标签:ogre hadoop ops www can ace row cond 文件上传
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信。本篇将继续介绍hdfs文件上传、下载源解析。
先上文件上传的方法调用过程时序图:
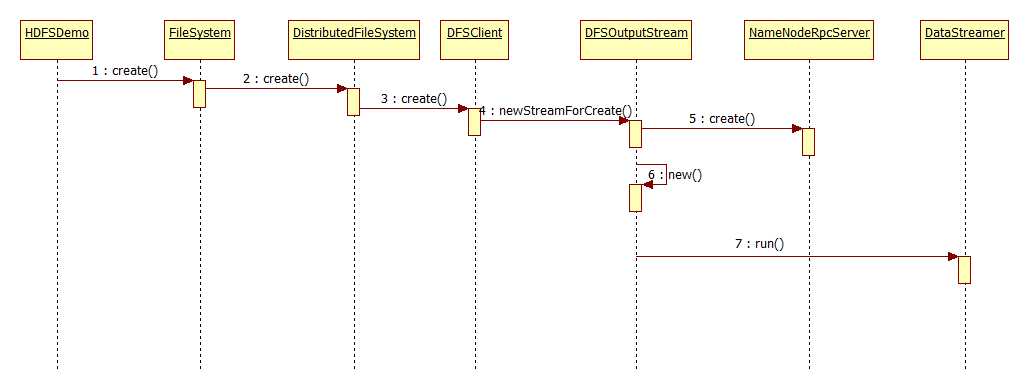
其主要执行过程:
下面我们来看下源码:
首先初始化文件系统,建立与服务端的RPC通信
1 HDFSDemo.java 2 OutputStream os = fs.create(new Path("/test.log"));
调用FileSystem的create()方法,由于FileSystem是一个抽象类,这里实际上是调用的该类的子类create()方法
1 //FileSystem.java 2 public abstract FSDataOutputStream create(Path f, 3 FsPermission permission, 4 boolean overwrite, 5 int bufferSize, 6 short replication, 7 long blockSize, 8 Progressable progress) throws IOException;
前面我们已经说过FileSystem.get()返回的是DistributedFileSystem对象,所以这里我们直接进入DistributedFileSystem:
1 //DistributedFileSystem.java 2 @Override 3 public FSDataOutputStream create(final Path f, final FsPermission permission, 4 final EnumSet<CreateFlag> cflags, final int bufferSize, 5 final short replication, final long blockSize, final Progressable progress, 6 final ChecksumOpt checksumOpt) throws IOException { 7 statistics.incrementWriteOps(1); 8 Path absF = fixRelativePart(f); 9 return new FileSystemLinkResolver<FSDataOutputStream>() { 10 @Override 11 public FSDataOutputStream doCall(final Path p) 12 throws IOException, UnresolvedLinkException { 13 final DFSOutputStream dfsos = dfs.create(getPathName(p), permission, 14 cflags, replication, blockSize, progress, bufferSize, 15 checksumOpt); 16 //dfs为DistributedFileSystem所持有的DFSClient对象,这里调用DFSClient中的create()方法 17 return dfs.createWrappedOutputStream(dfsos, statistics); 18 } 19 @Override 20 public FSDataOutputStream next(final FileSystem fs, final Path p) 21 throws IOException { 22 return fs.create(p, permission, cflags, bufferSize, 23 replication, blockSize, progress, checksumOpt); 24 } 25 }.resolve(this, absF); 26 }
DFSClient的create()返回一个DFSOutputStream对象:
1 //DFSClient.java 2 public DFSOutputStream create(String src, 3 FsPermission permission, 4 EnumSet<CreateFlag> flag, 5 boolean createParent, 6 short replication, 7 long blockSize, 8 Progressable progress, 9 int buffersize, 10 ChecksumOpt checksumOpt, 11 InetSocketAddress[] favoredNodes) throws IOException { 12 checkOpen(); 13 if (permission == null) { 14 permission = FsPermission.getFileDefault(); 15 } 16 FsPermission masked = permission.applyUMask(dfsClientConf.uMask); 17 if(LOG.isDebugEnabled()) { 18 LOG.debug(src + ": masked=" + masked); 19 } 20 //调用DFSOutputStream的静态方法newStreamForCreate,返回输出流 21 final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this, 22 src, masked, flag, createParent, replication, blockSize, progress, 23 buffersize, dfsClientConf.createChecksum(checksumOpt), 24 getFavoredNodesStr(favoredNodes)); 25 beginFileLease(result.getFileId(), result); 26 return result; 27 }
我们继续看下newStreamForCreate()中的业务逻辑:
1 //DFSOutputStream.java 2 static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src, 3 FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent, 4 short replication, long blockSize, Progressable progress, int buffersize, 5 DataChecksum checksum, String[] favoredNodes) throws IOException { 6 TraceScope scope = 7 dfsClient.getPathTraceScope("newStreamForCreate", src); 8 try { 9 HdfsFileStatus stat = null; 10 boolean shouldRetry = true; 11 int retryCount = CREATE_RETRY_COUNT; 12 while (shouldRetry) { 13 shouldRetry = false; 14 try { 15 //这里通过dfsClient的NameNode代理对象调用NameNodeRpcServer中实现的create()方法 16 stat = dfsClient.namenode.create(src, masked, dfsClient.clientName, 17 new EnumSetWritable<CreateFlag>(flag), createParent, replication, 18 blockSize, SUPPORTED_CRYPTO_VERSIONS); 19 break; 20 } catch (RemoteException re) { 21 IOException e = re.unwrapRemoteException( 22 AccessControlException.class, 23 DSQuotaExceededException.class, 24 FileAlreadyExistsException.class, 25 FileNotFoundException.class, 26 ParentNotDirectoryException.class, 27 NSQuotaExceededException.class, 28 RetryStartFileException.class, 29 SafeModeException.class, 30 UnresolvedPathException.class, 31 SnapshotAccessControlException.class, 32 UnknownCryptoProtocolVersionException.class); 33 if (e instanceof RetryStartFileException) { 34 if (retryCount > 0) { 35 shouldRetry = true; 36 retryCount--; 37 } else { 38 throw new IOException("Too many retries because of encryption" + 39 " zone operations", e); 40 } 41 } else { 42 throw e; 43 } 44 } 45 } 46 Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!"); 47 //new输出流对象 48 final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat, 49 flag, progress, checksum, favoredNodes); 50 out.start();//调用内部类DataStreamer的start()方法,DataStreamer继承Thread,所以说这是一个线程,从NameNode中申请新的block信息;
同时前面我们介绍hdfs原理的时候提到的流水线作业(Pipeline)也是在这里实现,有兴趣的同学可以去研究下,这里就不带大家看了 51 return out; 52 } finally { 53 scope.close(); 54 } 55 }
到此,Client拿到了服务端的输出流对象,那么后面就容易了,都是一些简答的文件输出,输入流的操作(hadoop提供的IOUitl)。
文件上传的大致流程与文件下载类似,与上传一样,我们先上程序方法调用时序图:
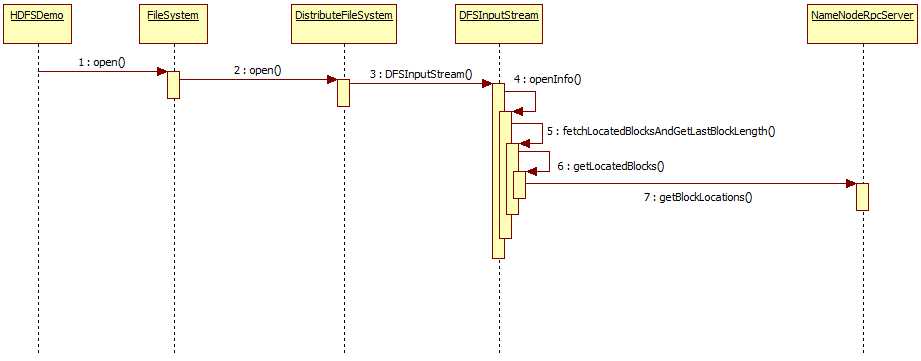
主要执行过程:
接下来,我们开始看源码:
首先任然是FileSystem的初始化,前面有,这里就不贴出来了,我们直接从DistributedFileSystem的open()开始看。
1 //DistributedFifeSystem.java 2 @Override 3 public FSDataInputStream open(Path f, final int bufferSize) 4 throws IOException { 5 statistics.incrementReadOps(1); 6 Path absF = fixRelativePart(f); 7 return new FileSystemLinkResolver<FSDataInputStream>() { 8 @Override 9 public FSDataInputStream doCall(final Path p) 10 throws IOException, UnresolvedLinkException { 11 final DFSInputStream dfsis = 12 dfs.open(getPathName(p), bufferSize, verifyChecksum); 13 //dfs为DFSClient对象,调用open()返回输入流 14 return dfs.createWrappedInputStream(dfsis); 15 } 16 @Override 17 public FSDataInputStream next(final FileSystem fs, final Path p) 18 throws IOException { 19 return fs.open(p, bufferSize); 20 } 21 }.resolve(this, absF); 22 }
DFSClient中并没有直接使用NameNode的代理对象,而是传给了DFSInputStream:
1 //DFSClient.java 2 public DFSInputStream open(String src, int buffersize, boolean verifyChecksum) 3 throws IOException, UnresolvedLinkException { 4 checkOpen(); 5 TraceScope scope = getPathTraceScope("newDFSInputStream", src); 6 try { 7 //这里并没有直接通过NameNode的代理对象调用服务端的方法,直接new输入流并把当前对象作为参数传入 8 return new DFSInputStream(this, src, verifyChecksum); 9 } finally { 10 scope.close(); 11 } 12 }
那么在DFSInputStream必须持有DFSClient的引用:
1 //DFSInputStream.java 构造 2 DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum 3 ) throws IOException, UnresolvedLinkException { 4 this.dfsClient = dfsClient;//只有DFSClient的引用 5 this.verifyChecksum = verifyChecksum; 6 this.src = src; 7 synchronized (infoLock) { 8 this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy(); 9 } 10 openInfo();//调openInfo() 11 }
openInfo()用来抓取block信息:
1 void openInfo() throws IOException, UnresolvedLinkException { 2 synchronized(infoLock) { 3 lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();//抓取block信息 4 int retriesForLastBlockLength = dfsClient.getConf().retryTimesForGetLastBlockLength;//获取配置信息,尝试抓取的次数,楼主记得在2.6以前这里写的3;当然,现在的默认值也为3 5 while (retriesForLastBlockLength > 0) { 6 if (lastBlockBeingWrittenLength == -1) { 7 DFSClient.LOG.warn("Last block locations not available. " 8 + "Datanodes might not have reported blocks completely." 9 + " Will retry for " + retriesForLastBlockLength + " times"); 10 waitFor(dfsClient.getConf().retryIntervalForGetLastBlockLength); 11 lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength(); 12 } else { 13 break; 14 } 15 retriesForLastBlockLength--; 16 } 17 if (retriesForLastBlockLength == 0) { 18 throw new IOException("Could not obtain the last block locations."); 19 } 20 } 21 }
获取block信息:
1 //DFSInputStream.java 2 private long fetchLocatedBlocksAndGetLastBlockLength() throws IOException { 3 final LocatedBlocks newInfo = dfsClient.getLocatedBlocks(src, 0); 4 //回到DFSClient中来获取当前block信息 5 if (DFSClient.LOG.isDebugEnabled()) { 6 DFSClient.LOG.debug("newInfo = " + newInfo); 7 } 8 if (newInfo == null) { 9 throw new IOException("Cannot open filename " + src); 10 } 11 12 if (locatedBlocks != null) { 13 Iterator<LocatedBlock> oldIter = locatedBlocks.getLocatedBlocks().iterator(); 14 Iterator<LocatedBlock> newIter = newInfo.getLocatedBlocks().iterator(); 15 while (oldIter.hasNext() && newIter.hasNext()) { 16 if (! oldIter.next().getBlock().equals(newIter.next().getBlock())) { 17 throw new IOException("Blocklist for " + src + " has changed!"); 18 } 19 } 20 } 21 locatedBlocks = newInfo; 22 long lastBlockBeingWrittenLength = 0; 23 if (!locatedBlocks.isLastBlockComplete()) { 24 final LocatedBlock last = locatedBlocks.getLastLocatedBlock(); 25 if (last != null) { 26 if (last.getLocations().length == 0) { 27 if (last.getBlockSize() == 0) { 28 return 0; 29 } 30 return -1; 31 } 32 final long len = readBlockLength(last); 33 last.getBlock().setNumBytes(len); 34 lastBlockBeingWrittenLength = len; 35 } 36 } 37 38 fileEncryptionInfo = locatedBlocks.getFileEncryptionInfo(); 39 //返回block开始写的位置 40 return lastBlockBeingWrittenLength; 41 }
回到DFSClient中:
1 DFSClient.java 2 @VisibleForTesting 3 public LocatedBlocks getLocatedBlocks(String src, long start, long length) 4 throws IOException { 5 TraceScope scope = getPathTraceScope("getBlockLocations", src); 6 try { 7 //这里NameNode作为参数传递到callGetBlockLocations()中 8 return callGetBlockLocations(namenode, src, start, length); 9 } finally { 10 scope.close(); 11 } 12 }
调用服务端方法,返回block信息:
1 //DFSClient.java 2 static LocatedBlocks callGetBlockLocations(ClientProtocol namenode, 3 String src, long start, long length) 4 throws IOException { 5 try { 6 //看到这里,不用做过多的解释了吧? 7 return namenode.getBlockLocations(src, start, length); 8 } catch(RemoteException re) { 9 throw re.unwrapRemoteException(AccessControlException.class, 10 FileNotFoundException.class, 11 UnresolvedPathException.class); 12 } 13 }
最终将文件block相关信息写入输入流,通过工具类IOUtil输出到本地文件。
那关于hadoop之hdfs原理及文件上传下载源码解析就写到这里,下系列的文章,楼主会写一些关于mapreduce或者hive相关的文章分享给大家。
示例代码地址:https://github.com/LJunChina/hadoop
标签:ogre hadoop ops www can ace row cond 文件上传
原文地址:http://www.cnblogs.com/qq503665965/p/6740992.html