标签:ima equal 存在 main written 但我 字节 整理 eth
好记性不如烂笔头,就拿Java IO来说吧,这部分的基础类我大学都已经学过一遍了,但是现在忘记的差不多了,所以准备写一篇博客,讲这些东西都回忆一下,并且整理一下。
首先借用网上的一张图: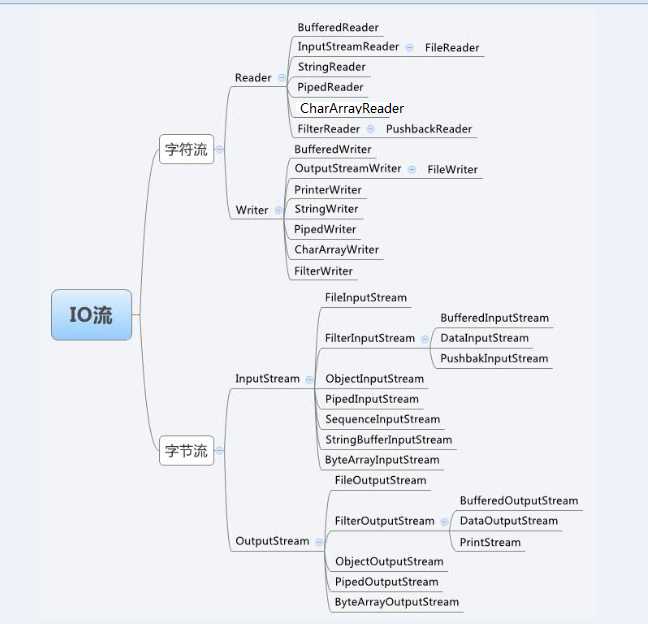
纵向分为字节流和字符流.横向分为针对读写进行划分
在这幅图中那些非常基本的也就不提了,就提一下需要注意的几个类。
1.BufferedXXX 缓冲 无论是读还是写,字符还是字节流都存在,主要是作为一个缓冲的作用,起到的作用是减少和操作系统的IO交互,减少性能消耗
2.PipedXXX 管道 管道也是存在这四个当中,管道的用法相当于我们使用的队列,你往其中塞入数据的话,那么从另一端就可以取出来,否则就会堵塞,下面使用字符流的输入流作为例子:
package com.hotusm.io.learn.string; import java.io.PipedReader; import java.io.PipedWriter; /** * 字符流取出管道 * 1.PipedReader(PipedWriter src, int pipeSize) 第一个参数为输入管道流 第二个参数为管道的大小 * 如果没有第二个参数那么默认的管道大小为1024 * 2.PipedReader() 没有参数的构造函数为还没初始化的状态 需要调用connect(PipedWriter src) * 3.read() 会进行堵塞 直到有数据流到达 然后在进行读取 */ public class PipedReaderTest { public static void main(String[] args) throws Exception{ testPipedReaderConnect(); } public static void testPipedReaderConnect() throws Exception{ PipedReader pipedReader=new PipedReader(); final PipedWriter writer=new PipedWriter(); //这种方式进行连接 pipedReader.connect(writer); char[] buff=new char[10]; new Thread(()->{ try { //停留三秒钟之后 Thread.sleep(3000); writer.write("hello piped"); } catch (Exception e) { e.printStackTrace(); } }).start(); pipedReader.read(buff); System.out.println(buff); } }
。
3.字符流中独有的InputStreamReader 和OutputStreamWriter 。 使用适配器模式将字节流适配成字符流,这样就可以将字节流作为字符流使用。
4.输入流中特有的PushbackXXX 看上图种都是继承自XXXFilter ,它们都是=使用了装饰模式为读取的时候增加了回退的功能.下面使用字符形式展示其作用:
package com.hotusm.io.learn.string; import java.io.CharArrayReader; import java.io.PushbackReader; /** * PushbackReader 能够将流或者字符进行回推到 缓冲区中. 1.PushbackReader(Reader reader,int size) * size: 每一次的read()的个数 ,默认是1 同时也是缓冲区的大小 2.unread()重载方法 * 将一个或者多个的字符回推到缓冲区中,位置就是上一次读过的结尾 比如 abcd 读到c 现在推出gf 那么就是为 abcgfd 下次读的话 就会从 * gf开始读 3.skip(long size) 跳过size 个字符 */ public class FilterReaderAndPushbackReaderTest { public static void main(String[] args) { testFilterReaderUnreadSingleChar(); System.out.println(); testFilterReaderUnreadMutilChar(); testFilterReaderSkip(); } /** * 输出:abcCd */ public static void testFilterReaderUnreadSingleChar() { String str = "abcd"; try (CharArrayReader charArrayReader = new CharArrayReader(str.toCharArray()); PushbackReader pushbackReader = new PushbackReader(charArrayReader);) { int c; while ((c = pushbackReader.read()) != -1) { System.out.print((char) c); // unread()的用法 将字符给回推到缓冲区中 if (c == ‘c‘) { pushbackReader.unread(‘C‘); } } } catch (Exception e) { e.printStackTrace(); } } /** * 输出:abcdefFUCgUC */ public static void testFilterReaderUnreadMutilChar() { String str = "abcdefg"; try (CharArrayReader charArrayReader = new CharArrayReader(str.toCharArray()); PushbackReader pushbackReader = new PushbackReader(charArrayReader, 3);) { char[] byteArr = new char[3]; // read方法会一直读入构造函数中第二个参数中的数量的字符 while ((pushbackReader.read(byteArr)) != -1) { System.out.print(byteArr); // unread()的用法 将字符给回推到缓冲区中 if (new String(byteArr).equals("def")) { // 推回的不能大于缓冲区的 缓冲区就是我们构造函数的第二个参数 pushbackReader.unread("FUC".toCharArray()); } } } catch (Exception e) { e.printStackTrace(); } } /** * 输出:abcfg */ public static void testFilterReaderSkip() { String str = "abcdefg"; try (CharArrayReader charArrayReader = new CharArrayReader(str.toCharArray()); PushbackReader pushbackReader = new PushbackReader(charArrayReader, 3);) { char[] byteArr = new char[3]; // read方法会一直读入构造函数中第二个参数中的 while ((pushbackReader.read(byteArr)) != -1) { System.out.print(byteArr); //这里是重点!!! pushbackReader.skip(2L); byteArr = new char[3]; } } catch (Exception e) { e.printStackTrace(); } } }
5.输出流中特有的两个PrintWriter和PrintStream,和前面不同的是,这两个除了一个是字符一个是字节之外,还有其他的不同点.它们也要一些相似点.下面一一来展示。
当我们使用PrintWriter的时候,但我们设置了能够自动刷新的话,那么只有在println,printf,format方法调用的时候才会起作用,这点和字节流的PrintStream是不同的。下面是源码中的描述:
* <p> Unlike the {@link PrintStream} class, if automatic flushing is enabled
* it will be done only when one of the <tt>println</tt>, <tt>printf</tt>, or
* <tt>format</tt> methods is invoked, rather than whenever a newline character
* happens to be output. These methods use the platform‘s own notion of line
* separator rather than the newline character.
而PrintStream是是要调用了println或者是字符中进行了换行(‘\n‘)就会自动的刷新,这是和字符流中的不同点。源码中这样描述:
<code>PrintStream</code> can be created so as to flush * automatically; this means that the <code>flush</code> method is * automatically invoked after a byte array is written, one of the * <code>println</code> methods is invoked, or a newline character or byte * (<code>‘\n‘</code>) is written.
参考: http://www.cnblogs.com/oubo/archive/2012/01/06/2394638.html
标签:ima equal 存在 main written 但我 字节 整理 eth
原文地址:http://www.cnblogs.com/zr520/p/6682454.html