标签:osi 读取 abc 意义 注意 ubuntu 可变参 系统调用 div
刚看完信号那章,觉得处理信号时的sigsetjmp/siglongjmp似乎跟异常的跳出很像,于是想去复习C++异常,然后发现了对I/O没有充分理解的问题。
题目是C++ Primer 5.6.3节的练习5.25,描述如下:
1、从标准输入读取2个整数, 输出第1个整数除以第2个整数的结果。
2、如果第2个整数为0,抛出异常;
3、用try语句块捕捉异常,catch语句中为用户输出一条提示信息,询问是否输入新数并重新执行try语句块的内容。
于是我随手一写,就写出了这样的代码
#include <stdio.h>
#include <stdexcept>
int main()
{
int x, y;
while (1) {
try {
fputs("input two numbers: ", stdout);
scanf("%d %d", &x, &y);
if (y == 0)
throw std::runtime_error("除数为0!");
printf("%d / %d = %d\n", x, y, x / y);
}
catch (std::exception& e) {
fputs(e.what(), stderr);
fputs("是否重新输入?[Y/n] ", stdout);
char ch = getchar();
if (ch == ‘Y‘ || ch == ‘y‘)
continue;
}
break;
}
return 0;
}

调试看看,在getchar()下面加一句printf("%d\n", ch);后重新运行,会发现打印的是10(ACSII码中换行符‘\n‘对应的是10)
也就是说getchar()不需要等待我们输入就获取了字符。那么这个换行符是怎么来的呢?
哦,刚才输入了"1 0"后是按了回车,然后scanf才执行。scanf读到第2个int对应字符串部分(‘0‘)终止就不再读了,也就是‘\n‘并没有读进去。而标准I/O库采取了缓存策略,标准输入的字符都放在一个字符串数组内,比如我刚才输入1、空格、0、Enter时,在标准输入(stdin)对应的FILE结构中,它的缓存(可以看做一个字符数组)是这样的
‘1‘, ‘ ‘, ‘0‘, ‘\n‘, ‘\0‘, ‘\0‘, ...
FILE结构有个指向当前位置的指针(注:下文中的指针均默认指代这个指针),最初是指向‘1‘的,然后进行scanf,读第2个int时,指针指向‘0‘,然后读取‘0‘,指针右移,此时指向‘\n‘,不是一个数字,开始分析scanf读到的2个int对应字符串"1"和"0"并且转换成int存入x和y的地址(&x和&y)中。
结果就是,指针指向的是‘\n‘,调用getchar()时,标准输入的缓存中已经有字符,那么直接取出即可。只有在标准输入的指针已经到达缓存非‘\0‘字符的末尾(即所谓字符数组风格字符串的末尾),才会阻塞进程并且等待用户输入,用户的输入会填入缓存,然后getchar()取得指针指向的字符。
回到这里,指针指向‘\n‘,那么getchar()就会把它取出来并返回,然后指针右移。因此我们需要接收到用户新输入的字符,需要像这样
getchar(); // 取出刚才的换行符 char ch = getchar();
如果熟悉库函数fflush(),很可能会采用fflush(stdin);的方式来取代getchar(),意思就是冲刷标准输入的缓存。
看似可行,但是,标准输入不同于标准输出(stdout)和标准错误(stderr),后两者被冲刷的话,指针右移直到字符串末尾,然后右移过程中的字符被输出到屏幕上(虽然这么说,但实际上是一次系统调用打印出来)。也不同于打开普通文件(txt等等)的FILE*,冲刷它们会把字符串输出到文本中。
那么,标准输入又能输出到哪呢?
POSIX.1-2001 did not specify the behavior for flushing of input streams, but the behavior is specified in POSIX.1-2008.
在POSIX.1-2001标准中,冲刷输入流的行为是未定义的。虽然POSIX新标准定义了其行为,我没有具体查看,但是在Ubuntu 16.04 gcc 5.4.0下,用-std=gnu++11编译得到的结果并不是我们期望的那样。尽管网上能搜到很多C语言考题会考fflush(stdin),还是VC6.0环境(我就不多说了,点到即止)
本来像上面那样更改代码后就OK了,但是健壮性较好的做法是只判断第1个字符即可,后面的字符随便输入,比如卸载软件的命令
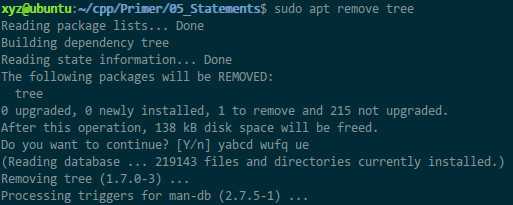
我输入了yabcd wufq ue这一段瞎按的字符串,只有首字母为y,但是卸载程序仍然执行了。
那么我的程序是否也能如此呢?

仅仅是输入了2个字符,结果不仅重新输入了一些信息,还直接返回了。
来分析一下程序的执行流程:
1、我输入了yy,此时从指针指向的位置起,缓存字符是‘\n‘, ‘y‘, ‘y‘;
2、getchar()读取‘\n‘,第2个getchar()读取‘y‘返回并赋值给字符ch,然后if语句判断ch是否为‘Y‘或‘y‘
3、if语句为真,执行continue;跳过while循环中剩余代码(即break;),重新进入while循环。
就此打住,注意,现在stdin的缓存是‘y‘,而scanf会根据格式化字符串"%d %d"读取,也就是首先要读1个int,如果碰到正负号和数字之外的字符会怎样呢?
把代码的scanf那句改成下面这样,检查返回值(scanf的返回值为成功格式化写入的变量个数)
int n = scanf("%d %d", &x, &y);
if (n != 2) {
fprintf(stderr, "scanf实际读取int的数量: %d\n", n);
return 1;
}
运行结果如下
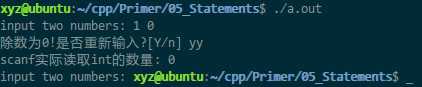
实际上碰到数字、正负号(还有空白字符)之外的字符就会返回,因为格式化输入已经不合法了。
关于printf和scanf的具体实现,主要是利用了C语言的可变参数类型va_list,具体可以参考C语言的经典教材《C程序设计语言》作者是丹尼斯·里奇(Dennis Ritchie),C语言之父&UNIX之父。7.3节 变长参数表里面提供了一份简化版printf的实现。
如果自己动手试着实现下,对printf/scanf的理解会更深刻。
于是回到问题,那我们该怎么解决呢?一个自然而然想到的方法是像刚才getchar()一样,把stdin的缓存全部读完,即在if语句之前加上
while (getchar() != ‘\n‘) { }
但是这会有调用函数的开销,比如我输入了10000个字符,那么就要调用getchar() 10000次。函数调用次数过多的话,开销就不能忽视了,因为每次函数调用都伴随着参数的入栈、出栈,函数栈帧的建立和销毁。
但是从性能的角度,可以采取更好的方法
char buf[BUFSIZ]; while (!fgets(buf, sizeof(buf), stdin)) { }
那就是减少函数调用的次数,每次获取BUFSIZ个字符,这样输入10000个字符的话只需要调用函数10000 / BUFSIZ次。
从实践的角度看,这种优化在这里其实没有必要,首先,没有谁那么无聊输入这么多字符,顶多不小心多按了几个字母。比如手滑按Enter键时把旁边的键给按下了。其次,这个程序本身就非常简单,甚至都不用考虑效率。
但是了解这些是有意义的。看源码不是为了重复造轮子,重复造轮子也不是仅仅为了重复造轮子,而是加深对底层实现的理解。既然选择了C/C++,就不得不去面对名为“效率”的怪物,不得不去了解底层实现。
最后再补充一点,C语言标准I/O库在终端I/O上默认是行缓冲,标准I/O库其实也要从应用态切换到内核态去调用内核的read/write等函数,10000次用户函数调用的开销也许不大,但是10000次上下文切换的开销就不小了。内核的I/O也有自己的一套缓存。所谓行缓冲,就是输入换行符时,一次性把目前为止输入/输出的所有字符进行I/O,也就是每读取一行(只要这一行不是特别特别长)只进行1次系统调用(system call)。(参考《Unix环境高级编程》)
因此每次输入换行符时,才把键盘输入的字符串一次性给搬运到内存中,然后scanf从头开始分析字符串。
从C++Primer某习题出发,谈谈C语言标准I/O的缓存问题
标签:osi 读取 abc 意义 注意 ubuntu 可变参 系统调用 div
原文地址:http://www.cnblogs.com/Harley-Quinn/p/6741677.html