标签:ons web created cond logs 计时 使用 函数 阅读
在移动环境或者离线环境中,WebDataBase 虽然能够存储并有效地管理和维护客户端的数据集合,但是仍不能满足对包含大段数据文件的存储和多种不同格式文件的保存,于是我们就需要离线的文件管理系统来维护我们工作了,基于HTML5的FileSystem API 就充当这这个角色。
通过这个FileSystem API,我们的Web应用程序可以阅读,浏览,编辑和操纵本地文件系统。
FileSystem API的主要功能有:
|
Reading and manipulating files: File/Blob, FileList, FileReader |
|
Creating and writing: BlobBuilder, FileWriter |
|
Directories and filesystem access:DirectoryReader,FileEntry/DirectoryEntry,LocalFileSystem |
支持情况和存储空间的限制:
目前主流浏览器中,chrome应该是支持文件操作系统最好的浏览器,只要你配置好相关的操作数据,浏览器允许你创建没有限制的存储空间。
现在我们来封装和提取基于FileSystem API的公用方法。
首先,我们需要拿到FileSystem API的可操作的数据上下文:
FileSystem API通过调用 window.requestFileSystem() 来请求文件系统进行操作,
 View Code
View Code
然后编写一个DSDataFactory的函数(这个函数旨在对文件夹的操作),
在这个函数中内置相应的属性和方法,包含了文件请求系统的大小,默认为1兆,文件类型,默认为临时空间;内置的错误信息,这个错误信息可以自定义,在后面会讲到。
View Code这个DSDataFacory函数里面,还包含着另外两个函数,一个函数用于创建文件,一个函数用于移除文件夹(同时移除该文件夹内的所有文件)。
创建一个文件夹(包含两个参数,一个是文件夹名称 directoryName,一个是回调函数callback):
View Code这样就在浏览器缓存中创建了一个文件夹,并返回文件夹的名称。
移除文件夹以及文件夹下面的所有文件(递归移除),这边有两个参数:一个是direcotoryName,指的是待文件夹的名称,这个其实应该指的是该文件夹的路径,一个是回调函数,返回移除的文件夹的名称,下面的dirEntry.removeRecursively指的是递归删除:
View Code
第三步骤我们编写一个FSDataFactory的函数(这个函数旨在对文件的操作),这边我们把对文件夹的操作和对文件的操作分离成两个不同的类是为了更加清晰的操作,同样的,我们通过访问FileSystem API来请求文件系统作为入口操作:
View Code在这个FSDataFactory函数内我们包含了一些我们最经常用的,对文件系统的CURD的操作,下面我们会一个一个讲到。
逐级创建文件和文件夹(包含了两个参数fileName(你要创建的文件名称,更确切的说应该是文件路径)和callback回调函数):
View Code这里面其实是递归调用了createDir函数,来逐级地创建文件夹,检查到最后一级的时候,检查是文件还是文件夹,如果包含 . 则认定为文件,否则为文件夹。
如fileName=”/BenFirst/BenSecond/BenThird/”,则会按顺序相继地创建这三个文件夹,
如果fileName=” /BenFirst/BenSecond/BenThird/Ben.txt”,则会相继创建文件夹,并在BenThird文件夹下面创建Ben.txt文件
逐级创建文件和文件夹并写入内容(包含了三个参数fileName(你要创建的文件名称,更确切的说应该是文件路径)、content(你要写入的内容)和callback回调函数):
View Code做法与上面的一样,就是多了一个参数content,传入你需要写入的文字,他会在系统中创建一个Blob并写入文件中,该方法适用于创建.txt类型的文件。
根据文件名(其实是根据文件路径)来读取文件,包含两个参数,一个文件名称fileName和一个回调函数callback:
View Code根据文件路径来读取文件并输出文件内容,这边还自定义了错误输出:如果出现错误,则调用了回调函数,输出字符串“0”。所以当这边出现NOT_FOUND_ERR
错误的时候不会输出系统定义的错误信息二回输出我们定义的错误信息。这样有利用我们将信息反馈给用户。
根据文件名称(也就是完整的文件路径)删除文件:通过查找到该文件,并执行删除,包含两个参数,一个文件名称fileName和一个回调函数callback:
View Code删除完成之后通过回调函数返回被删除的文件的名称
根据文件名称来对文件的内容进行追加(先读取文件,然后将传入的内容添加到文件中):
View Code
逐级创建文件和文件夹并写入内容(包含了三个参数fileName(你要创建的文件名称,更确切的说应该是文件路径)、content(你要写入的内容)和callback回调函数):
View Code这个调用了之前的writeNewFile函数,唯一的区别就是他在调用writeNewFile之前还调用了fileEntry.Remove函数,就是先对文件进行删除,然后再创建文件。
至此,在 HTML5 下的文件的处理方法我们基本有了,我们可以灵活地对文件进行操作。如果有不够的地方,我们可以继续修改完善。
在代码的结尾我们进行了实例化,
View Code我们把这些代码独立地存放到FileSystem.js文件里面,这样可以在继承这个脚本文件的页面里直接调用这个脚本库的方法。
我们源码中的public.js脚本中有GetRequest()函数,用于解析地址参数的:
我们的log.js脚本页面里面,包含了对console.debug(msg),控制台信息输出的二次封装,所以下面会经常看到里面的一个方法:log.debug(msg),用于调试时输出我们需要的的信息。
我们的 FormSerialy.js里面的序列化函数,在下面序列化表单的时候也有用到。
这些脚本文件都在我们的源码里面,有兴趣可以系统地看一看
离线工作系统在用户工作日志保存那一块就是将填写的数据保存在离线的文件系统中,通过txt文件来保存的。
现在来看这个应用的实际操作:
在DraftBox.htm 这个页面,我们存放我们在网络离线情况下写好的工作日志,并且把它保存在客户端的WebDataBase和FileSystem里面。所以我们可以在这个页面看到我们离线时的数据日志列表。
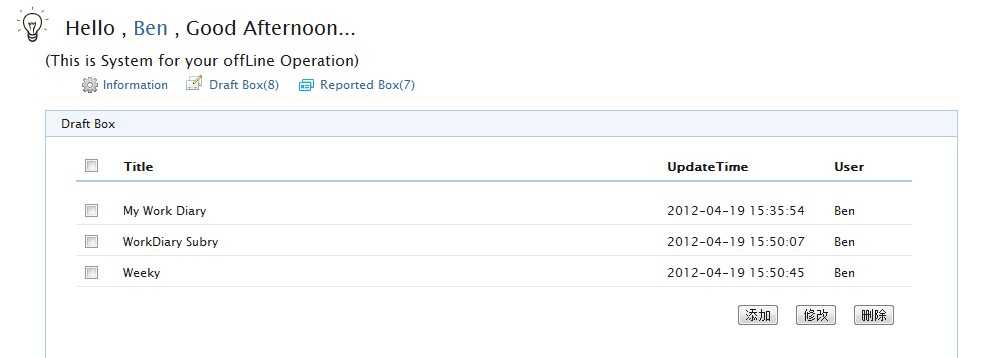
相关的业务代码如下:
View Code
而WorkDiary.htm 这个页面,是我们设计好的工作日志的填写表单:包含了标题,工作时间,工作计时,工作内容等字段。
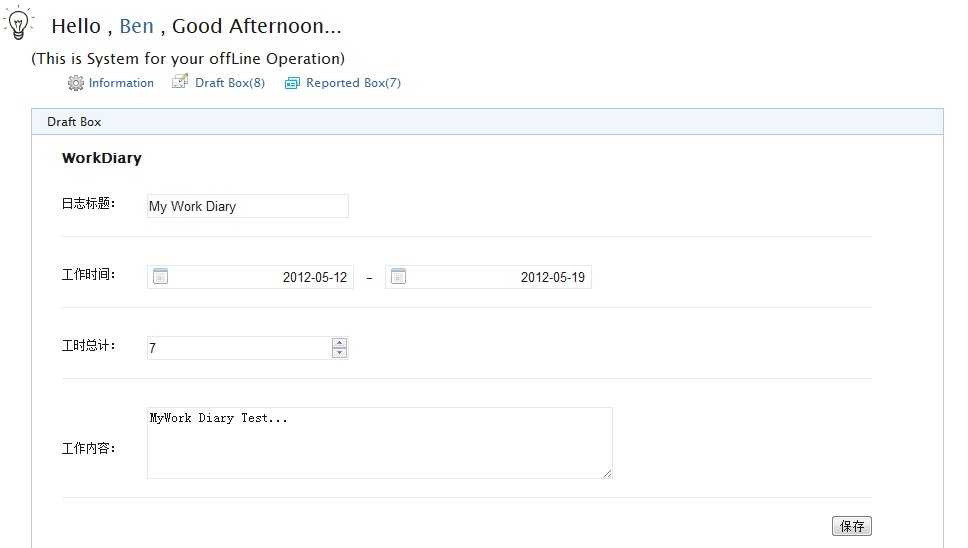
下面是WorkDiary.htm页面的相关业务代码:
View Code
保存到数据库的结果如图:

保存到离线文件中的结果如图:

这样子,我们不但将数据保存到离线数据库中,也将表单的数据序列化之后以JSON格式存入txt中。
优点在于:
1、可以在这个txt里面放大量数据,譬如这个WorkDiary_Content这个字段,是填写工作日志的,可能大数据量,存在文件里面比较适合。
2、可以在某种程度上提高了重要数据的安全性,一般用户如果没有操作toURL函数,是不能直接获取到该txt文件的路径进而看到内容的,不像WebDataBase,用户可以直接在浏览器开发者工具的Resources面板中直接看到。
3、文件格式的多样性,除了保存txt文件之外,还可以保存多媒体文件如mp3,图片文件如png。
HTML5项目笔记6:使用HTML5 FileSystem API设计离线文件存储
标签:ons web created cond logs 计时 使用 函数 阅读
原文地址:http://www.cnblogs.com/chenshizhutou/p/6710908.html