标签:count 防止 介绍 ase 大神 不同 计数 影响 干货
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~
周东谕,2011年加入腾讯,现任职于腾讯互娱运营部数据中心,主要从事游戏相关的数据分析和挖掘工作。
介绍信息增益之前,首先需要介绍一下熵的概念,这是一个物理学概念,表示“一个系统的混乱程度”。系统的不确定性越高,熵就越大。假设集合中的变量X={x1,x2…xn},它对应在集合的概率分别是P={p1,p2…pn}。那么这个集合的熵表示为:
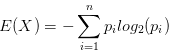
举一个的例子:对游戏活跃用户进行分层,分为高活跃、中活跃、低活跃,游戏A按照这个方式划分,用户比例分别为20%,30%,50%。游戏B按照这种方式划分,用户比例分别为5%,5%,90%。那么游戏A对于这种划分方式的熵为:
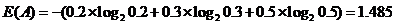
同理游戏B对于这种划分方式的熵为:
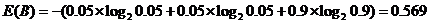
游戏A的熵比游戏B的熵大,所以游戏A的不确定性比游戏B高。用简单通俗的话来讲,游戏B要不就在上升期,要不就在衰退期,它的未来已经很确定了,所以熵低。而游戏A的未来有更多的不确定性,它的熵更高。
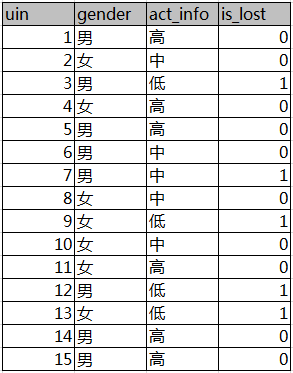
介绍完熵的概念,我们继续看信息增益。为了便于理解,我们还是以一个实际的例子来说明信息增益的概念。假设有下表样本
 !
!
第一列为QQ,第二列为性别,第三列为活跃度,最后一列用户是否流失。我们要解决一个问题:性别和活跃度两个特征,哪个对用户流失影响更大?我们通过计算信息熵可以解决这个问题。
按照分组统计,我们可以得到如下信息:
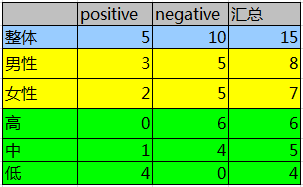
其中Positive为正样本(已流失),Negative为负样本(未流失),下面的数值为不同划分下对应的人数。那么可得到三个熵:
整体熵:
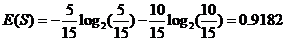
性别熵:
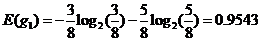
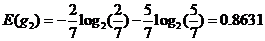
性别信息增益:
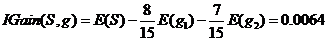
同理计算活跃度熵:
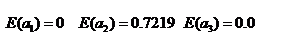
活跃度信息增益:
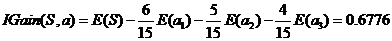
活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
从表2中我们不难发现,在计算信息熵和信息增益之前,需要对各维度做汇总计数,计算各公式中出现的分母。Hive SQL中,cube能帮助我们很快的做汇总计算,话不多说直接上代码:
SELECT
t1.feature_name,
SUM((ea_all/es)*EA) as gain,
SUM(NVL(-(ea_all/ES)*log2(ea_all/es),0)) as info,--计算信息增益率的分母
SUM((ea_all/es)*EA)/SUM(NVL(-(ea_all/es)*log2(ea_all/es),0)) as gain_rate--信息增益率计算
FROM
(
SELECT
feature_name,
feature_value,
ea_all,
--Key Step2 对于整体熵,要记得更换符号,NVL的出现是防止计算log2(0)得NULL
case
when feature_value=‘-100‘ then -(NVL((ea_positive/ea_all)*log2(ea_positive/ea_all),0)+NVL((ea_negative/ea_all)*log2(ea_negative/ea_all),0))
else (NVL((ea_positive/ea_all)*log2(ea_positive/ea_all),0)+NVL((ea_negative/ea_all)*log2(ea_negative/ea_all),0))
end as EA
FROM
(
SELECT
feature_name,
feature_value,
SUM(case when is_lost=-100 then user_cnt else 0 end) as ea_all,
SUM(case when is_lost=1 then user_cnt else 0 end) as ea_positive,
SUM(case when is_lost=0 then user_cnt else 0 end) as ea_negative
FROM
(
SELECT
feature_name,
--Key Step1 对feature值和label值做汇总统计,1、用于熵计算的分母,2、计算整体熵情况
case when grouping(feature_value)=1 then ‘-100‘ else feature_value end as feature_value,
case when grouping(is_lost)=1 then -100 else is_lost end as is_lost,
COUNT(1) as user_cnt
FROM
(
SELECT feature_name,feature_value,is_lost FROM gain_caculate
)GROUP BY feature_name,cube(feature_value,is_lost)
)GROUP BY feature_name,feature_value
)
)t1 join
(
--Key Step3信息增益计算时,需要给出样本总量作为分母
SELECT feature_name,COUNT(1) as es FROM gain_caculate
GROUP BY feature_name
)t2 on t1.feature_name=t2.feature_name
GROUP BY t1.feature_name
数据表结构如下:
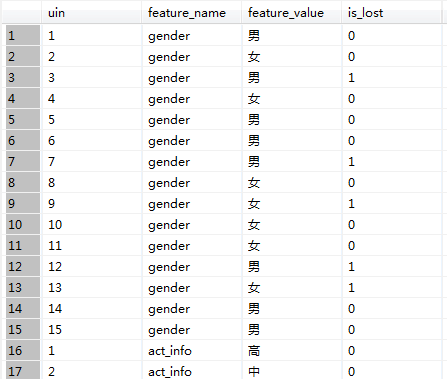
关键步骤说明:
KeyStep1:各特征的熵计算
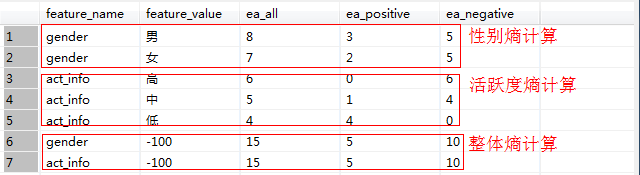
KeyStep2:各feature下的信息增熵
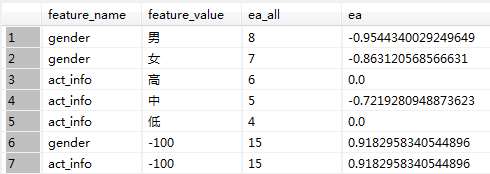
信息增益计算结果:

以上为信息熵计算过程的SQL版本,其关键点在于使用cube实现了feature和label所需要的汇总计算。需要的同学只需要按照规定的表结构填入数据,修改SQL代码即可计算信息增益。文中如有不足的地方,还请各位指正。
[1] 算法杂货铺——分类算法之决策树(Decision tree)
http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
[2] c4.5为什么使用信息增益比来选择特征?
https://www.zhihu.com/question/22928442
一条SQL搞定卡方检验计算
【腾讯云的1001种玩法】自建SQL Server迁移云SQL Server过程小记
小菜鸟对周志华大神gcForest的理解
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://www.qcloud.com/community/article/826876001491038171
获取更多腾讯海量技术实践干货,欢迎大家前往腾讯云技术社区
标签:count 防止 介绍 ase 大神 不同 计数 影响 干货
原文地址:http://www.cnblogs.com/qcloud1001/p/6735352.html