标签:关键字 效率 转换 空间 表数据 stat rar ++ 最好
C++中,用以支持泛型应用的是标准模板类库STL(Standard Template Library),作为C++标准库的一个重要组成部分,它为用户提供了C++泛型设计常用的类模板和函数模板,并用它们支持C++的泛型设计。可以说,支持C++泛型的核心技术就是模板。
template < typename T, typename R, typename S>
T maxt( R x, S y)
{
return ( x > y ) ? x : y;
}
以maxt模板及其函数实例为例,其调用格式为:
int x; double y , z; ... maxt< int, double, double> (x, y, z);
编译器会根据实际调用由模板生成实体函数。
template <typename T>
class Circle
{
private:
T Radius;
public:
Circle (T r);
T Area();
};
类模板外实现类成员函数:
template<typename T>
Circle<T>::Circle(T r)
{
Radius = r;
}
template<typename T>
T Circle<T>::Area()
{
return PI * Radius * Radius;
}
其调用格式:
Circle< int >circle_1( 10 ); cout<<circle_1.Area()<<endl; Circle< double >circle_2( 12.786 ); cout<<circle_2.Area()<<endl;
STL的模板编程对面向对象技术并不感兴趣,它认为类对数据的过度封装影响了程序的执行效率,之所以STL的模板编程中还大量的使用类模板,是因为类这种形式可以对程序代码进行形式上的分割,从而使代码更便于阅读和管理,所以STL中大量使用的是没有访问权限的struct制作的类模板。
template<typename T>
struct Circle
{
T Radius;
Ciecle(T r;)
T Area();
};
auto关键字是自动推导数据类型所设的,它能在定义一个变量时根据这个变量的初始化数据自动推导出变量或对象的数据类型。
template <typename T,typename U>
void Multiply(T t, U u)
{
auto v = t * u;
cout<<"v = "<<v<<endl;
}
变量类型难以确定的问题主要体现在函数的返回值上,因此在函数的返回值类型的位置上常常会出现auto关键字。
新标准允许程序员设计者对函数返回值的类型进行推导工作进行指导,具体的做法就是使用decltype表达式。
template <typename T, typename U>
auto Multiply(T t, U u) -> decltype( t * u)
{
return t * u;
}
使用关键字typename声明的参数都属于类型参数。
template <typename T, int b>
第二个参数b就是非类型参数,因为其实参只能是整型变量或整型数,不可能是一个数据类型。
需要注意的是:由于模板参数是在预编译期间进行传递并被编译的,故这种非类型参数在模板代码内是常量,不能修改;对于这种参数,目前C++标准仅支持整型int、枚举、指针和引用类型。
以一个例子说明:
//定义一个单参数的类模板
template <typename T> struct S_tmp { T a; void ply(); };
//定义一个双参数的类模板 template <typename T, typename R> struct D_tmp { void ply(); };
//定义一个以单参数类模板定义为参数的类模板 template <template<typename S>class T> struct Mytest { T <int> test; void ply() { test.ply(); } }; //主函数 int main() { //用单参数类模板S_tmp做参数实例化模板Mytest Mytest < S_tmp > tt1; tt1.ply(); //用双参数类模板D_tmp做参数实例化模板Mytest Mytest < D_tmp > tt2; //因为模板参数个数不匹配,编译器报错 tt2.ply(); return 0; }
template <yupename T>
T add( T x, T y)
{
return x +y;
}
正常的调用格式为:
add < int >( 45, 66);
隐式格式为:
add ( 45, 66 );
如果编译器无法准确的推断出返回类型,就用到前面提到过的关键字auto和decltype。
template <typename T1, typename T2>
T2 add( T1 a, T2 b)
{
return b;
}
int main()
{
int a = 4;
double b = 6.7;
int * pa = & a;
double * pb = & b;
cout<< * add( pa, pb)<<endl;
return 0;
}
template <typename T1, typename T2>
const T2& add( const T1& a, const T2& b)
{
return b;
}
int main()
{
int a = 4;
double b = 6.7;
int * pa = & a;
double * pb = & b;
cout<< add( pa, pb)<<endl;
return 0;
}
template <typename T>
T mymax( T t1, T t2)
{
return t1 > t2 ? t1 : t2;
}
上述模板显然对字符串(char *)类型不适用,因为字符串的比较不能使用符号>,只能使用字符串的比较函数strcmp(t1,t2)。
如果这个字符串比较函数的函数名与上述的mymax模板重名,最好把这个函数纳入mymax模板体系,具体做法就是在函数前面使用关键字template将其声明为模板。
template <>
char * mymax( char * t1, char * t2)
{
return ( strcmp(t1,t2) < 0) ? t2 : t1;
}
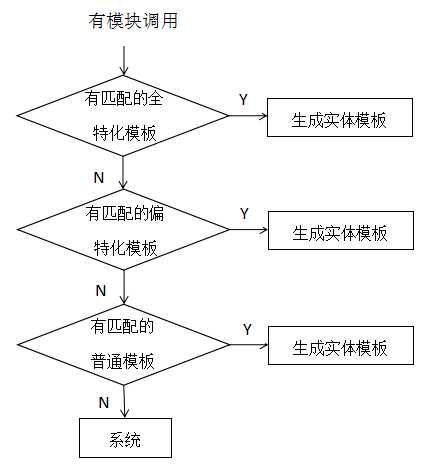
//普通模板
template <typename T1, typename T2>
struct Test
{
void disp() { cout<<"这是一个普通类模板"}<<endl;
};
//偏特化模板
template <typename T2>
struct Test < int, T2>
{
void disp() { cout<<"这是一个偏特化类模板"<<endl;}
};
//全特化模板
template <>
struct Test < int, float>
{
void disp() { cout<<"这是一个全特化类模板"<<endl;}
};
//测试主函数
int main()
{
Test<float,char> tt1; //定义一个普通模板对象
tt1.disp();
Test<int,double> tt2; //定义一个偏特化模板对象
tt2.disp();
Test<int,flost> tt3; //定义一个全特化模板对象
tt3.disp();
return 0;
}
左值之所以可以出现在赋值运算符左边,就是因为这种表达式代表一块存储空间,可以接收并保存数据。从形式上看,它一定有一个代表这块存储空间及其数据的变量名,程序可以通过其变量名获取地址,并用这个地址访问数据。当然,使用变量名或地址,也能代表数据,因此左值也可以出现在赋值运算符右边。
右值仅能代表数据。右值表达式要么是数据本身,要么是一个能得出结果的运算表达式,尽管它也占据一定存储空间,但因它没有名字,也不能从其表达式中提取这个空间的地址,因此这种表达式只能出现在赋值运算符右边,而且仅能代表生命期与其所在语句相同的临时对象,程序语句一结束,临时对象也就立即销毁,不复存在。
总之,左值是一种有名字,有固定地址的表达式;而右值则是匿名,无固定地址的对象。
int a = 10; int & b = a; //为左值a命名别名b const int & c = a; //为左值a命名常量别名c const int & d = 100; //为右值100命名常量别名d int x = 150, y = 250; const int & i = x + y; //为右值x+y命名常量别名i i += 10; //非法 int & f =10; //非法,右值只能常引用
从上面的例子可以看出左值可以定义两种引用:
T & 别名=lvalue;
const T & 别名=lvalue;
而右值仅有一种常引用:
const T & 别名=rvalue;
为能充分利用临时对象,C++标准推出了一种新的数据类型---右值的非常引用,简称右值引用,格式如下:
T && 别名=rvalue;
右值引用是一种新的数据类型,这就意味着可以利用函数重载技术使某种函数多实现一种功能。所以,右值引用的第一个应用就是类的拷贝构造函数和赋值运算符重载。因为使用右值引用为类重载的这种函数具有资源控制权转移功能,因此称这种函数具有转移语义。
【深拷贝和浅拷贝】
深拷贝和浅拷贝的问题与类对象掌控的资源有关。由new分配的内存空间叫做对象掌控的资源。因为这种空间具有稀疏性,使用后对象应该释放它以为其他程序实体所使用,故称为资源。为完成任务,程序经常需要对上述对象资源进行调配,因此凡是含有资源的类都会定义相应的拷贝构造函数和析构函数。
class Foo
{
public:
Foo( int x) //构造函数
{
p = new int (x); //p指向堆中分配的一空间
}
Foo ( const Foo& r) //深拷贝构造函数
{
p = new int; //为新对象资源申请空间
* p = * (r.p); //将指针指向的数据复制到新对象指针指向空间
}
~ Foo()
{
if ( p != NULL)
{
delete p; //释放指针指向的空间
}
}
void show()
{
cout<<p<<" "<<*p<<endl;
}
private:
int * p; //用以存放资源空间地址的指针
};
int main()
{
Foo foo1(50);
Foo foo2(foo1);
foo1.show();
foo2.show();
return 0;
}
上面给出的是深拷贝构造函数的例子,下面给出浅拷贝构造函数的例子。
Foo (const Foo & r) //浅拷贝构造函数
{
p = r.p; //简单的拷贝使得p和r.p指向了同一空间
}
可以看出,浅拷贝既不需要在目标对象中为资源分配空间,也不用在两个对象的空间之间赋值庞大的资源数据,所以它既快又节省内存。如果有办法将源对象指针置为空,那么结果就是源对象把资源的控制权交给了目标对象,用C++11的说法就是实现了资源控制权的“转移”。显然,这种做法特别适合源对象为临时对象(右值)的场合。
因函数以传值方式处理返回值的过程中要创建临时对象,因此为类设计这种具有“转移语义”的拷贝构造函数就成了必需的。
具有转移语义的拷贝构造函数如下:(转移语义拷贝构造函数其实就是右值引用拷贝构造函数)
Foo (Foo && r)
{
p = r.p; //简单的拷贝使得p和r.p指向了同一空间
r.p = null; //将r.p设置为空指针,源对象放弃资源控制权
}
鉴于右值引用带来的好处,包含具有转移语义的赋值运算符也就成了类设计工作中的应有之义。下面给出两个赋值运算符重载代码:
Foo 7 operator = (const Foo & r) //深拷贝赋值运算符重载
{
delete p; //释放原有的资源
p = new int; //指针指向新为资源申请的内存空间
* p = * (r.p); //源向目标赋值资源数据
return * this; //返回目标对象
}
Foo & oprator = (Foo && r) //转移语义赋值运算符重载
{
delete p; //释放原有资源
p = r.p; //源与目标对象共享资源
r.p = null; //源对象放弃资源控制权
return * this; //返回目标对象
}
看到了右值引用的好处,左值也想利益共沾,因此C++11推出了move()函数,其原型如下:
T && move(T & val); //它接受一个参数val,然后返回这个参数的右值引用
foo2 = move( foo1); //对象foo1就会调用类中的转移语义运算符重载来实现赋值运算。
如果move()函数使用得当,其效果巨大,STL库中的数据交换函数std::swap()便用到这个函数,其示意性代码如下:
void swap( T & a, T & b)
{
T tmp = move( a );
a = move ( b );
b = move( tmp );
}
如果T是一个类类型,里面包含了大量资源,那么不用转移语义技术进行这种交换得耗费多少资源呀,而这里只交换了3次指针便完成了任务,效率极高。
在C++11之前,模板的参数完美转发问题一直没有得到很好的解决,主要是因为右值参数经模板转发后变成左值,从而在模板内不能调用那些可以使用右值参数的函数。
void Func( int v)
{
cout<<"调用成功"<<endl;
}
//转发模板
template <typename T>
void Tmp( T a)
{
Func( a );
}
//测试程序
int main()
{
int x = 1;
Tmp( 10 ); //右值参数
Tmp( x ); //左值传递
return 0;
}
从测试结果可以看出,模板既可以实现右值参数转发,也可以实现左值参数转发,但按照全述的要求并不完美,因为是值传递,它在转发过程中需要创建临时对象并对数据进行拷贝,产生额外的消耗。
为了转发过程中不使用有消耗的临时对象,那就意味着转发模板的参数必须是引用类型。
void Tmp( T & a)
{
Func( a );
}
Tmp(x);此时就是左值的值传递
但还不是完美转发,因为它不能进行右值参数转发。能够实现完美转发的模板参数类型必须是右值引用。
void Func( int & v)
{
cout<<"调用成功"<<endl;
}
//转发模板
template <typename T>
void Tmp( T && a)
{
Func( a );
}
//测试程序
int main()
{
int x = 1;
Tmp( 10 ); //右值参数
Tmp( x ); //左值引用传递
return 0;
}
C++11开发forward()函数,以将被模板变换成左值的右值参数再转换回来。
下表为:引用符的折叠规则(reference collapsing rule)
|
序号 |
实参类型(以int为例) |
模板形参类型 |
形实结合时的类型推导结果 |
|
1 |
int & |
T & |
int & |
|
2 |
int && |
T & |
int & |
|
3 |
int & |
T && |
int & |
|
4 |
int && |
T && |
int && |
下表为:模板(T && 类型)参数推导的两条特殊规则
|
序号 |
实参类型 |
类型推导结果 |
|
1 |
左值(lvalue) |
T & |
|
2 |
右值(rvalue) |
T |
写一个测试代码:
//左值引用类型形参目标函数
void Func( int & v)
{
cout<<"&调用成功"<<endl;
}
//右值引用类型形参目标函数
void Func( int && v)
{
cout<<"&&调用成功"<<endl;
}
//转发模板
template <typename T>
void Tmp( T && a)
{
Func( a );
}
//测试程序
int main()
{
int x = 1;
int & y = x;
Tmp( x ); //实参为左值
Tmp( y ); //实参为左值引用
Tmp( 100 ); //实参为右值
return 0;
}
测试结果如下:
& 调用成功 & 调用成功 & 调用成功
从结果可以看到,当模板发现参数x是int的一个左值引用时,模板参数T就被推导为int&类型,接下来与模板参数定义T后面的两个引用符&连接后,类型为int&&&,最后编译器依据折叠规则将参数类型简化为int&类型,而这正是目标函数的期望类型。
当使用右值(100)为实参时没能正确调用预期函数,就是因为模板将右值转换成左值。正确的做法应该如下:
if( 参数为右值)
Func( move( a ) );
else
Func( a );
move()函数的功能,只能将T&类型转换成T&&类型,所以为了避免使用if-else结构,C++11采用了原来就有的数据类型强制转换函数模板static_cast,于是,调用目标函数的代码如下:
template <typename T>
void Tmp( T && a)
{
Func( static_cast< T &&> ( a ));
}
由于static_cast的模板参数与Tmp模板参数类型完全相同,都为T&&,故保证了参数的输入类型与函数的实收参数类型完全一致。进来的是右值,发到函数的一定也是右值(这是static_cast转换的结果);进来的是左值,发到函数的也一定是左值。
其实static_cast只对参数为右值时有用。为了区别move()和static_cast,并使之更具语义性,C++11将static_cast封装成函数模板std::forward。正确的代码如下:
template <typename T>
void Tmp( T && a)
{
Func( forward< T > ( a ) );
}
标签:关键字 效率 转换 空间 表数据 stat rar ++ 最好
原文地址:http://www.cnblogs.com/33goodness/p/6703183.html