这是学习网络编程后写的一个练手的小程序,可以帮助复习I/O模型,epoll使用,线程池,HTTP协议等内容。
程序代码是基于《Linux高性能服务器编程》一书编写的。
首先回顾程序中的核心内容和主要问题,最后给出相关代码。
0. 功能和I/O模型
实现简易的HTTP服务端,现仅支持GET方法,通过浏览器访问可以返回相应内容。
I/O模型采用Reactor(I/O复用 + 非阻塞I/O) + 线程池。 使用epoll事件循环用作事件通知,如果listenfd上可读,则调用accept,把新建的fd加入epoll中;
是已连接sockfd,将其加入到线程池中由工作线程竞争执行任务。
1. 线程池怎么实现?
程序采用c++编写,要自己封装一个简易的线程池类。大致思路是创建固定数目的线程(如跟核数相同),然后类内部维护一个生产者—消费者队列。
提供相应的添加任务(生产者)和执行任务接口(消费者)。按照操作系统书中典型的生产者—消费者模型维护增减队列任务(使用mutex和semaphore)。
mutex用于互斥,保证任意时刻只有一个线程读写队列,semaphore用于同步,保证执行顺序(队列为空时不要读,队列满了不要写)。
2. epoll用条件触发(LT)还是边缘触发(ET)?
考虑这样的情况,一个工作线程在读一个fd,但没有读完。如果采用LT,则下一次事件循环到来的时候,又会触发该fd可读,此时线程池很有可能将该fd分配给其他的线程处理数据。
这显然不是我们想要看到的,而ET则不会在下一次epoll_wait的时候返回,除非读完以后又有新数据才返回。所以这里应该使用ET。
当然ET用法在《Tinychatserver: 一个简易的命令行群聊程序》也有总结过。用法的模式是固定的,把fd设为nonblocking,如果返回某fd可读,循环read直到EAGAIN。
3. 继续上面的问题,如果某个线程在处理fd的同时,又有新的一批数据发来(不是老数据没读完,是来新数据了),即使使用了ET模式,因为新数据的到来,仍然会触发该fd可读,所以仍然存在将该fd分给其他线程处理的情况。
这里就用到了EPOLLONESHOT事件。对于注册了EPOLLONESHOT事件的文件描述符,操作系统最大触发其上注册的一个可读、可写或者异常事件,且只触发一次。
除非我们使用epoll_ctl函数重置该文件描述符上注册的EPOLLONESHOT事件。这样,当一个线程处理某个socket时,其他线程是不可能有机会操作该socket的,
即可解决该问题。但同时也要注意,如果注册了EPOLLONESHOT的socket一旦被某个线程处理完毕,则应该立即重置这个socket上的EPOLLONESHOT事件,
以确保下一次可读时,其EPOLLIN事件能够触发。
4. HTTP协议解析怎么做?数据读到一半怎么办?
首先理解这个问题。HTTP协议并未提供头部字段的长度,判断头部结束依据是遇到一个空行,该空行只包含一对回车换行符(<CR><LF>)。同时,如果一次读操作没有读入整个HTTP请求
的头部,我们必须等待用户继续写数据再次读入(比如读到 GET /index.html HTT就结束了,必须维护这个状态,下一次必须继续读‘P’)。
即我们需要判定当前解析的这一行是什么(请求行?请求头?消息体?),还需要判断解析一行是否结束?
解决上述问题,可以采取有限状态机。
参考【1】中设计方式,设计主从两个状态机(主状态机解决前半部分问题,从状态机解决后半部分问题)。
先分析从状态机,从状态机用于处理一行信息(即parse_line函数)。其中包括三个状态:LINE_OPEN, LINE_OK,LINE_BAD,转移过程如下所示:
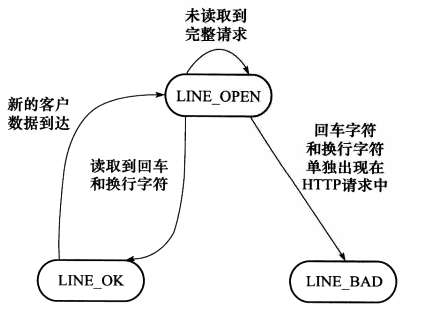
当从状态机parse_line读到完整的一行,就可以将改行内容递交给process_read函数中的主状态机处理。
主状态机也有三种状态表示正在分析请求行(CHECK_STATE_REQUESTINE),正在分析头部字段(CHECK_STATE_HEADER),和正在分析内容(CHECK_CONTENT)。
主状态机使用checkstate变量来记录当前的状态。
如果当前的状态是CHECK_STATE_REQUESTLINE,则表示parse_line函数解析出的行是请求行,于是主状态机调用parse_requestline来分析请求行;
如果当前的状态是CHECK_STATE_HEADER,则表示parse_line函数解析出来的是头部字段,于是主状态机调用parse_header来分析头部字段。
如果当前状态是CHECK_CONTENT,则表示parse_line函数解析出来的是消息体,我们调用parse_content来分析消息体(实际上实现时候并没有分析,只是判断是否完整读入)
checkstate变量的初始值是CHECK_STATE_REQUESTLINE,调用相应的函数(parse_requestline,parse_header)后更新checkstate实现状态转移。
与主状态机有关的核心函数如下:
http_conn::HTTP_CODE http_conn::process_read()//完整的HTTP解析{
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST; char* text = 0; while ( ( ( m_check_state == CHECK_STATE_CONTENT ) && ( line_status == LINE_OK ) ) || ( ( line_status = parse_line() ) == LINE_OK ) ){//满足条件:正在进行HTTP解析、读取一个完整行
text = get_line();//从读缓冲区(HTTP请求数据)获取一行数据
m_start_line = m_checked_idx;//行的起始位置等于正在每行解析的第一个字节
printf( "got 1 http line: %s", text );
switch ( m_check_state )//HTTP解析状态跳转 { case CHECK_STATE_REQUESTLINE://正在分析请求行 {
ret = parse_request_line( text );//分析请求行
if ( ret == BAD_REQUEST )
{ return BAD_REQUEST;
} break;
} case CHECK_STATE_HEADER://正在分析请求头部 {
ret = parse_headers( text );//分析头部
if ( ret == BAD_REQUEST )
{ return BAD_REQUEST;
} else if ( ret == GET_REQUEST )
{ return do_request();//当获得一个完整的连接请求则调用do_request分析处理资源页文件 } break;
} case CHECK_STATE_CONTENT:// 解析消息体 {
ret = parse_content( text ); if ( ret == GET_REQUEST )
{ return do_request();
}
line_status = LINE_OPEN; break;
} default:
{ return INTERNAL_ERROR;//内部错误 }
}
} return NO_REQUEST;
}
5. HTTP响应怎么做?怎么发送效率高一些?
首先介绍readv和writev函数。其功能可以简单概括为对数据进行整合传输及发送,即所谓分散读,集中写。
也就是说,writev函数可以把分散保存在多个缓冲中的数据一并发送,通过readv函数可以由多个缓冲分别接收。因此适当采用这两个函数可以减少I/O次数。
例如这里要做的HTTP响应。其包含一个状态行,多个头部字段,一个空行和文档的内容。前三者可能被web服务器放置在一块内存中,
而文档的内容则通常被读入到另外一块单独的内存中(通过read函数或mmap函数)。这里可以采用writev函数将他们一并发出。
相关接口如下:
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
其中第二个参数为如下结构体的数组struct iovec { void *iov_base; /* Starting address */
size_t iov_len; /* Number of bytes to transfer */};
第三个参数为第二个参数的传递的数组的长度。这里还可以再学习一下mmap与munmap函数。但是这里关于mmap与read效率的比较,应该没有那么简单的答案。mmap可以减少系统调用和内存拷贝,但是其引发的pagefault也是开销。效率的比较取决于不同系统对于这两个效率实现的不同,所以这里就简单谈一谈用法。
#include <sys/mman.h>/**addr参数允许用户使用某个特定的地址作为这段内存的起始地址,设置为NULL则自动分配地址。 *length参数指定内存段的长度. *prot参数用来设置内*存段的访问权限,比如PROT_READ可读, PROT_WRITE可写。 *flags控制内存段内容被修改后程序的行为。如MAP_PRIVATE指内存段为调用进程所私有,对该内存段的修改不会反映到被映射的文件中。*/void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);int munmap(void *addr, size_t length);
所以根据不同情况(200,404)填充HTTP的程序如下:
 填充HTTP应答
填充HTTP应答
将应答发送给客户端
6.忽略SIGPIPE
这是一个看似很小,但是如果不注意会直接引发bug的地方。如果往一个读端关闭的管道或者socket中写数据,会引发SIGPIPE,程序收到SIGPIPE信号后默认的操作时终止进程。
这也就是说,如果客户端意外关闭,那么服务器可能也就跟着直接挂了,这显然不是我们想要的。所以网络程序中服务端一般会忽略SIGPIPE信号。
7. 程序代码
程序中有比较详细的注释,虽然主干在上面问题中分析过了,但是诸如如何解析一行数据之类的操作,还是很烦的...可以直接参考代码
threadpool.h
http_conn.h
http_conn.cpp
locker.h
main.cpp
原文地址:http://kiujyhgt.blog.51cto.com/12806908/1915884