标签:disk uid remote ror compute 查询条件 安全 多表连接 ict
1 数据库命名约定
1.1 规则
(1) 命名富有意义英文词汇,多个单词组成的,中间以下划线分割。
(2) 除数据库名称长度为1-8个字符,其余为1-30个字符,dblink名称也不要超过30个字符。
(3)命名只能使用英文字母,数字和下划线,字母全部小写
(4)避免使用Oracle的保留字如level、关键字如type。
|
编号 |
名称 |
英文 |
缩写 |
|
1 |
系统管理 |
system |
sys |
|
2 |
配置管理 |
dictionary |
dic |
|
3 |
设备系统 |
equipment |
equ |
|
4 |
通讯系统 |
BaiZE |
bai |
|
5 |
能耗系统 |
energy consumption |
egy |
|
6 |
调度系统 |
dispatch |
dph |
|
7 |
数据分析系统 |
Auto Data Make Data |
amk |
|
8 |
Data to UI |
dui |
|
|
9 |
stmart |
smt |
|
|
10 |
营收系统 |
revenue |
rev |
|
11 |
客服系统 |
custom service |
cus |
|
12 |
远程抄表系统 |
remote reading |
rea |
|
13 |
报装系统 |
Expanding |
exp |
|
14 |
移动互联系统 |
mobile |
mob |
|
15 |
管网监测系统 |
Pipe Supervision |
pip |
|
16 |
自备井监测 |
Self-supply wells |
ssw |
|
17 |
协同办公 |
cooperative OA |
coa |
|
18 |
水厂监测 |
Water Factory Monitoring |
wfm |
|
19 |
二次供水系统 |
secondary water-supply |
sws |
|
20 |
GIS系统 |
gis |
gis |
|
21 |
水力模型系统 |
Water Model system |
mod |
|
22 |
管理系统 |
Manage system |
man |
|
23 |
仿真决策分析系统 |
decision-making system |
dms |
|
24 |
BIM系统 |
Building Information Modeling |
bim |
1. 3业务功能
|
编号 |
名称 |
英文 |
缩写 |
|
1 |
小区 |
area |
area |
|
2 |
压力 |
pressure |
pressure |
|
3 |
流量 |
flow |
flow |
|
4 |
客服 |
custom service |
service |
|
5 |
移动应用 |
mobile apps |
app |
|
6 |
水厂 |
water works |
water |
|
7 |
客户 |
customer |
customer |
|
8 |
大客户 |
big customer |
bcustomer |
|
9 |
二次供水 |
secondary water supply |
second |
|
10 |
饮水机 |
water fountain |
fountain |
|
11 |
自备井 |
Self-supply wells |
wells |
|
12 |
水质 |
water quality |
quality |
|
13 |
诊断 |
diagnoses |
diagnoses |
|
14 |
水源 |
waterhead |
waterhead |
|
15 |
收费 |
charge |
charge |
|
16 |
档案 |
file |
file |
|
17 |
抄表 |
reading |
reading |
|
18 |
发票 |
invoice |
invoice |
|
19 |
报表 |
report |
report |
|
20 |
工单 |
job |
job |
|
21 |
流程 |
process |
processs |
1. 4数据库对象
|
编号 |
名称 |
缩写 |
其它 |
|
1 |
表空间 |
tbs |
|
|
2 |
表 |
tb |
|
|
3 |
视图 |
vw |
|
|
4 |
过程 |
sp |
|
|
5 |
函数 |
fn |
|
|
6 |
序列 |
seq |
seq_表名 |
|
7 |
触发器 |
tr |
tr_表名 |
|
8 |
包 |
pk |
|
|
9 |
索引 |
idx |
seq_表名 |
|
10 |
约束 |
ck |
ck_表名_字段名 |
|
11 |
主键 |
pk |
pk_表名_字段名 |
|
12 |
外键 |
fk |
fk_主表名_从表名 |
|
13 |
用户自定义类型 |
udt |
|
2 SQL书写方式
2.1 注释
(1)注释以中文为主。
(2)注释尽可能详细、全面,并且将注释放在实现代码的前面,不要集中放在对象的开始。
(3)每一数据对象的前面,应具体描述该对象的功能和用途。传入参数的含义应该有所说明。如果取值范 围确定,也应该一并说明。取值有特定含义的变量(如boolean类型变量和枚举型变量),应给出每个值的含义。
(4)注释语法包含两种情况:单行注释、多行注释
(5)注释简洁,同时应描述清晰。
注释举例:编写函数、触发器、存储过程以及其他数据对象时,必须为每个对象增加适当注释。该注释以多行注释为主,主要结构如下(作者可以适当增减):
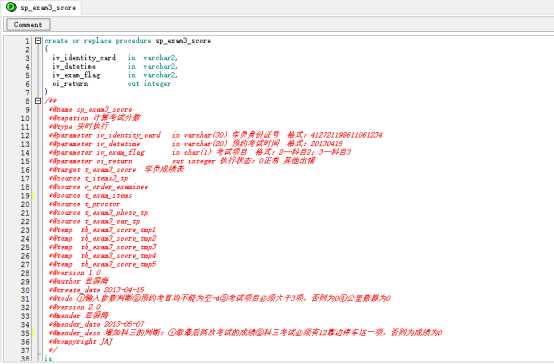
(1) 程序块要采用缩进风格编写,缩进的空格可根据实际情况进行调整,总的原则是使代码清晰可读。 示例:
(2)相对独立的程序块之间、变量说明之后必须加空行。
(3)较长的语句(>80字符)要分成多行书写,长表达式要在低优先级操作符处划分新行,操作符或关键字放在新行之首,划分出的新行要进行适当的缩进,使排版整齐,语句可读。 示例:
(4) 循环、判断等语句中若有较长的表达式或语句,则要进行适应的划分,长表达式要在低优先级操作符处划分新行,操作符或关键字放在新行之首。 示例:
(5)若函数或过程中的参数较长,则要进行适当的划分。 示例:
(6)只使用空格键,不要使用TAB键。
说明:以免用不同的编辑器阅读程序时,因TAB键所设置的空格数目不同而造成程序布局不整齐。例如:
(1)事务是SQL语句的一个序列,对事务的改变通过COMMIT语句成为永久的变化,部分或全部事务可以由ROLLBACK语句撤消。任何一个事务在运行过程中都要消耗一定的系统资源,如内存、回滚空间、磁盘空间等。在开发数据库应用软件的过程中,要注意正确估算相关事务的大小,对过大的事务操作采取必要的措施。
(2)明确事务的时间长短,要求事务在该时间内完成。
(3) 明确对事务的要求高低:如果对事务要求较高,对commit语句要判断执行是否正确,发现commit语句执行不正确,进行提示或记录。如果对事务要求较底,对commit语句不要判断执行是否正确,因为执行不正确也没有解决方法。对roolback都不用判断。
(4) 明确事务书写的规则:事务和存储过程的关系:存储过程中包含事务,还是事务中包含存储过程。同样要明确:事务和中间件的关系、事务和函数的关系。
(5)明确是否使用事务嵌套:有的数据库支持事务嵌套,有的数据库不支持事务嵌套。在设计是要明确整个系统是否使用事务嵌套。
(6)某些复杂的事务提交需要同涉及文件系统的某过程同时提交,此时,需要分析事务与过程的关系,决定提交的次序和错误恢复的策略。
(1) 数据库用户一定要通过操作系统,网络服务,或数据库进行身份确认。
(2)如果用户是通过数据库进行用户身份的确认,那么建议使用密码加密的方式与数据库进行连接。
(3)数据库开发者不能将数据库登陆密码直接写在其开发源代码中。
下面的情况针对的是大数据量的情况下。在数据量小的时候,下面的约定没有必要,例如,小表扫描比使用索引消耗的资源还小些。 为了SQL语句执行的速度,减少阻塞和死锁,提高请求的响应时间,请遵照如下约定:
在SQL的写法中,所有在大范围数据里搜索记录,必须有合适的索引来配匹,否则引起长时间的表扫描锁定。这是所有系统性能低下的最基本的根源。请为每一个SQL语句设计合适的索引,当系统开始设计时没有索引时请向项目经理申请增加。
(1)对于取值不能重复的、经常作为查询条件的字段,应该建立唯一索引:unique index
示例: create unique index my_unique_idx on myTable (id);
(2)对于经常作为查询条件的字段,其值可以不是唯一,则应该建立可重复索引:
index 示例: create index my_dup_idx on myTable(name);
(3)尽量避免以索引的一部分作为查询的条件:
示例:某表的建立SQL为: create table myTable(id int,name char(8),age int, primary key(id, name)) 即表myExample是以 id 和 name 共同组成 Primary Key。
则下面方式的查询语句效率很好: select ... from myTable where id= .... and name =....
而如果仅仅以 primary key 的一部分作为条件,则没有起到key 的作用。
如下面两条SQL查询效率很低: select ... from myTable where id=.... select ... from myTable where name=...
以上两条SQL,数据库系统将会使用顺序扫描,从而导致效率低下。
(4)组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。
(5)经常同时存取多列,且每列都含有重复值可考虑建立组合索引;
(6)有大量重复值、且经常有范围查询 (between, >,< ,>=,< =)和order by 、group by发生的列,可考虑建立群集索引;
在大范围的数据情况下,下面的用法,坚决杜绝使用。
1、游标:大数据范围的循环,Oracle不能很好的支持。会造成系统性能严重下降。
2、函数:函数同光标一样一行行的执行,效率也非常低。
3、"!=", "!>", "!<", "NOT", "NOT EXISTS", "NOT IN", "NOT LIKE",like %aaa%?等比较运算。他们都不会做索引。坚决反对使用。
4、不得建没有作用的事物:事物的启动需要一定的资源,请不要乱用例如产生报表时。 5、Select Into创建表:请使用显示定义Create table 。
特别的是不要在事物里创建表和临时表。
6、在Where字句中,Oracle的函数和字段一定的分离。坚决不得使用如下的写法: where Convert(varchar(10),fdate,112) = ?2003-09-06? 或者 where Substring(PNO,4,3) = ?001? 他们都是表完全扫描。
下面这些语句容易对服务器造成额外的负担,例如Order by 消耗了大量的CPU资源。所以要避免采用它,当然不是说不用他们。有时需要将结果集排序显示就一定要用到Order by,但不要用多余的Order by.
Order By:消耗了内存和CPU,在Temp中完成操作。
(1)Group By:同Order BY
(2) Having:同Order BY
(3) Distinct:同Order BY
(4)Union (尽量用Union All) :同Order BY
(5) in :没有Between快。
(6)视图:尽量少用。
(7)SELECT COUNT(*) :用Exists更好
(1)大批量装载数据的时候,如果有可能,尽量把数据库设置为非日志方式。装载数据完成以后,再把数据库恢复成原先的方式。
(2) 大批量装载数据的时候,尽量把内存参数、数据同步的参数设大。
(3)大批量装载数据的时候,避免使用insert语句,而应该使用数据库提供的装载工具或者采用游标insert方式来实现。
说明:多表连接的操作一般效率较差,在联机事务处理(OLTP)的应用中,应该尽量避免多表连接的操作,尽量避免建立多表的关系。
说明:SQL语句编写的好坏,直接影响到系统性能及增加数据库的负荷。SQL优化的实质就是在结果正确的前提下,用优化器可以识别的语句,充份利用索引,减少表扫描的I/O次数,尽量避免表搜索的发生。
(1)任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
(2)in、or子句常会使用工作表,使索引失效;如果不产生大量重复值,可以考虑把子句拆开;拆开的子句中应该包含索引。
(3) 多条件查询时候,根据最优化原则,指定要应用的索引,屏蔽非索引字段。
新建表、索引及关键字时,应带相关参数:
create table DF_CSDFYB ( QH VARCHAR2(2), SH VARCHAR2(4), YF VARCHAR2(6), CSHS NUMBER(14)) PCTFREE 20 INITRANS 2 MAXTRANS 255 TABLESPACE TBS1 STORAGE(INITIAL 1M NEXT 5M MINEXTENTS 1 MAXEXTENTS 2048 PCTINCREASE 0 BUFFER_POOL DEFAULT) LOGGING
1、 建议PCTINCREASE参数设置为0,可使碎片最小化,使每一个Extent都相同(等于NEXT值)。
2、 如果一个表无频繁删除,修改操作,建议PCTFREE参数适当设低,如有频繁删除,修改操 作可适当调高,如以上格式。
3、 根据表数据量的大小及将来的扩充 将STORAGE 中 INITIAL 、NEXT 合理设置,保证该表数据 尽量保持在同一块区,保证查询速度,减少I/O资源损耗。
4、 建立索引和关键字时候,指定特定专用的表空间,这样在处理数据时就可以充分利用磁盘I/O,使 数据和索引在不同的I/O上进行,以提高访问速度。
access,add,all,alter,and,any,as,asc,audit,between,bfile,blob,by,char,char,check,clob,cluster,column,comment,compress,connect,count,create,current date,date,decimal,decimal,default,delete,desc,distinct,drop else,exclusive,exists file,float,for,from grant,group,grouping,having,identified,immediate,in,increment,index,initial,insert,integer,integer,intersect,into,is,level,like,lock,long,maxextents,minus,mlslabel,mode,modify,noaudit,nocompress,not,nowait,null,number,number,of,offline,on,online,option,or,order,pctfree,prior,privileges,public,raw,rename,resource,revoke,row,rowid,rownum,rows,select,session,set,share,size,smallint,start,successful,sum,synonym,sysdate,table,then,to,trigger,type,uid,union,unique,update,user,validate,values,varchar,varchar2,varchar2,varchar,view,whenever,where,with
add,EXTERNAL,PROCEDURE,ALL,FETCH,PUBLIC,ALTER,FILE,RAISERROR,AND,FILLFACTOR,READ,ANY,FOR,READTEXT,AS,FOREIGN,RECONFIGURE,ASC,FREETEXT,REFERENCES,AUTHORIZATION,FREETEXTTABLE,REPLICATION,BACKUP,RESTORE,BEGIN,FULL,RESTRICT,BETWEEN,FUNCTION,RETURN,BREAK,GOTO,REVERT,BROWSE,GRANT,REVOKE,BULK,GROUP,RIGHT,BY,HAVING,ROLLBACK,CASCADE,HOLDLOCK,ROWCOUNT,CASE,IDENTITY,ROWGUIDCOL,CHECK,IDENTITY_INSERT,RULE,CHECKPOINT,IDENTITYCOL,SAVE,CLOSE,IF,SCHEMA,CLUSTERED,IN,SECURITYAUDIT,COALESCE,INDEX,SELECT,COLLATE,INNER,SEMANTICKEYPHRASETABLE,COLUMN,INSERT,SEMANTICSIMILARITYDETAILSTABLE,COMMIT,INTERSECT,SEMANTICSIMILARITYTABLE,COMPUTE,INTO,SESSION_USER,CONSTRAINT,is,SET,CONTAINS,JOIN,SETUSER,CONTAINSTABLE,KEY,SHUTDOWN,CONTINUE,KILL,SOME,CONVERT,LEFT,STATISTICS,CREATE,LIKE,SYSTEM_USER,CROSS,LINENO,TABLE,CURRENT,LOAD,TABLESAMPLE,CURRENT_DATE,MERGE,TEXTSIZE,CURRENT_TIME,NATIONAL,THEN,CURRENT_TIMESTAMP,NOCHECK,CURRENT_USER,NONCLUSTERED,TOP,CURSOR,NOT,TRAN,DATABASE,NULL,TRANSACTION,DBCC,NULLIF,Trigger,DEALLOCATE,OF,TRUNCATE,DECLARE,OFF,TRY_CONVERT,DEFAULT,OFFSETS,TSEQUAL,DELETE,ON,UNION,DENY,OPEN,UNIQUE,DESC,OPENDATASOURCE,UNPIVOT,DISK,OPENQUERY,UPDATE,DISTINCT,OPENROWSET,UPDATETEXT,DISTRIBUTED,OPENXML,USE,DOUBLE,OPTION,USER,DROP,OR,VALUES,DUMP,ORDER,VARYING,ELSE,OUTER,View,END,OVER,WAITFOR,ERRLVL,PERCENT,WHEN,ESCAPE,PIVOT,WHERE,EXCEPT,PLAN,WHILE,EXEC,PRECISION,WITH,EXECUTE,PRIMARY,WITHIN GROUP,EXISTS,PRINT,WRITETEXT,EXIT,PROC
参考资料:窦振海《数据库设计开发规范》

标签:disk uid remote ror compute 查询条件 安全 多表连接 ict
原文地址:http://www.cnblogs.com/wyh19941210/p/6719810.html