标签:优先 sts select min 资源 字符 匹配 字段 lib
1、基本查询语句
SELECT 属性列表 FROM <表名 | 视图列表>
[WHERE 条件表达式1]
[GROUP BY 属性名1 [HAVING 条件表达式2]]
[ORDER BY 属性名2 [ASC | DESC]]
解释:
A)属性列表:属性1, 属性2, ... ... 属性n
B)属性1 = 100
C)GROUP BY:把字段中的数据进行分组
D)[HAVING 条件表达式2]]:满足条件表达式2的行会被输出
E)ORDER BY:排序,ASC为升序,DESC为降序
例:SELECT id, name, age, sex
FROM 学生表
WHERE age < 25
ORDER BY id ASC;
2、 单表查询
a) 查询表中所有字段
SELECT * FROM 表名;
b) 查询表中指定字段
SELECT 属性1, 属性2, ... ... 属性n FROM 表名;
3、 限制查询
SELECT * FROM 表名
WHERE 条件表达式;
|
条件表达式的组成 |
|
|
比较 |
=、>、<、>=、<=、!=、<>、!>、!< |
|
指定范围 |
BETWEEN AND、NOT BETWEEN AND |
|
指定集合 |
IN、NOT IN |
|
匹配字符 |
LIKE、NOT LIKE |
|
是否为空 |
IS NULL、 IS NOT NULL |
|
多个条件表达式的组合 |
AND、OR |
A)IN的用法
属性名 IN (元素1, 元素2, 元素3)
解释:属性只能是集合中的一种。
B)BETWEEN AND的用法
属性名 BETWEEN 取值1 AND 取值2
解释: 等价于 取值1 <= 属性名 && 属性名 <= 取值2
C)LIKE的用法
属性名 LIKE ‘AAA%BBB_D’
解释:字符串匹配,其中 ’%’ 表示任意个字符, ’_’ 表示一个字符
注:耗费系统资源,不推荐使用
D)IS NULL的用法
属性名 IS NULL
解释:当属性的值为空时,表达式为真
E)AND OR的用法
(表达式1 )AND (表达式2 OR 表达式3)
解释:括号可以控制优先级
默认情况下,先执行AND,再执行OR,即
(表达式1 AND 表达式2) OR (表达式3)
4、 查询记录去重复
SELECT DISTINCT 属性名列表 FROM 表名;
5、 查询结果排序
SELECT * FROM 表名
ORDER BY 属性1 DESC, 属性2 ASC;
解释: 对属性名1按照降序排列,当属性名1相同时,对属性名2按照升序排列。
6、分组查询
GROUP BY 属性名 [HAVING 条件表达式] [WITH ROLLUP]
A)单独使用GROUP BY
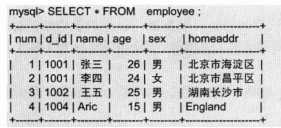

B)GROUP BY + GROUP_CONCAT()组合使用

C)[HAVING 条件表达式]组合使用

D)多字段分组
SELECT * FROM 表名 GROUP BY 字段A, 字段B;
多字段分组时:取去重字段A和去重字段B的 笛卡尔积
E)[WITH ROLLUP]组合使用

7、限制显示记录条数
LIMIT n
解释:查询仅显示前n条记录,LIMIT是MySQL特有的关键字。
8、函数的用法
SELECT sec, COUNT(sec) AS 别名 FROM 表名;
写在 与 属性相同的位置
9、COUNT()
用于统计记录的条数
10、 SUN()
用于求和整行记录
11、AVG()
整行记录求平均值
12、MAX()
整行记录求最大值
13、MIN()
整行记录求最小值
14、多表查询(连接查询)
A)内连接查询
SELECT 属性列表
FROM 表1, 表2
WHERE 表1.属性1 = 表2.属性2
要点:需要把表1中的一条属性和表2中的一条属性关联起来,使表1与表2形成关联关系。
思想:取两个表满足WHERE条件的交集。
B)外连接查询
SELECT 属性列表
FROM 表1 LIFT | RIGET 表2
WHERE 两个表的关联条件
分为左连接和右连接
左连接:(表1 ∩ 表2) ∪ 表1
右连接:(表1 ∩ 表2) ∪ 表2
15、 子查询
查询语句的嵌套使用,内层查询结果成为外层查询的条件。
A)带IN的子查询
SELECT * FROM 表
WHERE d_id IN
(SELECT d_id FROM 子表);
B)带比较运算符的子查询(=、 >、 <、 >=、 <=、 !=、 <>、 !<、 !>)
SELECT * FROM 表
WHERE d_id =
(SELECT d_id FROM 子表);
C)带EXISTS的子查询
EXISTS表示存在的意思,他只能判断真假,因此子SELECT语句应该返回真假。
SELECT * FROM 表
WHERE d_id EXISTS
(SELECT d_id FROM 子表 WHERE d_id = 1333);
解释:只有子表 d_id 为1333 的 记录存在时, 才会执行 查询语句
D)带 ANY 和 ALL 的子查询
SELECT * FROM 表
WHERE a >= <ANY | ALL>
(SELECT d_id FROM 子表)
解释:ANY表示a只要>=ANY()中的任何一个元素就为真
ALL表示a要>=ALL()中的所有元素才为真
16、合并查询结果
SELECT语句1
UNION | UNION ALL
SELECT语句2
UNION | UNION ALL
SELECT语句3
... ...
UNION:合并结果并去掉重复的记录
UNION ALL:合并结果不去掉重复记录
17、给表起别名
SELECT *
FORM 表名 表别名
WHERE 表别名.id = 1;
18、给字段起别名
属性名 [AS] 属性别名
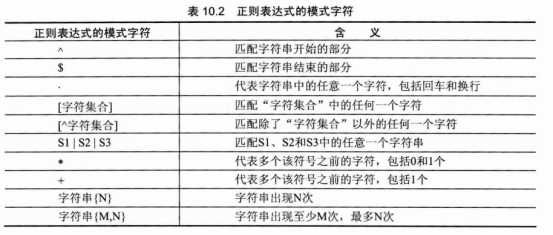
19、使用正则表达式查询
SELECT * FROM 表
WHERE name REGEXP ‘正则表达式’;
标签:优先 sts select min 资源 字符 匹配 字段 lib
原文地址:http://www.cnblogs.com/vrg0/p/6700258.html