标签:gbk span decode 使用 方案 计算 unicode编码 form div
计算机中的所有数据都是二进制数
python2中默认的是编码格式是ASCCI码,python3中默认的编码格式是UTF-8
可以通过以下代码查看当前的编码格式:
import sys
print(sys.getdefaultencoding())#输出当前的编码格式
字符编码转换
很多其它国家都搞出自己的编码标准,彼此间却相互不支持。这就带来了很多问题。于是,国际标谁化组织为了统一编码:提出了标准编码准则:UNICODE 。
UNICODE是用两个字节来表示为一个字符,它总共可以组合出65535不同的字符,这足以覆盖世界上所有符号(包括甲骨文)
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据
不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。
这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦!
这也是为什么utf8是我们的推荐编码方式。
Unicode与utf8的关系:
一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
UTF-8与GBK之间的转换:
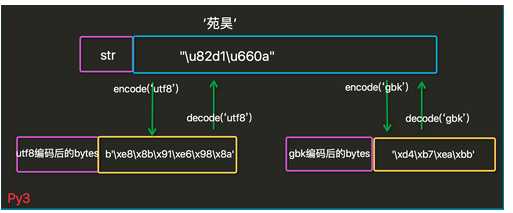
Unicode(encode)--->UTF-8
UTF-8(decode)-->Unicode
Unicode(encode)-->GBK
GBK(decode)-->Unicode
编码格式相互转换时需要在decode()和encode里面明确说明当前的编码格式以及要转换成的格式
python3中默认的是 utf-8
GBK转换成UTF-8格式流程:
1、首先通过解码【decode】转换成Unicode编码
2、然后通过编码【encode】转换成UTF-8
GBK(decode)-->Unicode(encode)-->UTF-8
GBK.decode("gbk").encode("utf-8")
decode()里面的参数是现在的编码格式,encode()里面的参数是要转换成的编码格式
UTF-8转换成GBK的格式流程:
1、首先通过解码【decode】转换成Unicode编码
2、然后通过编码【encode】转换成UTF-8
UTF-8(decode)-->Unicode(encode)-->GBK
UTF-8.decode("utf-8").encode("gbk")
注意:在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string

import sys print(sys.getdefaultencoding()) msg = "我爱你中国" #utf-8准换gbk 其实通过一次uft-8编码成gbk格式 s_to_gbk=msg.encode("gbk")#默认就是utf-8,不用再decode,喜大普奔 print(s_to_gbk) #gbk转换utf-8 gbk先解码成unicode格式再编码成uft-8 s_to_utf8=s_to_gbk.decode("gbk").encode("utf-8") print(s_to_utf8) #中文输出 utf-8再解码输出 utf_print=msg.encode("gb2312").decode("gb2312").encode("utf-8").decode("utf-8") print(utf_print)
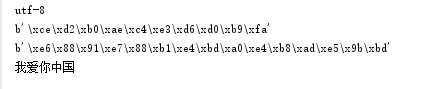
代码的输出结果
标签:gbk span decode 使用 方案 计算 unicode编码 form div
原文地址:http://www.cnblogs.com/WhatTTEver/p/6682675.html
