标签:个数 分享 一段 sel 密钥 最优 需要 就会 数据交换
赫夫曼(Huffman)树,由发明它的人物命名,又称最优树,是一类带权路径最短的二叉树,主要用于数据压缩传输。
赫夫曼树的构造过程相对比较简单,要理解赫夫曼数,要先了解赫夫曼编码。
对一组出现频率不同的字符进行01编码,如果设计等长的编码方法,不会出现混淆的方法,根据规定长度的编码进行翻译,有且只有一个字符与之对应。比如设计两位编码的方法,A,B,C,D字符可以用00-11来表示,接收方只要依次取两位编码进行翻译就可以得出原数据,但如果原数据只由n个A组成的,那发出的编码就是2n个0组成,这样的压缩效率并不是十分理想(两位编码只是举例,实际上表示所有ASCII字符需要255个编码,则需要使用八位编码方式,这样如果原数据字符重复率较高的话,效果自然不理想)。如果设计的编码分别为:0,00,1和01,这样我发送了n个A组成的数据,这样一来只需要发送n个0,虽然会节省很多的数据传输量,但如果我传送了“0000”,则有多种翻译方法,可以翻译为“AAAA”,“ABB”,也不是可行的解决方案。如果有一种设计方式,用较短的编码表示出现频率较高的字符,用相对较长的编码表示出现频率相对较高的字符,而每个字符的解码不产生混淆,效果将会十分理想,而赫夫曼编码就是满足这种要求的编码方式,这种编码方式也叫前缀编码。
以一颗二叉树作为基础,规定左分支位0,右分支为1,以每个出现的字符作为各叶子节点的权值构造一颗赫夫曼树。在一颗赫夫曼树之中,从根节点出发,每经过一个节点(通过左子树或者右子树),解码出来的字符也随之一步步确定,因为从一个节点开始,通过左子树和右子树的结果是互斥的。
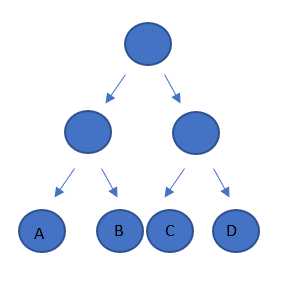 如左图所示,如果一开始从根节点开始,往右子树探索,则结果不可能会出现AB两种可能,再接下去往左子树探索就会得到C,往右子树就会得到D,保证在得到某一个字符之前的前缀编码不会是另一个字符的编码。回到前一段,如果我们把权值(出现频率)较高的节点放在深度较低的叶子节点上,权值较低的节点因为构造二叉树需要放的相对深一些,则可构造一颗赫夫曼数,具体方法如下:
如左图所示,如果一开始从根节点开始,往右子树探索,则结果不可能会出现AB两种可能,再接下去往左子树探索就会得到C,往右子树就会得到D,保证在得到某一个字符之前的前缀编码不会是另一个字符的编码。回到前一段,如果我们把权值(出现频率)较高的节点放在深度较低的叶子节点上,权值较低的节点因为构造二叉树需要放的相对深一些,则可构造一颗赫夫曼数,具体方法如下:
1)根据给定的n个权值{w1,w2,...,wn}构成n棵二叉树的集合F = {T1,T2,...,Tn},其中每棵二叉树Ti中只有一个带权位wi的根节点,其中左右子树均为空。
2)在F中选取两颗根节点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根节点的权值为其左,右子树上根节点的权值之和。
3)在F中删除这两棵树,同时将新的二叉树加入F中
4)重复(2)和(3)的过程,直到F只含一棵树为止。这棵树便是赫夫曼树。
文字描述可能有点费解,以下用一些示意图表示,整个过程可表示为:
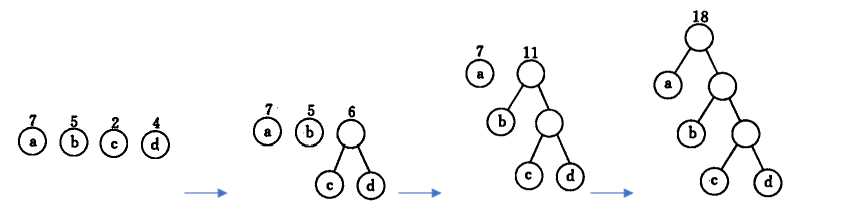
整个过程下来能够保证权值较小的叶子节点比较先被选择到,从而保证一套编码下来权值较大的叶子节点编码较短(因为深度比较低),而权值较小的叶子节点编码相对就长一点。因为权值小的字符出现概率低,所以平均下来这种编码方式能够达到较高的压缩率。
接下来是算法代码的实现,经过以上的理论,我们要完成的任务有:
1)用一个初始的字符串去构建一棵赫夫曼树(统计每个字符的出现次数作为权值),前提是这个字符串中字符出现的概率必须和数据交换时候字符出现的概率大致匹配。
2)完成赫夫曼树的构建(常用的字符叶子结点深度较浅,不常用的叶子结点深度较深),并求出每个字符对应的编码,存在一个Map数据结构中,这个Map暂称编码表
3)A要把一段数据传输给B,A对B说,我给你一棵赫夫曼树,到时候你就用这棵树对我发给你的内容进行解码,然后根据编码表求出原数据的编码并发给B
4)B根据收到的编码以赫夫曼树为基础进行解码,最后得出原数据内容
首先是树节点的数据结构:
class Node{ public: Type val; int weight; Node *parent,*left,*right; Node(Type v,int w):val(v),weight(w),parent(NULL),left(NULL),right(NULL){} Node(int w):weight(w),parent(NULL),left(NULL),right(NULL){} };
val为初始化字符的每个字符,weight,权值,即出现次数,left和right分别指向节点的左右子树,parent指向父节点。
构建赫夫曼树的核心代码为:
void builTree(){ int n = nodes.size()*2-1; for(int i = nodes.size();i<n;i++){ vector<int> ret = selMin2(nodes); nodes.push_back(new Node(nodes[ret[0]]->weight+nodes[ret[1]]->weight)); nodes[ret[0]]->parent = nodes.back(); nodes[ret[1]]->parent = nodes.back(); nodes.back()->left = nodes[ret[0]]; nodes.back()->right = nodes[ret[1]]; } root = nodes.back(); }
初始字符串经过统计之后存在nodes容器中,定义为 vector<Node*> nodes ,因为开始构建的时候nodes存储的全为叶子节点,所以预先求出整棵赫夫曼树总的节点数为 int n = nodes.size()*2-1; (一棵完全二叉树的总节点个数为所有叶子节点个数 x 2 - 1)其中selMin2()函数求出权值最小的且没有父节点的两个节点,返回这两个节点的下表,我自己写的复杂度为O(n),没有特别的优化过程。
完成赫夫曼树的构建后,从根节点开始求出每个叶子节点(字符)的编码:
void getcode(){ //encoding all the character recursively if(root != NULL) Recur(root,""); } void Recur(Node *node,string c){ if(!node->left && !node->right){ //leaf node code[node->val] = c; } else{ Recur(node->left,c+‘0‘); Recur(node->right,c+‘1‘); } }
一开始用”1111111111222222222333333334444444555555666667777888990”作为初始化字符串来构建赫夫曼树,写两个工具分别用于编码和解码,效果如下图所示:
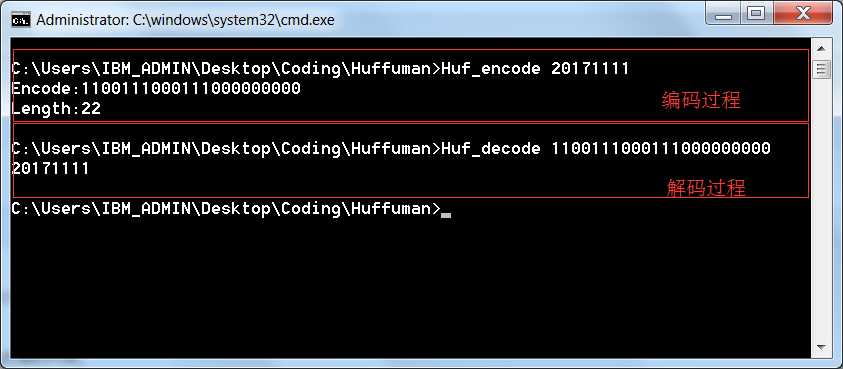
此处只是一个模拟过程,所以编码结果我在代码中只是用字符串“01”表示,实际上在压缩过程中是用bit表示,所以我的代码省略了A把编码转为bit表示的编码,然后B根据编码信息求出01字符串。
以上为本人对赫夫曼编码压缩(个人认为还能起到加密作用,此时赫夫曼树作为密钥)的拙见,文中的错误和不妥之处欢迎大家指出斧正。
以上代码皆由本人编写并成功运行,代码可分享,如有需要请在评论区留阁下的邮箱 ^_^
尊重知识产权,转载引用请通知作者并注明出处!
标签:个数 分享 一段 sel 密钥 最优 需要 就会 数据交换
原文地址:http://www.cnblogs.com/GNLin0820/p/6744890.html