标签:img node server com tab ast sql语句 笔记 删除重复数据
1. MERGE用法:关联两表,有则改,无则加
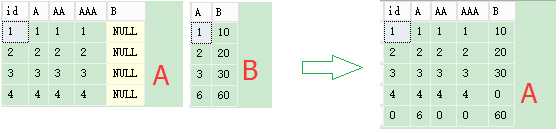
SQL语句:
create table #AAA(id int,A int,AA int,AAA int,B int) create table #BBB(A int,B int) insert into #AAA select 1,1,1,1,null union select 2,2,2,2,null union select 3,3,3,3,null union select 4,4,4,4,null insert into #BBB select 1,10 union select 2,20 union select 3,30 union select 6,60 merge into #AAA as t using (select * from #BBB where A<30 )as s on s.A=t.A when matched then update set t.B=s.B when not matched by target then insert values(0,s.A,0,0,s.B) when not matched by source then update set t.B=0 output $action as [Action], Inserted.id as InsertId, Inserted.B as InsertB, Deleted.id as DeletedId, Deleted.B as DeletedB;
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/bb510625.aspx
2. ROW_NUMBER用法:分组取第一行
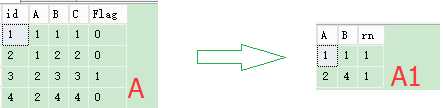
SQL语句:
create table #AAA(id int,A int,B int,C int,Flag int) insert into #AAA values(1,1,1,1,0),(2,1,2,2,0),(3,2,3,3,1),(4,2,4,4,0) select * from (select A,B,rn=ROW_NUMBER() over (partition by A order by C) from #AAA where Flag=0) t0 where rn=1 drop table #AAA
扩展用法:
1. 删除重复数据,思路:按照一定的排序保留第一条,删除rn>1的数据。
2. row_Number的Over语句中,如果不想做排序操作,可以输入order by(select null)
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms186734.aspx
3. READPAST大用
说明:READPAST是一个table hints,实际应用场景可以是多线程处理一批任务,Update/Delete任务时用ReadPast可以跳过行锁,提高效率。
SQL语句:
DELETE a OUTPUT deleted.* FROM dbo.Test a WITH (UPDLOCK, READPAST)
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms187373.aspx
4. CTE(公用表表达式):优雅清晰的代码
SQL语句:
create table #AAA(orderId varchar(20), packId varchar(20), skuId varchar(20), resentSign bit, resent int) create table #BBB(orderId varchar(20), skuId varchar(20), resent int) insert into #AAA values (‘S01‘,‘P01‘,‘A‘,null,null) ,(‘S03‘,‘P01‘,‘C‘,1,20) ,(‘S01‘,‘P02‘,‘A‘,null,null) ,(‘S01‘,‘P01‘,‘B‘,null,null) ,(‘S02‘,‘P01‘,‘A‘,null,null) ,(‘S02‘,‘P03‘,‘B‘,null,null) insert into #BBB values (‘S01‘,‘A‘,10) ;with cteTest as ( select t3.*,t2.resent as newResent from (select t1.packId,t1.SkuId,t0.resent from (select orderId,skuId,resent from #BBB) t0 left join (select orderId,packId,SkuId from #AAA)t1 on t1.orderId=t0.orderId and t1.SkuId=t0.skuId) t2 left join (select * from #AAA where resentSign is null) t3 on t3.packId=t2.packId and t3.SkuId=t2.SkuId ) update cteTest set ResentSign=1, resent=newResent
提示:
1. with前如果有SQL语句,必须以;结尾,否则报错,因此可以习惯在With前加;的写法。
2. with加上merge的写法,更加优雅。但是值得注意的是,merge的表对象可以用with过滤查找,但MS官方不推荐这么做,有失败的风险。
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms175972.aspx
5. 探究SQL中的null和空字符
SQL语句:
declare @testOne nvarchar(30) set @testOne=‘ ‘ select @testOne as Content ,case when @testOne = ‘ ‘ then ‘ = empty‘ else ‘= empty false‘ end as EmptyTest ,case when @testOne != ‘ ‘ then ‘!= empty‘ else ‘!= empty false‘ end as NotEmptyTest ,case when @testOne = null then ‘= Null‘ else ‘= Null false‘ end as NotEmptyTest ,case when @testOne != null then ‘!= Null‘ else ‘!= Null false‘ end as NotNullTest

6. STUFF:查询group并串联String
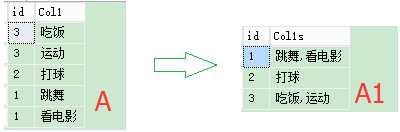
SQL语句:
create table #AAA(id int, Col1 varchar(10)) insert into #AAA values (3,‘吃饭‘),(3,‘运动‘),(2,‘打球‘),(1,‘跳舞‘),(1,‘看电影‘) Select distinct ST2.id, stuff((Select ‘,‘+Col1-- as [text()]--无列名 From #AAA ST1 Where ST1.id = ST2.id For XML PATH (‘‘) ),1,1,‘‘) Col1s From #AAA ST2 drop table #AAA
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms190922.aspx
7. OUTPUT用法:增删改的同时OUTPUT数据

SQL语句:
create table #OldData(id int, A varchar(30), B varchar(30)) create table #IdMap(OldId int,[NewId] uniqueidentifier) create table #NewData(id uniqueidentifier, A varchar(30), B varchar(30), oldId int) insert into #OldData values (1,‘A‘,‘B‘),(2,‘Ads‘,‘Bwe‘),(3,‘frA‘,‘erB‘),(4,‘erA‘,‘Bty‘) --写入新数据同时写到Id映射表 insert into #NewData output inserted.OldId,inserted.id AS [NewId] into #IdMap select newid() as newGuid,A,B,id from #OldData drop table #OldData drop table #IdMap drop table #NewData
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms177564.aspx
8. CTE递归一
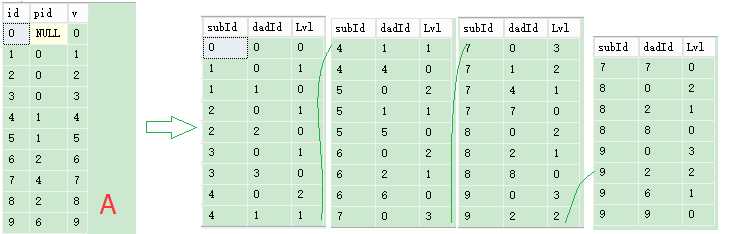
如上如:A表为一个树形结构:
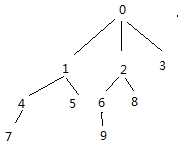
目标:将结构打散成二级,结果数据为:节点,父节点,父子深度。
SQL语句:
create table #AAA(id int, pid int,v int) insert into #AAA values (0,null,0),(1,0,1),(2,0,2),(3,0,3),(4,1,4),(5,1,5),(6,2,6),(7,4,7),(8,2,8),(9,6,9) SELECT * FROM #AAA ;with cte as ( select Id,Pid,0 as lvl,Id as flag from #AAA union all select d.Id,d.Pid,lvl+1,c.flag from cte c inner join #AAA d on d.Id = c.Pid where c.lvl<10--这里加2表示只取2次递归的结果。 ) select flag AS subId,Id AS dadId, Lvl FROM cte ORDER BY cte.flag,cte.lvl desc drop table #AAA
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms175972.aspx
9. CTE递归二
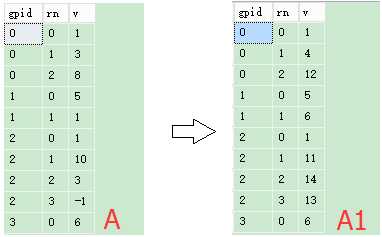
目标:将数据分组并向上累加。V(0,0)=1,V(0,1)=3,V(0,2)=8处理成V(0,0)=1,V(0,1)=3+1=4,V(0,2)=8+3+1=12
SQL语句:
create table #AAA(gpid int, rn int, v int) insert into #AAA values (0,0,1),(0,1,3),(0,2,8),(1,0,5),(1,1,1),(2,0,1),(2,1,10),(2,2,3),(2,3,-1),(3,0,6) ;with cte as ( select gpid,rn,v from #AAA WHERE rn=0 union all select d.gpid,d.rn,d.v+c.v AS v FROM cte c inner join #AAA d on d.gpid = c.gpid AND d.rn =c.rn+1 ) SELECT * FROM cte ORDER BY gpid,cte.rn DROP table #AAA
详细说明和更多用法参见:https://msdn.microsoft.com/zh-cn/library/ms175972.aspx
10.解析xml子数据并join到父数据

目标:将父数据中的xml子数据解读并对每条子数据生成一条包含父数据信息的数据行
SQL语句:
---- 创建函数解析xml成table --alter FUNCTION [dbo].[F_GetDetails] --( -- @detailxml nvarchar(4000) --) --RETURNS @t TABLE(id int, amount DECIMAL(12,4)) --AS --BEGIN -- --解析xml -- declare @xml xml -- set @xml=cast(@detailxml as xml) -- INSERT INTO @t -- select T.c.value(‘@id‘,‘int‘) as Id, -- T.c.value(‘@amount‘,‘decimal(12,4)‘) as Amount -- from @xml.nodes(‘As/A‘) as T(c) -- RETURN; --END DECLARE @tmp TABLE(id INT,name NVARCHAR(30),xmlDetail NVARCHAR(1000)) INSERT INTO @tmp VALUES (1, ‘A‘,N‘<?xml version="1.0" encoding="utf-16"?> <As> <A id="1" amount="1.3900" /> <A id="2" amount="19.0000" /> <A id="3" amount="2.2200" /> </As>‘) ,(2, ‘B‘,N‘<?xml version="1.0" encoding="utf-16"?> <As> <A id="4" amount="9.3600" /> <A id="5" amount="10.5000" /> <A id="6" amount="2.1500" /> </As>‘) SELECT * FROM @tmp a CROSS apply dbo.[F_GetDetails](a.xmlDetail) b
详细说明和更多用法参见: https://msdn.microsoft.com/zh-cn/library/ms177634.aspx
未完待续。。。。
转载请注明出处:http://www.cnblogs.com/icyj
标签:img node server com tab ast sql语句 笔记 删除重复数据
原文地址:http://www.cnblogs.com/icyJ/p/SQL_Statement.html