标签:any 质量 国外 iphone 第一个 break mac pro 数组 color
本节内容
列表(list)是最常用的数据类型之一,通过列表可以实现对数据的存储、修改等操作。
names = [‘Tim‘, ‘Jobs‘, ‘Jack‘]
通过下标访问列表中的元素,下标从0开始计数。
>>> names[0]
‘Tim‘
>>> names[2]
‘Jack‘
>>> names[-1]
‘Jack‘
>>> names[-2] # 倒着取
‘Jobs‘
>>>
Python中的列表与Java中的数组的比较:
Python中的数据类型list类似于Java中的数据类型数组(array);
由于Java中的数组在定义时必须声明数组变量的类型,故数组中的数组元素必须具有相同的数组类型;
而Python中的list无此限制,list中的元素可以是Python中合法的任意一种数据类型。
>>> list1 = [‘python‘, [1, ‘hello‘, {1:"world", ‘u‘:1.278}], 1, None]
>>> list1
[‘python‘, [1, ‘hello‘, {1: ‘world‘, ‘u‘: 1.278}], 1, None]
>>>
切片(slice):取多个元素

1 >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"]
2 >>> names[1:4] # 取下标1至下标4之间的数字,包括1,不包括4 [起始下标:结束下标)
3 [‘Tenglan‘, ‘Eric‘, ‘Rain‘]
4 >>> names[1:-1] # 取下标1至-1的值,不包括-1
5 [‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘]
6 >>> names[0:3]
7 [‘Alex‘, ‘Tenglan‘, ‘Eric‘]
8 >>> names[:3] # 如果是从头开始取,0可以忽略,跟上句效果一样
9 [‘Alex‘, ‘Tenglan‘, ‘Eric‘]
10 >>> names[3:] # 如果想取最后一个,必须不能写-1,只能这么写(取 >= 3的所有元素)
11 [‘Rain‘, ‘Tom‘, ‘Amy‘]
12 >>> names[3:-1] # 这样-1就不会被包含了
13 [‘Rain‘, ‘Tom‘]
14 >>> names[0::2] # 后面的2是步长,每隔一个元素,就取一个
15 [‘Alex‘, ‘Eric‘, ‘Tom‘]
16 >>> names[::2] # 和上句效果一样
17 [‘Alex‘, ‘Eric‘, ‘Tom‘]
18 >>> names[::] # 0和最后一个元素-1可省,步长为1可省略
19 [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘]
20 >>> names[:]
21 [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘]
22 >>>
追加(append)
1 >>> names
2 [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘]
3 >>> names.append(‘Newer‘)
4 >>> names
5 [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘Newer‘]
6 >>> names += [‘APPEND‘]
7 >>> names
8 [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘Newer‘, ‘APPEND‘]
9 >>>
插入(insert)
1 >>> names
2 [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘Newer‘]
3 >>> names.insert(2,‘insert before Eric.‘)
4 >>> names
5 [‘Alex‘, ‘Tenglan‘, ‘insert before Eric.‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘Newer‘]
6 >>>
修改(modify)
1 >>> names
2 [‘Alex‘, ‘Tenglan‘, ‘insert before Eric.‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘Newer‘]
3 >>> names[2] = ‘the next one‘
4 >>> names
5 [‘Alex‘, ‘Tenglan‘, ‘the next one‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘Newer‘]
6 >>>
删除(delete)
有三种不同的删除方法: del、remove、pop
三种删除方法的用法比较:
1 >>> a = [‘hello‘, ‘python‘, ‘world‘, ‘python‘, ‘superman‘, ‘is‘, ‘here‘]
2 >>> a.remove(‘python‘) # 按索引顺序,删除符合参数条件的首次出现的元素
3 >>> a
4 [‘hello‘, ‘world‘, ‘python‘, ‘superman‘, ‘is‘, ‘here‘]
5 >>> del a[1] # 删除列表索引指定的元素
6 >>> a
7 [‘hello‘, ‘python‘, ‘superman‘, ‘is‘, ‘here‘]
8 >>> a.pop(1) # 删除索引对应的列表元素,并返回删除的列表元素值
9 ‘python‘
10 >>> a
11 [‘hello‘, ‘superman‘, ‘is‘, ‘here‘]
12 >>> a.pop() # 删除最后一个元素
13 ‘here‘
14 >>> a
15 [‘hello‘, ‘superman‘, ‘is‘]
16 >>>
三种删除异常报错的比较:
1 >>> a = [4, 5, 6]
2 >>> del a[7]
3 Traceback (most recent call last):
4 File "<pyshell#23>", line 1, in <module>
5 del a[7]
6 IndexError: list assignment index out of range
7 >>> a.remove(7)
8 Traceback (most recent call last):
9 File "<pyshell#24>", line 1, in <module>
10 a.remove(7)
11 ValueError: list.remove(x): x not in list
12 >>> a.pop(7)
13 Traceback (most recent call last):
14 File "<pyshell#25>", line 1, in <module>
15 a.pop(7)
16 IndexError: pop index out of range
17 >>>
附del方法解析:
Python Class __init__ __del__ 构造,析构过程解析【转】
扩展(extend)
1 >>> names = [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘]
2 >>> b = [1, 2, 3]
3 >>> names
4 [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘]
5 >>> names.extend(b)
6 >>> del b
7 >>> names
8 [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, 1, 2, 3]
9 >>>
拷贝(copy.copy, copy.deepcopy)
由Python的浅拷贝(shallow copy)和深拷贝(deep copy)引发的思考
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 import copy
6
7 person = [‘name‘, [‘saving‘, 100]]
8 ‘‘‘
9 # shallow copy 的三种方法 只是一种引用
10 p1 = copy.copy(person)
11 p2 = person[:] # 完全切片
12 p3 = list(person) # 工厂方式
13 ‘‘‘
14
15 p1 = person[:]
16 p2 = person[:]
17
18 p1[0] = ‘alex‘
19 p2[0] = ‘fengjie‘
20
21 p1[1][1] = 50 # 用于创建联合账号
22
23 print(p1) # [‘alex‘, [‘saving‘, 50]]
24 print(p2) # [‘fengjie‘, [‘saving‘, 50]]
统计(count)
1 >>> names = [‘Alex‘, ‘Tenglan‘, ‘Amy‘, ‘Tom‘, ‘Amy‘, 1, 2, 3]
2 >>> names.count(‘Amy‘)
3 2
4 >>>
排序&翻转
1 >>> names = [‘Alex‘, ‘Tenglan‘, ‘Amy‘, ‘Tom‘, ‘Amy‘, 1, 2, 3]
2 >>> names.count(‘Amy‘)
3 2
4 >>> names.sort() # Python 3.x中list中不同数据类型的元素不能一起排序
5 Traceback (most recent call last):
6 File "<pyshell#12>", line 1, in <module>
7 names.sort()
8 TypeError: unorderable types: int() < str()
9 >>> names[-1] = ‘3‘
10 >>> names[-2] = ‘2‘
11 >>> names[-3] = ‘1‘
12 >>> names.sort()
13 >>> names
14 [‘1‘, ‘2‘, ‘3‘, ‘Alex‘, ‘Amy‘, ‘Amy‘, ‘Tenglan‘, ‘Tom‘]
15 >>> names.reverse()
16 >>> names
17 [‘Tom‘, ‘Tenglan‘, ‘Amy‘, ‘Amy‘, ‘Alex‘, ‘3‘, ‘2‘, ‘1‘]
18 >>>
19 >>> 说明names.sort()和names.reverse()修改了list对象。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author: antcolonies 4 5 data = [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66] 6 7 print(data) # [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66] 8 print(id(data)) # 32507656 9 print(data[0]) # 1 10 print(id(data[0])) # 1727051440 11 print(data[data.index(0)]) # 0 12 print(id(data[data.index(0)])) # 1727051408 13 for i in range(len(data)): 14 print(‘data[%d] : %d‘ %(i, id(data[i]))) 15 16 print(‘=======================‘) 17 18 DATA = data.sort() 19 print(DATA) # None 20 print(type(DATA)) # <class ‘NoneType‘> 21 print(id(DATA)) # 1726802688 22 print(data) # [0, 1, 3, 4, 5, 10, 25, 50, 60, 66, 72, 99] 23 print(id(data)) # 32507656 24 print(data[0]) # 0 25 print(id(data[0])) # 1727051408 26 for i in range(len(data)): 27 print(‘data[%d] : %d‘ % (i, id(data[i]))) 28 29 30 ‘‘‘ 31 在list排序操作中可以得出以下结论: 32 1、没有返回值 33 2、排序改变的只是索引关系,数据对象并未改变 34 3、变量名data指向的是数据对象的地址 35 4、数据对象索引的地址并非第一个元素的地址 36 (与C语言中数组的结构不同, 37 数组名与数组的第一个元素变量的地址索引相同, 38 且数组元素的地址是连续的) 39 ‘‘‘ 40 41 42 ‘‘‘ 43 [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66] 44 32507656 45 1 46 1727051440 47 0 48 data[0] : 1727051440 49 data[1] : 1727051504 50 data[2] : 1727051568 51 data[3] : 1727051728 52 data[4] : 1727053008 53 data[5] : 1727052208 54 data[6] : 1727053328 55 data[7] : 1727054576 56 data[8] : 1727053712 57 data[9] : 1727051408 58 data[10] : 1727051536 59 data[11] : 1727053520 60 ======================= 61 None 62 <class ‘NoneType‘> 63 1726802688 64 [0, 1, 3, 4, 5, 10, 25, 50, 60, 66, 72, 99] 65 32507656 66 0 67 data[0] : 1727051408 68 data[1] : 1727051440 69 data[2] : 1727051504 70 data[3] : 1727051536 71 data[4] : 1727051568 72 data[5] : 1727051728 73 data[6] : 1727052208 74 data[7] : 1727053008 75 data[8] : 1727053328 76 data[9] : 1727053520 77 data[10] : 1727053712 78 data[11] : 1727054576 79 ‘‘‘
获取下标(index)
1 >>> names
2 [‘Tom‘, ‘Tenglan‘, ‘Amy‘, ‘Amy‘, ‘Alex‘, ‘3‘, ‘2‘, ‘1‘]
3 >>> names.index("Amy")
4 2 #只返回找到的第一个下标
5 >>>
元组其实跟列表差不多,也是存一组数,与list不同,元组一旦创建,就不能修改,所以又叫只读列表。
语法:
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index。
>>> names = ("alex","jack","eric")
>>> names.count(‘alex‘)
1
>>> names.index(‘eric‘)
2
>>>
程序练习
程序:购物车程序
需求:
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 Salary = int(input(‘input your salary: ‘))
6 info = ‘‘‘
7 SKU Commodity Univalent
8 1 IPhone 5800
9 2 Mac Pro 12000
10 3 Starbuck Latte 31
11 4 Alex Python 81
12 5 Bike 800
13 ‘‘‘
14 GoodsList = [[‘IPhone‘,5800],
15 [‘Mac Pro‘,12000],
16 [‘Starbuck Latte‘,31],
17 [‘Alex Python‘,81],
18 [‘Bike‘,800]]
19 stat = ‘‘
20 Total = 0
21 ChooseList = []
22
23 while stat != ‘q‘:
24 print(info)
25 COM = int(input(‘add a SKU to your shoppingcar.‘))
26 COM -= 1
27 num = int(input(‘add a quantity of %s‘%(GoodsList[COM][0])))
28 Salary = Salary - GoodsList[COM][1]*num
29 if Salary <= 0:
30 print(‘balance not enough‘)
31 num = 0
32 Salary = Salary + GoodsList[COM][1] * num
33 if num != 0:
34 ChooseList.append([GoodsList[COM],num])
35 stat = input(‘choose something more?(q to finish your list,any other keys will be continue.)‘)
36
37
38 print(‘you have bought below:\n‘,ChooseList)
39 print(‘balance is %d‘%Salary)
list的相关操作:
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 names = [‘changjiang‘, ‘huanghe‘, ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
6
7 ‘‘‘ 切片
8 print(names[1])
9 print(names[0], names[1])
10 print(names[1:3]) # list切片 取值[1,3)
11 print(names[0:3]) # 子list
12 print(names[2:]) # 取出>= 3 的所有值
13 print(names[:3])
14 print(names[-1]) # 倒数第一个
15 print(names[-2:])
16 print(names[0:-1:2]) # range(1,10,2)
17 print(names[::2]) # 在切片中 0和-1可以省略,步长为2
18 print(names[:]) # 0~-1
19 for i in range(10);
20 print(i)
21
22 for i in names:
23 print(i)
24 ‘‘‘
25
26 # append
27 # names.append("huaishui") 在最后一个成员后添加
28 # insert
29 # names.insert(3,‘heisui‘) 在某成员前插入新成员
30 # modify
31 # names[3] = ‘lancangjiang‘
32 ‘‘‘ delete
33 names.remove(‘huanghe‘)
34 del names[1] 相当于 names.pop(1)
35 names.pop() 默认删除最后一个成员
36 ‘‘‘
37 # search for element position
38 # print(names.index(‘changjiang‘))
39 # print(names[names.index(‘changjiang‘)])
40 # count 统计相同成员的个数
41 # names.append(‘changjiang‘)
42 # print(names.count(‘changjiang‘))
43 # clear 清空列表成员
44 # names.clear()
45 # reverse
46 # print(names)
47 # names.reverse()
48 # sort 按ASCII排序
49 # names.sort()
50 # extend 扩展(将一个list加到另一个末尾)
51 # names2 = [‘庐山‘, ‘泰山‘, ‘黄山‘]
52 # names.extend(names2)
53 # print(names, names2)
54
55 # shallow copy 浅复制,只复制第一层
56 Names = [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘],‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
57 names2 = Names.copy()
58 names2[1] = ‘黄河‘
59 print(Names, names2)
60 # [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
61 # [‘changjiang‘, ‘黄河‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
62
63 Names[2][0] = ‘黄山‘
64 print(Names, names2)
65 # [‘changjiang‘, ‘huanghe‘, [‘黄山‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
66 # [‘changjiang‘, ‘黄河‘, [‘黄山‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
67
68 Names[2] = []
69 print(Names, names2)
70 # [‘changjiang‘, ‘huanghe‘, [], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
71 # [‘changjiang‘, ‘黄河‘, [‘黄山‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
72
73 # Deep copy
74 import copy
75
76 Names = [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘],‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
77 names3 = copy.deepcopy(Names)
78 print(‘=================‘)
79 print(Names, names3)
80 # [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
81 # [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
82 names3[2][1] = ‘五岳‘
83 print(Names, names3)
84 # [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘taishan‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
85 # [‘changjiang‘, ‘huanghe‘, [‘huangshan‘, ‘五岳‘, ‘huashan‘], ‘zhujiang‘, ‘weishui‘, ‘songhuajiang‘]
>>> will = ["Will", 28, ["Python", "C#", "JavaScript"]]
>>> print ([id(ele) for ele in will])
[55575696, 1791605264, 54852040] # 值放于列表中
>>>
特性:不可修改
1 name.capitalize() 首字母大写
2 name.upper() 字母全大写
3 name.casefold() 大写全部变小写
4 name.lower() 字母全小写
5 msg.swapcase() 大小写互换
6
7 name.center(50,"-") 输出 ‘---------------------Alex Li----------------------‘
8 name.count(‘lex‘) 统计 lex出现次数
9 name.encode() 将字符串编码成bytes格式
10 name.endswith("Li") 判断字符串是否以 Li结尾
11 "Alex\tLi".expandtabs(10) 输出‘Alex Li‘, 将\t转换成多长的空格
12 name.find(‘A‘) 查找A,找到返回其索引, 找不到返回-1
13
14 format :
15 >>> msg = "my name is {}, and age is {}"
16 >>> msg.format("alex",22)
17 ‘my name is alex, and age is 22‘
18 >>> msg = "my name is {1}, and age is {0}"
19 >>> msg.format("alex",22)
20 ‘my name is 22, and age is alex‘
21 >>> msg = "my name is {name}, and age is {age}"
22 >>> msg.format(age=22,name="ale")
23 ‘my name is ale, and age is 22‘
24 format_map
25 >>> msg.format_map({‘name‘:‘alex‘,‘age‘:22})
26 ‘my name is alex, and age is 22‘
27
28
29 msg.index(‘a‘) 返回a所在字符串的索引
30 ‘9aA‘.isalnum() True
31
32 ‘9‘.isdigit() 是否整数
33 name.isnumeric()
34 name.isprintable()
35 name.isspace()
36 name.istitle()
37 name.isupper()
38
39 "|".join([‘alex‘,‘jack‘,‘rain‘])
40 ‘alex|jack|rain‘
41
42
43 maketrans
44 >>> intab = "aeiou" #This is the string having actual characters.
45 >>> outtab = "12345" #This is the string having corresponding mapping character
46 >>> trantab = str.maketrans(intab, outtab)
47 >>>
48 >>> str = "this is string example....wow!!!"
49 >>> str.translate(trantab)
50 ‘th3s 3s str3ng 2x1mpl2....w4w!!!‘
51
52 msg.partition(‘is‘) 输出 (‘my name ‘, ‘is‘, ‘ {name}, and age is {age}‘)
53
54 >>> "alex li, chinese name is lijie".replace("li","LI",1)
55 ‘alex LI, chinese name is lijie‘
56
57
58 >>> msg.zfill(40)
59 ‘00000my name is {name}, and age is {age}‘
60
61
62
63 >>> n4.ljust(40,"-")
64 ‘Hello 2orld-----------------------------‘
65 >>> n4.rjust(40,"-")
66 ‘-----------------------------Hello 2orld‘
67
68
69 >>> b="ddefdsdff_哈哈"
70 >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则
71 True
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 name = ‘my \tname is {name} and i am {age} years old‘
6
7 print(name.capitalize())
8 print(name.count(‘a‘))
9 print(name.center(50,‘-‘))
10 print(name.endswith(‘ex‘))
11 print(name.expandtabs(tabsize=30))
12 print(name[name.find(‘name‘):])
13 print(name.format(name=‘alex‘, age=23))
14 print(name.format_map({‘name‘:‘alex‘, ‘age‘:23}))
15 print(name.index(‘is‘))
16 print(name.isalnum())
17 print(‘ab23‘.isalnum())
18 print(‘abA‘.isalpha())
19 print(‘abA‘.isdecimal())
20 print(‘abA‘.isdigit())
21 print(‘abA‘.isidentifier()) # 是否为合法的标识符(变量名是否合法)
22 print(‘33A‘.isnumeric())
23 print(‘ ‘.isspace())
24 print(‘My Name Is ‘.istitle())
25 print(‘My Name Is ‘.isprintable())
26 print(‘33q‘.islower())
27 print(‘33q‘.isupper())
28 print(‘+‘.join([‘1‘, ‘2‘, ‘3‘, ‘4‘]))
29 print(name.ljust(50,‘*‘))
30 print(name.rjust(50,‘*‘))
31 print(‘PHONE‘.lower())
32 print(‘phone‘.upper())
33 print(‘\nAlex‘.lstrip())
34 print(‘\nAlex\n‘.rstrip())
35 print(‘ \nAlex Li\n‘.strip())
36 p = str.maketrans("abcdefli",‘123$@456‘)
37 print("alex li".translate(p))
38 print(‘alex li‘.replace(‘l‘,‘L‘))
39 print(‘alex li‘.replace(‘l‘,‘L‘,1))
40 print(‘alex lil‘.rfind(‘l‘))
41 print(‘al ex li‘.split())
42 print(‘al ex li‘.split(‘l‘))
43 print(‘1+2+3+4‘.split(‘+‘))
44 print(‘1+2\n+3+4‘.splitlines())
45 print(‘Alex Lil‘.swapcase())
46 print(‘alex lil‘.title())
47 print(‘lex li‘.zfill(50))
>>> string = ‘hello,world‘ >>> id(string) 57808304 >>> id(string.upper()) # 字符串为不可变对象 57810864 >>>
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
语法:
info = {
‘stu1101‘: "TengLan Wu",
‘stu1102‘: "LongZe Luola",
‘stu1103‘: "XiaoZe Maliya",
}
字典的特性:
增加
1 >>> info["stu1104"] = "苍井空"
2 >>> info
3 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1104‘: ‘苍井空‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘TengLan Wu‘}
修改
1 >>> info[‘stu1101‘] = "武藤兰"
2 >>> info
3 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘武藤兰‘}
删除
1 >>> info
2 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘武藤兰‘}
3 >>> info.pop("stu1101") #标准删除姿势
4 ‘武藤兰‘
5 >>> info
6 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
7 >>> del info[‘stu1103‘] #换个姿势删除
8 >>> info
9 {‘stu1102‘: ‘LongZe Luola‘}
10 >>>
11 >>>
12 >>>
13 >>> info = {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
14 >>> info
15 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
16 >>> info.popitem() #随机删除
17 (‘stu1102‘, ‘LongZe Luola‘)
18 >>> info
19 {‘stu1103‘: ‘XiaoZe Maliya‘}
查找
1 >>> info = {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
2 >>>
3 >>> "stu1102" in info #标准用法
4 True
5 >>> info.get("stu1102") #获取
6 ‘LongZe Luola‘
7 >>> info["stu1102"] #同上,但是看下面
8 ‘LongZe Luola‘
9 >>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
10 Traceback (most recent call last):
11 File "<stdin>", line 1, in <module>
12 KeyError: ‘stu1105‘
13 >>> info.get(‘stu1105‘)
14 >>>
多级字典嵌套及操作
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 av_catalog = {
6 "欧美":{
7 "www.youporn.com": ["很多免费的,世界最大的","质量一般"],
8 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
9 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
10 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
11 },
12 "日韩":{
13 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
14 },
15 "大陆":{
16 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
17 }
18 }
19
20 av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
21 print(av_catalog["大陆"]["1024"])
22 #ouput
23 # [‘全部免费,真好,好人一生平安‘, ‘服务器在国外,慢,可以用爬虫爬下来‘]
24
25 print(‘=====================‘)
26 av_catalog.setdefault(‘大陆‘,{‘www.baidu.com‘:[1,2,3]}) # 该项存在,不重写
27 av_catalog.setdefault(‘taiwan‘,{‘www.baidu.com‘:[1,2,3]}) # 该项不存在,添加
28 print(av_catalog)
其它姿势
1 #values
2 >>> info.values()
3 dict_values([‘LongZe Luola‘, ‘XiaoZe Maliya‘])
4
5 #keys
6 >>> info.keys()
7 dict_keys([‘stu1102‘, ‘stu1103‘])
8
9
10 #setdefault
11 >>> info.setdefault("stu1106","Alex")
12 ‘Alex‘
13 >>> info
14 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
15 >>> info.setdefault("stu1102","龙泽萝拉")
16 ‘LongZe Luola‘
17 >>> info
18 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
19
20
21 #update
22 >>> info
23 {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
24 >>> b = {1:2,3:4, "stu1102":"龙泽萝拉"}
25 >>> info.update(b)
26 >>> info
27 {‘stu1102‘: ‘龙泽萝拉‘, 1: 2, 3: 4, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
28
29 #items
30 >>> info.items()
31 >>> dict_items([(‘stu1102‘, ‘龙泽萝拉‘), (1, 2), (3, 4), (‘stu1103‘, ‘XiaoZe Maliya‘), (‘stu1106‘, ‘Alex‘)])
32
33 # fromkeys
34 >>> c = dict.fromkeys([6,7,8],‘test‘) # 初始化字典
35 {8: ‘test‘, 6: ‘test‘, 7: ‘test‘}
36 >>> c = dict.fromkeys([6,7,8],[1,{‘name‘:‘alex‘},444]) # dict.fromkeys()创建一个字典并初始化
37 >>> print(c)
38 {8: [1, {‘name‘: ‘alex‘}, 444], 6: [1, {‘name‘: ‘alex‘}, 444], 7: [1, {‘name‘: ‘alex‘}, 444]}
39 >>> c[7][1][‘name‘] = ‘Jack Chen‘ # 初始化值中包含2或2以上的数据结构层次会出现shallow copy的情况
40 print(c)
41 {8: [1, {‘name‘: ‘Jack Chen‘}, 444], 6: [1, {‘name‘: ‘Jack Chen‘}, 444], 7: [1, {‘name‘: ‘Jack Chen‘}, 444]}
循环dict
#方法1
for key in info:
print(key,info[key])
#方法2
for k,v in info.items(): #会先把dict转成list,数据里大时建议不要使用
print(k,v)
程序练习
程序: 三级菜单
要求:
低级处理:
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 menu = {
6 "浙江省":
7 {
8 "杭州市":["上城区","下城区","江干区","拱墅区","西湖区","滨江区","萧山区","余杭区","富阳区"],
9 "宁波市":["海曙区","江东区","江北区","北仓区","镇海区","鄞州区"]
10 },
11 "广东省":
12 {
13 "广州市":["荔湾区","越秀区","珠海区","天河区","白云区","黄浦区","番禺区","花都区","南沙区","从化区","增城区"],
14 "深圳市":["罗湖区","福田区","宝安区","龙岗区","盐田区"]
15 }}
16
17 ‘‘‘
18 获取字典的keys,以列表形式返回
19 ‘‘‘
20 def catchList(dict1):
21 list1 = str(dict1.keys()).split("‘")
22 length = len(list1)
23 list2 = []
24 for i in range(length):
25 if i%2 == 1:
26 list2.append(list1[i])
27 return list2
28
29 ‘‘‘
30 将用户输入的选项值与实际值进行映射,返回实际值
31 ‘‘‘
32 def defineValue(lev,list1):
33 if lev == ‘0‘:
34 lev = list1[0]
35 elif lev == ‘1‘:
36 lev = list1[1]
37 return lev
38
39 def printList():
40 while True: # 第一层,获取省份
41 list1 = catchList(menu)
42 print("0-%s, 1-%s"%(list1[0],list1[1]))
43 lev1 = input("choose a province:(‘q‘ to quit) ")
44 if lev1 == ‘q‘:
45 return ‘quit‘
46 elif lev1 in (‘0‘,‘1‘):
47 lev1 = defineValue(lev1,list1)
48 else:
49 print(‘wrong choice!‘)
50 continue
51 while True: # 第二层,获取市
52 list2 = catchList(menu[lev1])
53 print("0-%s, 1-%s" % (list2[0], list2[1]))
54 lev2 = input(‘choose a municipality: ("q" to quit, "b" to back)‘)
55 if lev2 == ‘q‘:
56 return ‘quit‘
57 elif lev2 == ‘b‘:
58 break
59 elif lev2 in (‘0‘,‘1‘):
60 lev2 = defineValue(lev2, list2)
61 else:
62 print(‘wrong choice!‘)
63 continue
64 while True: # 第三层,获取行政区
65 list3 = menu[lev1][lev2]
66 info = ‘‘
67 i = 0
68 for string in list3:
69 info = info + ‘%d-%s \n‘%(i, string)
70 i += 1
71 print(info)
72 lev3 = input(‘choose a county: ("q" to quit, "b" to back)‘)
73 if lev3 == ‘q‘:
74 return ‘quit‘
75 elif lev3 == ‘b‘:
76 break
77 elif int(lev3) in range(i):
78 lev3 = menu[lev1][lev2][int(lev3)]
79 return ‘%s %s %s‘%(lev1, lev2, lev3)
80 else:
81 print(‘wrong choice!‘)
82 continue
83
84 print(printList())
高大上:
1 #!/usr/bin/evn python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5
6 menu = {
7 "浙江省":
8 {
9 "杭州市":{"上城区":{},"下城区":{},"江干区":{},"拱墅区":{},"西湖区":{},"滨江区":{},"萧山区":{},"余杭区":{},"富阳区":{}},
10 "宁波市":{"海曙区":{},"江东区":{},"江北区":{},"北仓区":{},"镇海区":{},"鄞州区":{}}
11 },
12 "广东省":
13 {
14 "广州市":{"荔湾区":{},"越秀区":{},"珠海区":{},"天河区":{},"白云区":{},"黄浦区":{},"番禺区":{},"花都区":{},"南沙区":{},"从化区":{},"增城区":{}},
15 "深圳市":{"罗湖区":{},"福田区":{},"宝安区":{},"龙岗区":{},"盐田区":{}}
16 }}
17
18 exit_flag = False
19 current_layer = menu
20
21 layers = [menu] # 用列表记录当前层次
22
23 address = ‘‘
24
25 while not exit_flag:
26 for k in current_layer:
27 print(k) # 获取当前层次的keys
28 choice = input(">>:").strip() # 选择下一层的入口
29 if choice == "b":
30 current_layer = layers[-1] # 返回上一层
31 # print("change to last":{}, current_layer)
32 layers.pop() #
33 elif choice == ‘q‘:
34 print(‘quit‘)
35 break
36 elif choice not in current_layer:continue
37 else:
38 layers.append(current_layer) # 将本层添加到list末尾,便于返回
39 current_layer = current_layer[choice] # 进入到下一层
40 address += ‘ %s‘%choice
41 if current_layer == {}:
42 print("it‘s the last layer!")
43 print(‘the address is %s‘%address)
44 break
集合(set)是一个无序的,不重复的数据组合,它的主要作用如下:
1 #!/usr/bin/evn python 2 # -*- coding:utf-8 -*- 3 # Author: antcolonies 4 5 # 关系测试 6 7 list_1 = [1,4,5,7,3,7,9] 8 list_1 = set(list_1) 9 10 list_2 = set([2,6,0,66,22,8,4]) 11 print(list_1, list_2) 12 13 # 交集 14 print(list_1.intersection(list_2)) 15 print(list_1 & list_2) 16 17 # 并集 18 print(list_1.union(list_2)) 19 print(list_1 | list_2) 20 21 # 差集 in list_1 and not in list_2 22 print(list_1.difference(list_2)) 23 print(list_1 - list_2) 24 print(list_2.difference(list_1)) 25 print(list_2 - list_1) 26 27 # 子集与超集 28 list_3 = set([1,3,7]) 29 list_4 = set([1,4,5,7,3,7,9]) 30 print(list_1.issuperset(list_2)) 31 print(list_1.issubset(list_2)) 32 print(‘===============‘) 33 print(list_3.issubset(list_1)) # True 34 print(list_3 < list_1) # True 35 print(list_1.issuperset(list_3)) # True 36 print(list_1 >= list_3) # True 37 print(list_1 >= list_4) # True 38 print(list_4 <= list_1) # True 39 print(list_1 == list_4) # True 40 print(list_1 is list_4) # False 41 42 # 对称差集 43 print(list_1.symmetric_difference(list_3)) 44 print(list_1 ^ list_3) 45 46 # 列表是否有交集 47 print(list_1.isdisjoint(list_3)) 48 print(list_2.isdisjoint(list_3)) 49 50 # update 51 list_1.add(999) 52 list_1.update([10,37,42]) 53 print(list_1) 54 55 # delete 56 print(list_1.pop()) # Remove and return an arbitrary set element. 57 # print(list_1.remove(‘dddddd‘)) 58 # print(list_1.discard(‘ddddddd‘)) 59 # del list_1
参见: http://www.cnblogs.com/ant-colonies/p/6637121.html
参考文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
需知:
1.默认编码:
Python2 ASCII
Python3 Unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), utf-16是目前最常用的unicode版本, 然而文件保存的是utf-8(节省空间)。
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string。
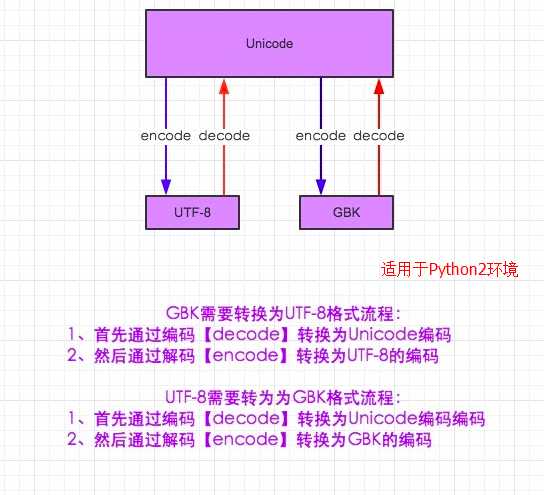
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import sys 5 print(sys.getdefaultencoding()) 6 7 8 msg = "我爱北京天安门" 9 msg_gb2312 = msg.decode("utf-8").encode("gb2312") 10 gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") 11 12 print(msg) 13 print(msg_gb2312) 14 print(gb2312_to_gbk) 15 print(msg_gb2312.decode(‘gb2312‘)) 16 print(gb2312_to_gbk.decode(‘gbk‘)) 17 18 ‘‘‘ 19 ascii???????? 20 我爱北京天安门??? 21 ?°?±±???°2???????? 22 ?°?±±???°2???????? 23 我爱北京天安门 24 我爱北京天安门 25 ‘‘‘
1 #!/usr/local/Python-3.5.2/python 2 # -*- coding:utf-8 -*- 3 # 4 5 import sys 6 print(sys.getdefaultencoding()) 7 8 9 msg = "我爱北京天安门" 10 #msg_gb2312 = msg.decode("utf-8").encode("gb2312") 11 msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔 12 gb2312_to_unicode = msg_gb2312.decode("gb2312") 13 gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") 14 15 print(msg) 16 print(msg_gb2312) 17 print(gb2312_to_unicode) 18 print(gb2312_to_utf8) 19 20 ‘‘‘ 21 utf-8 22 我爱北京天安门 23 b‘\xce\xd2\xb0\xae\xb1\xb1\xbe\xa9\xcc\xec\xb0\xb2\xc3\xc5‘ 24 我爱北京天安门 25 b‘\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8‘ 26 ‘‘‘
标签:any 质量 国外 iphone 第一个 break mac pro 数组 color
原文地址:http://www.cnblogs.com/ant-colonies/p/6597856.html
