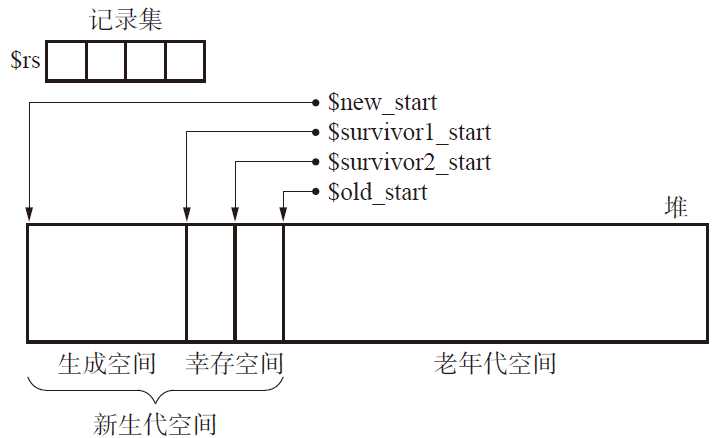
标签:理解 ges 设置 rri 内存 bar start 起点 复杂
write_barrier(obj, field, new_obj) { if obj >= $old_start && new_obj < $old_start && obj.remembered == false // 条件,很明显 $rs[$rs_idx++] = obj // 更新记录集 obj.remembered = true // 这标记用于防止重复加入记录集 *field = new_obj // 最终更新 }
从上面可见,老年代的对象中,加了一个域:remembered,用来标记是否在新生代的记录集中,防止重复处理。
new_obj(size) { if $new_free + size >=$survivor1_start minor_gc() // 后面重点介绍,新生代回收!!! if $new_free + size >=$survivor1_start fail() obj = $new_free $new_free += size // 下面是初始化 obj.age = 0 obj.forwarded = obj.remembered = false obj.size = size return obj }
copy(obj) { if obj.forwarded == false // 处理过的对象不关心,因为已经是垃圾了。 if obj.age < AGE_MAX // 判断拷到哪一代 copy_data($to_suvivor_free, obj, obj.size) obj.forwarded = true obj.forwarding = $to_suvivor_free $to_suvivor_free.age++ $to_suvivor_free += obj.size for child : children(obj.forwarding) // 注意是forwarding,原书上应该错了!拷贝并更新各子对象 child = copy(child) else promote(obj) // 升级 return obj.forwarding } promote(obj) { new_obj = allocate_in_old(obj) if new_obj == NULL major_gc() // mark_sweep,没什么好说 new_obj = allocate_in_old(obj) if new_obj == NULL fail() // 新生代内老对象上正常更新 obj.forwarding = new_obj obj.forwarded = true // 下面是关键,跨代复制后,需要更新记录集 for child : children(new_obj) if (child < $old_start) // 当前对象已经复制到老年代,一旦发现其中有一个子对象在新生代,更新新生代的记录集 $rs[$rs_idx++] = new_obj // 如前所说,记录集内记录的,必须是老年代中的对象 new_obj.remembered = true return // 只需要找到一个,就可以退出不再处理了 }
是时候回头看一下新生代GC了:
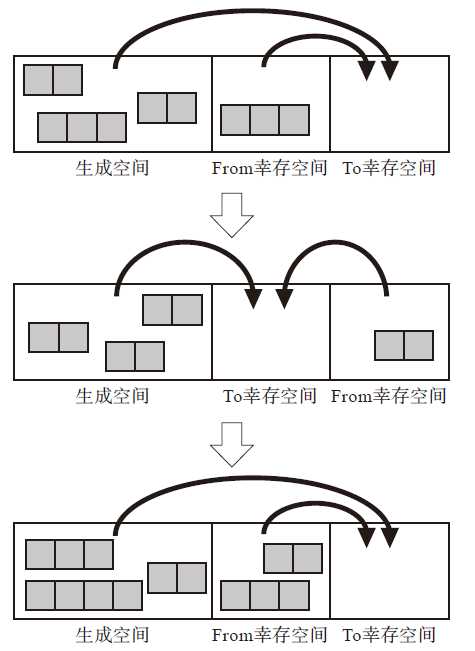
minor_gc() { $to_survivor_free = $to_survivor_start for r : $root // 复制算法,就是从根开始将有用的都拷走 if r < $old_start // 相对一般复制算法的区别,要判断分代 r = copy(r) // 另一个与正常复制算法的区别,是记录集中的老年代,也要当作根处理 i = 0 while i < $rs_idx has_new_obj = false for child : children($rs[i]) if child < $old_start // 找到了一个子对象在新生代,需要将其复制走 child = copy(child) if child < $old_start // 复制完仍在新生代(另一可能是,复制过程中,age满了被复制到老年代!) has_new_obj = true // 记录,意味着,当前这条记录集仍要保留 if has_new_obj == false // 需要将记录集中记录干掉 $rs[i].remembered = false $rs_idx-- swap($rs[i], $rs[$rs_idx]) else i++ swap($from_survivor_start, $to_suvivor_start) }
以上便是新生代回收算法。有一些额外逻辑,如to空间满了怎么办,直接拷到老年代也行。
// 往老年代的某一car上复制,逻辑不复杂 copy(obj, to_car) { if obj.forwarded == false if to_car.free + obj.size >= to_car.start + CAR_SZ to_car = new_car(to_car) copy_data(to_car.free, obj, obj.size) obj.forwarding = to_car.free obj.forwarded = true to_car.free += obj.size for child : children(obj.forwarding) child = copy(child, to_car) // 引用关系的,都往同一car拷。后面可看到,即使car空间不足重分配,那也是在同一train内的。 return obj.forwarding }
再看是怎么调用的,怎么把引用关系的对象缕到一起的:
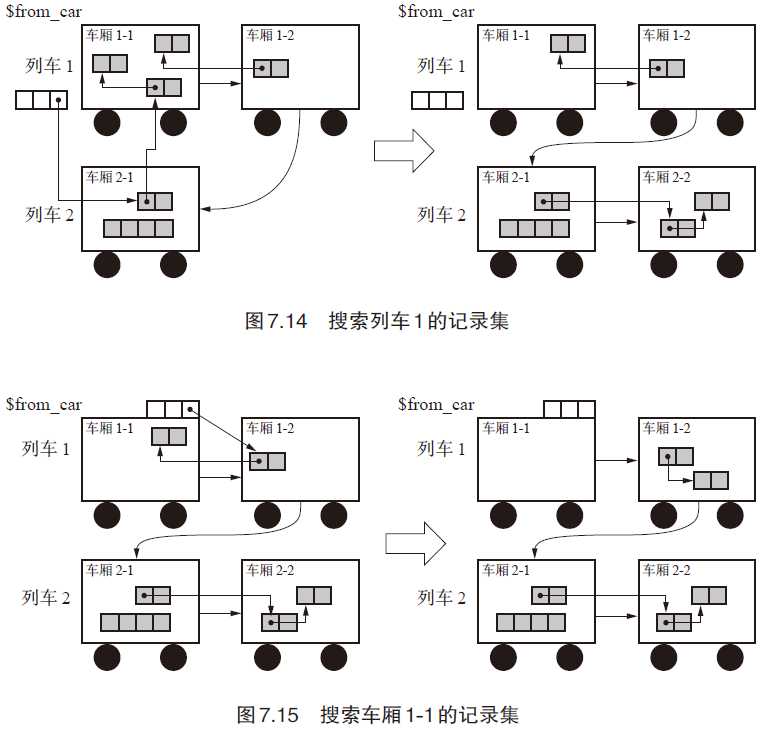
minor_gc() { // root引用的,就不管了,先拷到一个新car再说(老年代回收自会处理) to_car = new_car(NULL) // new_car(NULL)这个操作,不仅会创建新car,也会创建一个新train!!!!!!!!!!!!!!!!!!!! for r : $root if r < $old_start r = copy(r, to_car) // 从记录集引用来的,说明老年代中必有引用它的对象,直接找到对应车厢即可 for remembered_obj : $young_rs for child : children(remembered_obj) if child < $old_start to_car = get_last_car(obj_to_car(rememberd_obj)) //关键点:两个操作,1找到引用它的老年对象所在car,2找到对应car所在train的最后一个car child = copy(child, to_car) }
上面有一个逻辑要关注,从root引用的对象,是复制到新火车的,而从记录集引用的对象,是拷贝到引用所在的火车。
major_gc() { has_root_reference = false to_car = new_car(NULL) // 注意,新火车 // 先处理根出发的对象 for r : $roots if is_in_from_train(r) // 只处理这个from_train,这个from_train是第一个train has_root_reference = true // from_train中,存在着从根来的引用。这意味着,将它拷到train中的后面car后,本train仍然是被root引用的 if is_in_from_car(r) // 同样只处理from_car,这个from_car是from_train中的第一个car r = copy(r, to_car) // 移走到新火车中 // 处理到这里后,第一train中第一车厢的根引用的活动对象,都已经拷走,拷到新火车中! // 这里这个额外的判断,很重要 if !has_root_reference && is_empty(train_rs($from_car)) // 火车回收算法的核心逻辑:如果,本列车已经没有从根的引用,也没有从其他列车的引用,说明这是一整车垃圾,而不仅仅是一车厢!可以全部回收。循环引用也可以在这里被回收!!! reclaim_train($from_car) return // 处理从记录集出发的引用对象。如果有从其他火车的引用,要进行各种调整。 scan_rs(train_rs($from_car)) scan_rs(car_rs($from_car)) add_to_freelist($from_car) // 当前这from_car是可以回收了 $from_car = $from_car.next } // 火车算法的核心逻辑:将从记录集出发的引用对象归整到同一火车 scan_rs(rs) { for remembered_obj : rs for (child : rememberd_obj) if is_in_from_car(child) to_car = get_last_car(obj_to_car(remembered_obj)) // 移动到引用它对象同一个train child = copy(child, to_car) }
最后,看一下wirte_barrier
// 这里的操作是obj.field = new_obj这样的 write_barrier(obj, field, new_obj) { if obj >= $old_start if new_obj < $old_start // 老年代引用新生代,简单 add(obj, $young_rs) else // 老年代引用老年代,就有点逻辑 src_car = obj_to_car(obj) // 这里的src, dest是引用的关系 dest_car = obj_to_car(new_obj) if src_car.train_num > dest_car.train_num add(obj, train_rs(dest_car) else if src_car.car_num > dest_car.car_num add(obj, car_rs(dest_car) //上面两上不完全的判断条件看似漏了一些分支未处理,但其实是不需要处理的。因为垃圾回收过程从前往后进行,只会关心这里的两种从后往前的引用方式。 field = new_obj }
标签:理解 ges 设置 rri 内存 bar start 起点 复杂
原文地址:http://www.cnblogs.com/qqmomery/p/6659823.html