标签:png 测试 计算公式 数学 str target 实际应用 噪声 比较
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBC)。决策树模型通过构造树来解决分类问题。首先利用训练数据集来构造一棵决策树,一旦树建立起来,它就可为未知样本产生一个分类。在分 类问题中使用决策树模型有很多的优点:
和决策树模型相比,朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以 及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。 但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。在属 性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好
决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。 决策树模型也有一些缺点,比如处理缺失 数据时的困难,过度拟合问题的出现,以及忽略数据集中属性之间的相关性等。
决策树是一颗倒长的树,主要由根节点、分支、叶节点组成,每一个分支是一条规则,主要用于分类。决策树的算法主要有ID3、C4.5、CART,其中最为流行的事C4.5算法。针对每一种决策树的算法都要解决两个主要问题:
C4.5之所以流行的原因是:
信息增益
如何选择属性分裂对于规则来说是合适的,这就引出“熵”的概念。简而言之,“熵”是对混乱程度的度量,越乱熵越大,这也是为什么我让办公桌乱的原因。与之相对应的概念是“序”,就是有规律。越有序,越纯,熵越小;越乱,熵越大,越不纯;从数学的角度来看熵的计算公式如下:
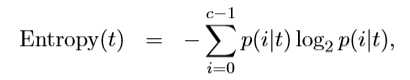
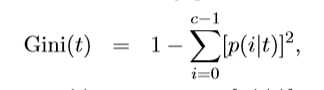
其中,p(i|t)表示节点t中属于类i所占的比例; 为了确定选择属性的分裂结果,我们用划分前(父节点)的不纯度和划分后(子女节点)的不纯度的差来来衡量属性分裂的测试结果,该指标成为信息增益,也就是熵的差,计算公式如下:
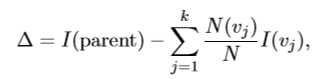
I(parent)是节点的值不纯性,k是属性的个数,决策树归纳通常选择最大化信息增益的属性做分裂;但是这样做有一个缺点:基于熵和Gini的不纯性的度量趋向于选择类别多的属性做分裂。可以这样理解,二元划分实际上相当于合并了多路属性,这个也可以用公式计算证明。那如何解决这个问题呢?有两种方法:一是限制测试属性只能是二元划分(这是CART的思想),二是修改衡量规则,于是C4.5提出采用信息增益率来划分,把属性测试产生的输出数也考虑进去,计算公式如下:
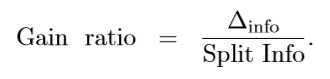
其中 split Info 的公式如下:
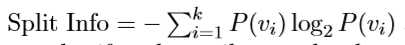
模型的误差
参考:http://blog.csdn.net/x454045816/article/details/44726921
http://www.zgxue.com/167/1677903.html
标签:png 测试 计算公式 数学 str target 实际应用 噪声 比较
原文地址:http://www.cnblogs.com/tgzhu/p/6691342.html