开发选择HashMap的泛型是String,Integer之类的,因为这些lang包的都重载实现了很好的hashcode(),这比你自己写的大部分算法都要牛逼稳定。
第二个问题,hash冲突,此类型的第一篇博文我说了hash冲突是挂链表解决,HashMap实际上是一个链表的数组,每一个Entry是一个链表,有key value next hash,有冲突时,新的entry的next就会指向oldValue,这就实现了在一个数组索引空间存放多个值项。

上面是JDK8的put()方法源码,我发现跟之前的版本有些区别了,不过原理一样,都是上面说的一个数组索引空间放多个值,然后next指向oldValue。
所以基于这种hashcode()和hash()方法的实现方法只要足够好,能够尽可能的减少冲突的产生,那么对HashMap的操作几乎等价于操作数组,随机访问几乎等于随机访问数组,这个效率就跟ArrayList一样强大,性能非常不错,但是如果你覆写的很垃圾,那么你的HashMap就退化成了几个链表,遍历HashMap等于遍历链表,你懂的,上面我已经写过了,这个随机访问的性能是非常垃圾的。
第三点就是容量参数的问题了,HashMap内部维护了一个threshold变量,它始终被定义为当前数组总容量和负载因子的乘积,它表示HashMap的阀值,当实际容量超过阀值就会扩容。上面也提了,尽量给一个容量参数,初始大小和负载因子设置合理的话,可以有效减少HashMap扩容的次数。
接着讲一下LinkedHashMap-有序的HashMap
HashMap是无序的,如果希望元素保存输入时的顺序,就需要使用LinkedHashMap,它保留了HashMap的高性能(当然,建立在良好的hashcode()方法实现上),在HashMap基础上又内部增加了一个链表,用以存放元素的顺序,所以它可以理解为一个维护了元素次序表的HashMap。

源码显示它通过继承entry,多维护了一个before和after属性来记录某一表项的前驱和后继,并构成循环链表。
需要注意的是不要在迭代器模式中使用LinkedHashMap的get()操作,这个特性适用于所有的集合类,get()方法会改变链表结构,迭代器模式中不允许修改被迭代的集合。
虽然LinkedHashMap可以排序,但是排序只是根据顺序,而不是元素本身的排序,而元素本身的排序就需要用到红黑二叉树实现的TreeMap;
TreeMap实现了SortedMap接口,性能略低于hashmap,差不多25%的性能。
TreeMap由Comparator和Comparable确定元素的固有顺序,红黑二叉树是一种平衡查找树,统计性能高于平衡二叉树,具有良好的最坏情况运行时间,可以在O(log n)时间内做查找,插入和算法较复杂,这里不赘述,大家可以自己查阅有关资料。
1 public class Student implements Comparable<Student> { 2 private String name; 3 private int age; 4 5 public String getName() { 6 return name; 7 } 8 9 public void setName(String name) { 10 this.name = name; 11 } 12 13 public int getAge() { 14 return age; 15 } 16 17 public void setAge(int age) { 18 this.age = age; 19 } 20 21 public Student() { 22 super(); 23 } 24 25 public Student(String name, int age) { 26 super(); 27 this.name = name; 28 this.age = age; 29 } 30 31 @Override 32 public String toString() { 33 return "Student [name=" + name + ", age=" + age + "]"; 34 } 35 36 @Override 37 public int compareTo(Student o) { 38 if (o.age < this.age) 39 return 1; 40 else if (o.age > this.age) 41 return -1; 42 return 0; 43 } 44 45 }
这段代码就是展示TreeMap如何通过简易的接口实现对有序的key集合进行筛选,结果集也是个有序的map,性能相当不错,而且实现简单,这比自己实现的排序算法减少了开发成本,自己写的算法耗时耗力还可能成为性能的瓶颈。
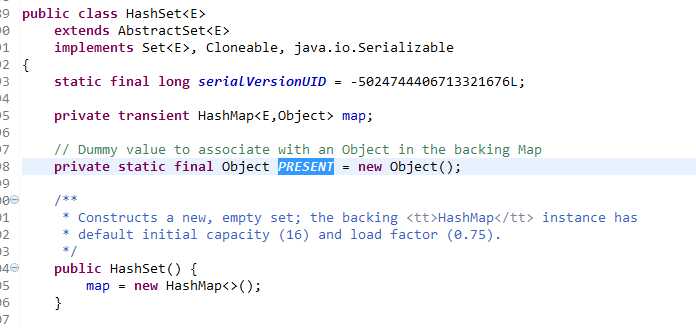
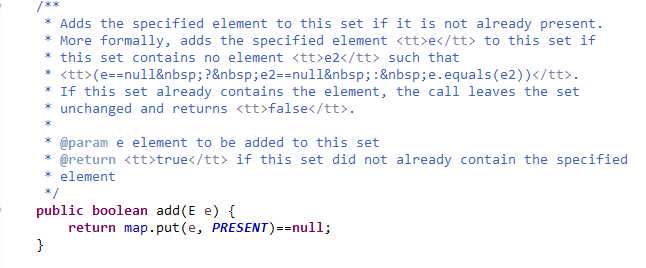
下面说一下Set,其实Set的底层就是HashMap,一切操作都是操作HashMap对象实现,一个没有什么意义的Object对象作为map对象的value,源码很明显:

也分为TreeSet,HashSet,LinkedHashSet等,不赘述前面提到的。
三:Collection遍历的小细节
关于整个Collection我说一点有意思的,就是在循环访问的时候,有一些细节的性能优化:
1 public class Testmain { 2 3 public static void main(String[] args) { 4 Collection collection = new ArrayList(); 5 for (int i = 0; i < collection.size(); i++) { 6 System.out.println(((ArrayList) collection).get(i)); 7 } 8 } 9 10 }
你比如这段代码,是常见的for循环,可以优化的地方如下:
1 public class Testmain { 2 3 public static void main(String[] args) { 4 Collection collection = new ArrayList(); 5 int num=collection.size(); 6 for (int i = 0; i < num; i++) { 7 System.out.println(((ArrayList) collection).get(i)); 8 } 9 } 10 11 }
经过修改,size()方法只被调用一次,而不会循环调用,循环体中所有的类似方法都应该这么处理,而且元素数量越多,这种处理越有意义,在ORM中也是同样原理,能丢个list绝不for循环N次。
还有一种优化,是省略重复操作,比如:
1 public class Testmain { 2 3 public static void main(String[] args) { 4 ArrayList collection = new ArrayList(); 5 collection.add("abc"); 6 collection.add("abcddd"); 7 collection.add("abcddd40"); 8 collection.add("acddd"); 9 int count = 0; 10 int num = collection.size(); 11 for (int i = 0; i < num; i++) { 12 if ((((String) collection.get(i)).indexOf("abc") != -1) 13 || (((String) collection.get(i)).indexOf("efg") != -1) 14 || (((String) collection.get(i)).indexOf("aaa") != -1)) 15 count++; 16 } 17 } 18 19 }
比如这个代码重复了三行
(((String) collection.get(i)).indexOf()
其实get(i)的值是一样的,那么可以优化为:
1 public class Testmain { 2 3 public static void main(String[] args) { 4 ArrayList collection = new ArrayList(); 5 String s = null; 6 collection.add("abc"); 7 collection.add("abcddd"); 8 collection.add("abcddd40"); 9 collection.add("acddd"); 10 int count = 0; 11 int num = collection.size(); 12 for (int i = 0; i < num; i++) { 13 if (((s = (String) collection.get(i)).indexOf("abc") != -1) 14 || (s.indexOf("abc") != -1) 15 || (s.indexOf("abc") != -1)) 16 count++; 17 } 18 } 19 20 }
通过三段代码(最初的版本,优化size版本,优化get(i)版本)的执行时间,System.nanoTime()统计,分别为:46654ns,13968ns,11454ns。都是纳秒单位,说明这种处理方式是有意义的。
还有一点有意思的,减少方法的调用,方法的调用是要消耗系统堆栈的,虽然面向对象设计模式和模块化组件设计方法鼓励程序员使用若干个小方法代替一个大方法,也就是封装抽象呗,但这是牺牲性能为代价的,
不过现代语言这些得到了很大的优化,当然我们无法追求极致的性能,所以只在有意思的地方玩玩,比如如果上段代码是Vector子类的代码,可以改写为:
1 public class VectorSon extends Vector<String> { 2 public VectorSon(int count) { 3 count = this.elementCount; 4 } 5 6 }
1 public class Testmain { 2 3 public static void main(String[] args) { 4 VectorSon collection = new VectorSon(); 5 String s = null; 6 collection.add("abc"); 7 collection.add("abcddd"); 8 collection.add("abcddd40"); 9 collection.add("acddd"); 10 int count = 0; 11 int num = this.elementCount; 12 for (int i = 0; i < num; i++) { 13 if (((s = (String) elementData[i]).indexOf("abc") != -1) 14 || (s.indexOf("abc") != -1) 15 || (s.indexOf("abc") != -1)) 16 count++; 17 } 18 } 19 20 }
我省略了很多代码,只是大概表述一下实现方式,就是说Vector子类可以直接拿到底层数组的属性,直接拿到属性就不需要调用get等方法,数组下标就可以访问到了。
直接操作对象属性会比方法效率高,size(),get()等方法,如果改为直接操作对象属性,数组的操作,那么还是有性能的提升,大概提升40%的性能,不过这种机会很少,在java里很少,java封装的太厉害了,大部分程序员不会去写太底层的东西。
集合框架的东西暂时就到这里了,最近搞一搞python跟Hystrix熔断器架构,下一篇博客打算发Hikari连接池整合JPA还有Spring boot。
标签:size 细节 abstract orm 修改 类型 保存 table 大量
原文地址:http://www.cnblogs.com/zhengyu940115/p/6656437.html