标签:定时 blog 根据 不一致 ges 状态机 发展 写入 垂直
定义:分布式系统是一组分布在网络上通过消息传递进行协作的计算机组成系统。
分布式系统的意义
阿姆达尔定律:s(P)=1/((1-p)+p/N)
其中P指的是程序中可并行的部分的程序在单核上执行的时间的占比,N表示处理器的个数(核心数)。S(N)是指程序在N个处理器相对单个处理器的提升速度比。
单进程多线程和多进程的区别
线程是属于进程的,一个进程内的多个线程共享进程的内存空间;而多个进程之间的内存空间是相对独立的,因此多个进程间通过内存共享、交换数据的方式与多个线程间的方式就有所不同。多进程相对于单进程多线程的方式来说,资源控制更容易实现,此外多进程中单个进程出现问题不会造成整体不可用。
分布式系统的难点
4.事务的挑战。
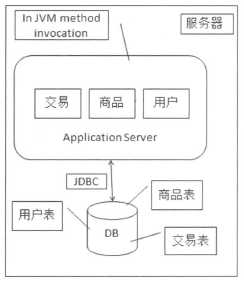
所有的功能模块和数据在单台服务器上,通过各个模块之间通过JVM内部的方法调用来进行交互,而应用和数据库之间是通过JDBC进行访问的。
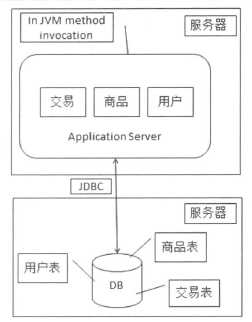
随着访问量的增加,服务器负载持续升高,考虑将应用服务器和数据库服务器分离。
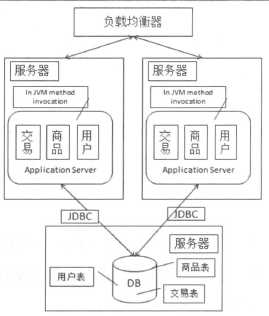
应用服务器压力变大时,根据对应用服务器的监测结果,可以考虑将服务器从一台变为两台,增加服务器后急需解决如下连个问题:
引入负载均衡设备后的架构
HTTP协议本生是无状态协议,需要基于HTTP协议支持回话(Session State)状态机制。具体的实现方式为:在回话开始时,分配一个唯一的回话标识(SessionID),通过Cookie把这个标识告诉浏览器,以后每次请求的时候,浏览器会带上这个会话标识告诉服务器请求数据那个会话。在Web服务器上,各个会话有独立的存储,保存不同的回话信息。如果遇到禁用Cookie的情况,一般的做法就是把这个回话标识放到URL的参数中。

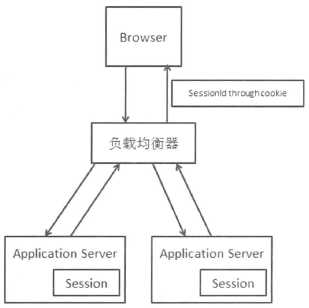
如上图所示,如果第一次网站请求在左边的服务器,那么Session保存在左边的服务器上,如果不做处理,就不能保证每次请求都落在同一台服务器上,这就是Session问题。
保证同一个回话的请求都落在同意Web服务器上,称为Session Stickey。
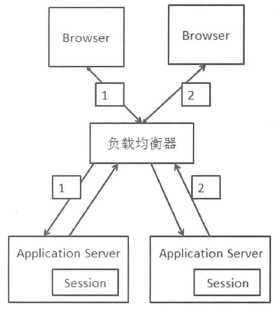
这种方案可以让同样的Session请求每次都发送到同一个服务器进行处理,非常利于对Session进行服务器端本地缓存。不过带来以下问题:
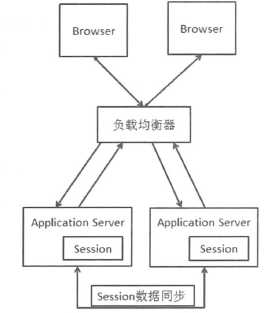
Session Replication在Web 服务器之间增加了会话数据同步机制,通过保证不同Web服务之间的Session数据的一致,来解决Session问题。一般的应用容器都支持Session Replication。和Session Replication相比,它对负载均衡设备没有要求,但是其本生也存在一些缺点。
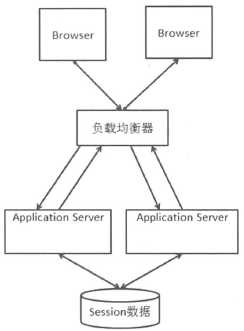
该方案的问题:
该方案通过Cookie来传递Session数据,将Session数据存放在Cookie中,然后在Web服务器上从Cookie中生成对应的Session数据。相对于Session 集中存储,这个方案不会依赖一个外部存储系统,也就不存在从外部系统获取、写入Session数据的网络时延。
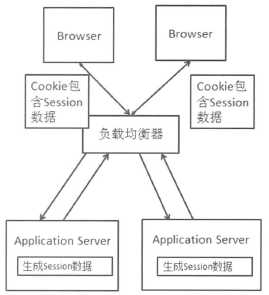
该方案存在的不足:
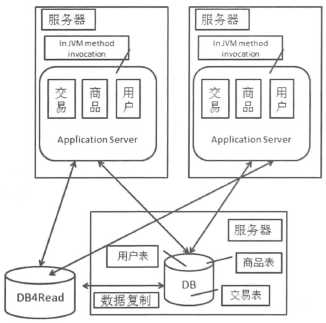
读写分离导致的问题:
数据库系统一般都提供了数据复制功能,但是对于数据复制还需要考虑数据复制的时延问题。数据复制延迟会带来数据短期不一致问题。于此同时,对于写操作主要走主库,事务中的读也要走主库,也要考虑到备库相对于主库的延迟。
搜索引擎要工作,首要的一点是需要根据被搜索的数据来构建索引。
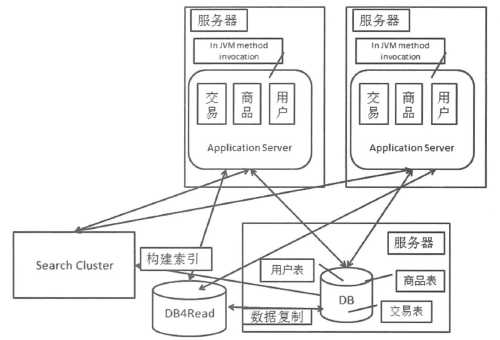
搜索集群的使用方式和读库的使用方式是一样的。可以从两个维度对搜索系统构建索引的方式进行划分:一种是按照全量/增量划分,另一种是按照实时/非实时划分。搜索引擎的技术解决了站内搜索时某些场景下的读的问题,提供更好的查询效率。
数据缓存
大型系统中的数据缓存主要用于分担数据库的读的压力。一般在缓存中存放的是“热”数据而不是全部数据。应用访问缓存,如果缓存不存在,则从数据读出数据后放入缓存。
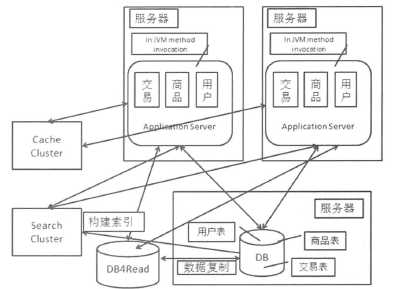
使用缓存来加速数据的读取情况,一个很关键的指标是缓存命中率,因此缓存命中率较低,意味着还有不少的请求回到数据库中。同时数据的分布于更新策略也要结合具体的场景来考虑。在分布上,要考虑的问题是需要避免局部热点,并且缓存服务器扩展或者缩容要尽量平滑。而在缓存的更新上,后有定时失效、数据变更时失效和数据变更时更新等策略。
分布式存储系统起到存储的作用,也就是提供读写支持。相对于读写分离中“读”源,分布式存储系统更多是直接替代主库。分布式存储系统通过集群提供了一个高容量、高并发访问、数据冗余容灾的支持。
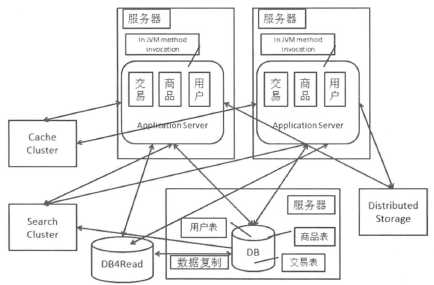
垂直拆分的意思就是把数据库中不同的业务数据拆分到不同的数据库中。
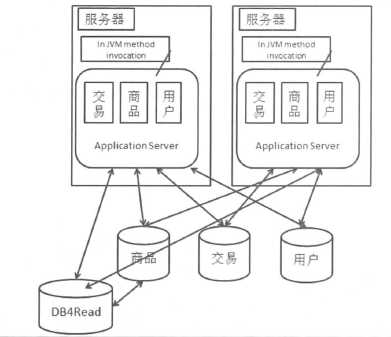
不同业务的数据从原来的一个数据库中拆分到多个数据库中,就需要考虑如何处理原来单机中跨业务的事务。一种办法是使用分布式事务,其性能明显要低于单机事务;另一种办法就是去掉事务或者不去追求强事务支持。对数据库进行垂直拆分之后,解决了把所有业务数据放在一个数据库的压力问题。并且也可以根据不同的业务特点进行优化。
数据库的水平拆分就是把同一个表中的数据拆分到两个数据库中。产生数据水平拆分的原因是某个业务的数据表的数据量或者更新量达到了单个数据库的瓶颈,这是就可以把这个表拆分到两个或者多个数据库中。数据库水平拆分会给业务带来一些影响:首先,要解决SQL路由的问题;其次主键的处理也会变得不同;最后由于同一个业务数据被拆分到了不同的数据库中,因此一些数据查询需要从两个数据库中读取数据,如果数据量较大需要分页就会比较难以处理。
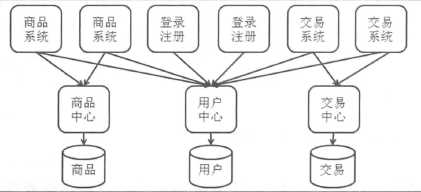
随着业务的发展,应用的功能越来越多,应用也会越来越大,这是需要把应用拆开,从一个应用变为两个甚至多个应用。
业务之间的访问不仅是单机内部的方法调用了,还引入了远程的服务调用;其次共享的代码不再是散落在不同的应用中了,这些实现被放在各个服务中心。
标签:定时 blog 根据 不一致 ges 状态机 发展 写入 垂直
原文地址:http://www.cnblogs.com/wxgblogs/p/6748608.html