标签:字符 alt 数据清洗 单词 通过 color let 文本 http
在进行中文分词统计前,往往要先把爬取下来的文本中包含的一些标签、标点符号、英文字母等过滤掉,这一过程叫做数据清洗。
#coding=utf-8 import re import codecs def strs_filter(file): with codecs.open(file,"r","utf8") as f,codecs.open("result.txt","a+","utf8") as c: lines=f.readlines() for line in lines: # line=line.decode(‘utf8‘) re_html=re.compile(‘<[^>]+>‘.decode(‘utf8‘))#从‘<‘开始匹配,不是‘>‘的字符都跳过,直到‘>‘ re_punc=re.compile(‘[\s+\.\!\/_,$%^*(+\"\‘]+|[+——!,。?、~@#¥%……&*“”《》:()]+‘.decode(‘utf8‘))#去除标点符号 re_digits_letter=re.compile(‘\w+‘.decode(‘utf8‘))#去除数字及字母 line=re_html.sub(‘‘,line) line=re_punc.sub("",line) line=re_digits_letter.sub("",line) c.write(line) strs_filter("strip.txt")
通过上面的代码可以去除与中文分词统计无关的内容,效果如下:
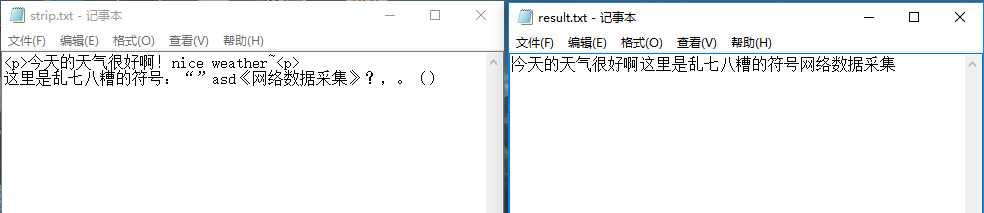
标签:字符 alt 数据清洗 单词 通过 color let 文本 http
原文地址:http://www.cnblogs.com/lovealways/p/6550249.html