标签:attr 配置环境变量 bsp time spi height eth urlopen htm
1.安装Python环境
官网https://www.python.org/下载与操作系统匹配的安装程序,安装并配置环境变量
2.IntelliJ Idea安装Python插件
我用的idea,在工具中直接搜索插件并安装(百度)
3.安装beautifulSoup插件
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#attributes
4.爬虫程序:爬博客园的闪存内容
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2
import time
import bs4
‘‘‘ing.cnblogs.com爬虫类‘‘‘
class CnBlogsSpider:
url = "https://ing.cnblogs.com/ajax/ing/GetIngList?IngListType=All&PageIndex=${pageNo}&PageSize=30&Tag=&_="
#获取html
def getHtml(self):
request = urllib2.Request(self.pageUrl)
response = urllib2.urlopen(request)
self.html = response.read()
#解析html
def analyze(self):
self.getHtml()
bSoup = bs4.BeautifulSoup(self.html)
divs = bSoup.find_all("div",class_=‘ing-item‘)
for div in divs:
img = div.find("img")[‘src‘]
item = div.find("div",class_=‘feed_body‘)
userName = item.find("a",class_=‘ing-author‘).text
text = item.find("span",class_=‘ing_body‘).text
pubtime = item.find("a",class_=‘ing_time‘).text
star = item.find("img",class_=‘ing-icon‘) and True or False
print ‘( 头像: ‘,img,‘昵称: ‘,userName,‘,闪存: ‘,text,‘,时间: ‘,pubtime,‘,星星: ‘,star,‘)‘
def run(self,page):
pageNo = 1
while (pageNo <= page):
self.pageUrl = self.url.replace(‘${pageNo}‘, str(pageNo))+str(int(time.time()))
print ‘-------------\r\n第 ‘,pageNo,‘ 页的数据如下:‘,self.pageUrl
self.analyze()
pageNo = pageNo + 1
CnBlogsSpider().run(3)
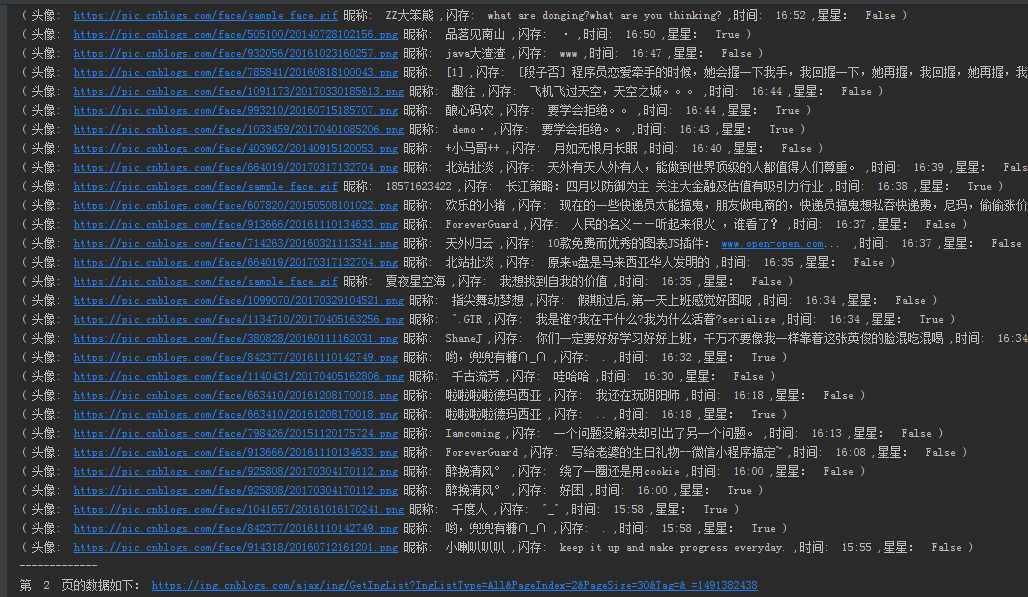
5.执行结果
标签:attr 配置环境变量 bsp time spi height eth urlopen htm
原文地址:http://www.cnblogs.com/itechpark/p/python_spider_cnblogs.html