标签:记录 filename datafile 在线编辑器 host put 特殊字符 使用 文件内容
一、正则表达式: 正则表达式(或称Regular Expression,简称RE)就是由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。 该模式描述在查找文字主体时待匹配的一个或多个字符串。 正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。简单的说,正则表示式就是处理字符串的方法,它是以行为单位来进行字符串的处理行为, 正则表示式通过一些特殊符号的辅助,可以让使用者轻易的达到搜寻/删除/取代某特定字符串的处理程序。vim、grep、find、awk、sed等命令都支持正则表达式。 常用正则表达式: 1、.代表任意单个字符, 如:/l..e/与包含一个l,后跟两个字符,然后跟一个e的行相匹配 ? 匹配零个或一个字符。如:‘gr?p‘匹配gr后跟一个或没有字符,然后是p的行 2、^代表行的开始。 ^love 如:与所有love开头的行匹配 3、$代表行的结束。love$ 如:与所有love结尾的行匹配 那么‘^$’ 就表示空行 4、[…]匹配括号中的字符之一 [abc] 匹配单个字符a或b或c [123] 匹配单个字符1或2或3 [a-z] 匹配小写字母a-z之一 [a-zA-Z] 匹配任意英文字母之一 [0-9a-zA-Z]匹配任意英文字母或数字之一 注意:上面标红色的单个和之一,不管[]里面多复杂,它的结果都是一个字符! 可以用^标记做[]内的前缀,表示除[]内的字符之外的字符。比如 搜索oo前没有g的字符串的行. 应用 ‘[^g]oo‘ 作搜索字符串,^符号如果出现在[]的起始位置表示否定,但是在[]的其他位置是普通字符。[^ab^c] 匹配b或^或c或不是a的任意单个字符 5、* 用于修饰前导字符,表示前导字符出现0次或任意多次 如:‘a*grep‘匹配所有0个或多个a后紧跟grep的行。“.*”表示任意字符串 6、\? 用于修饰前导字符,表示前导字符出现0或1次 a\? 匹配0或1个a 7、\+ 用于修饰前导字符,表示前导字符出现1或多次 a\+ 匹配1或多个a 8、\{n,m\} 用于修饰前导字符,表示前导字符出现n至m次 (n和m都是整数,且n<m) a\{3,5\} 匹配3至5个连续的a \{n,m\}还有其他几种形式: \{n\} 连续的n个前导字符 \{n,\} 连续的至少n个前导字符 9、\ 用于转义紧跟其后的单个特殊字符,使该特殊字符成为普通字符 如:^\.[0-9][0-9] 对以一个句点和两个数字开始 例如: a* 匹配连续的任意(也包括0)个a a\? 匹配0或1个a a\+ 匹配1或多个a a\{3,5\} 匹配3至5个连续的a \.* 匹配0或多个连续的. \.表示普通字符句点 10、|表示或 如: a|b|c 匹配a或b或c。如:grep|sed匹配grep或sed 11、(),将部分内容合成一个单位组,比如 要搜索 glad 或 good 可以如下 ‘g(la|oo)d‘ 综合举例1: 1 Christian Scott lives here and will put on a Christmas party. 2 There are around 30 to 35 people invited. 3 They are: 4 Tom 5 Dan 6 Rhonda Savage 7 Nicky and Kimerly. 8 Steve, Suzanne, Ginger and Larry. ^[A-Z]..$ 搜索行以A至Z的一个字母开头,然后跟两个任意字母,然后跟一个换行符的行。将找到第5行。 ^[A-Z][a-z]*3[0-5] 搜索以一个大写字母开头,后跟0个或多个小写字母,再跟数字3,再跟0—5之间的一个数字。无法找到匹配行(改成^[A-Z][a-z]*.*3[0-5]可找到第2行) ^ *[A-Z][a-z][a-z]$ 搜索以0个或多个空格开头,跟一个大写字母,两个小写字母和一个换车符。将找到第4行的TOM(整行匹配)和第5行。注意,*前面有一个空格。 ^[A-Za-z]*[^,][A-Za-z]*$ 将查找以0个或多个大写或小写字母开头,不跟逗号,然后跟0个或多个大写或小写字母,然后跟一个换车符。将找到第4和5行。 综合举例2: # ls -l /bin | grep ‘^...s‘ 上面的命令是用来查找suid文件的; # ls -lR /usr | grep ‘^...s..s‘ 上面的命令是用来查找suid和guid的。 二、grep命令的用法 grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来. 参数: 1. -A NUM,--after-context=NUM 除了列出符合行之外,并且列出后NUM行。 如: $ grep –A 1 panda file (从file中搜寻有panda样式的行,并显示该行的后1行) 2. -B NUM,--before-context=NUM 与 -A NUM 相对,但这此参数是显示除符合行之外并显示在它之前的NUM行。如: (从file中搜寻有panda样式的行,并显示该行的前1行) $ grep -B 1 panda file 3、 -C [NUM], -NUM, --context[=NUM] 列出符合行之外并列出上下各NUM行,默认值是2。 如: (列出file中除包含panda样式的行外并列出其上下2行)(若要改变默认值,直接改变NUM即可) $ grep -C[NUM] panda file 4、 -c, --count 不显示符合样式行,只显示符合的总行数。若再加上-v,--invert-match,参数显示不符合的总行数 5、-i,--ignore-case 忽略大小写差别 6、-n,--line-number 在匹配的行前面打印行号 7、-v,--revert-match 反检索,只显示不匹配的行 8、精确匹配: 例如在抽取字符串“ 48”,返回结果包含诸如484和483等包含“48”的其他字符串,实际上应精确抽取只包含48的各行。 使用grep抽取精确匹配的一种有效方式是在抽取字符串后加\>。假定现在精确抽取48, 方法如下: #grep ‘48\>‘ filename 9、-s 不显示不存在或无匹配文本的错误信息 如:执行命令grep "root" /etc/password,因为password文件不存在,所以在屏幕上输出错误信息,若使用grep命令-s开关,可屏蔽错误信息 要用好grep这个工具,其实就是要写好正则表达式,所以这里不对grep的所有功能进行实例讲解,只列几个例子,讲解一个正则表达式的写法。 $ ls -l | grep ‘^d‘ 通过管道过滤ls -l输出的内容,只显示以d开头的行。 $ grep ‘test‘ d* 显示所有以d开头的文件中包含test的行。 $ grep ‘test‘ aa bb cc 显示在aa,bb,cc文件中匹配test的行。 $ grep ‘[a-z]\{5,\}‘ aa 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。 $grep ‘t[a|e]st’ filename 显示包含test或tast的所有行。 $grep ‘\.$‘ filename 显示以.为结尾的所有行。 三、sed命令的用法 sed是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。 sed的基本命令: 1.替换: s命令 1.1 基本用法 如: sed ‘s/day/night/‘ <old >new 该例子将文件 old 中的每一行第一次出现的 day 替换成 night, 将结果输出到文件 new s " 替换 " 命令 /../../ 分割符 (Delimiter) day 搜索字符串 night 替换字符串 其实 , 分割符 "/" 可以用别的符号代替 , 比如 ",", "|" 等 . 如:sed ‘s/\/usr\/local\/bin/\/common\/bin/‘<old >new 等价于 sed ‘s_/usr/local/bin_/common/bin_‘ <old >new 显然 , 此时用 "_" 作分割符比 "/" 好得多 1.2 用 & 表示匹配的字符串 有时可能会想在匹配到的字符串周围或附近加上一些字符 . 如: sed ‘s/abc/(abc)/‘ <old >new 该例子在找到的 abc 前后加上括号 . 该例子还可以写成 sed ‘s/abc/(&)/‘ <old >new 下面是更复杂的例子 : sed ‘s/[a-z]*/(&)/‘ <old >new sed 默认只替换搜索字符串的第一次出现 , 利用 /g 可以替换搜索字符串所有 $ sed ‘s/test/mytest/g‘ example-----在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。 $ sed ‘s/^192.168.0.1/&localhost/‘ example-----&符号表示替换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。 $ sed ‘s#10#100#g‘ example-----不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。 如果需要对同一文件或行作多次修改,可以使用 "-e" 选项
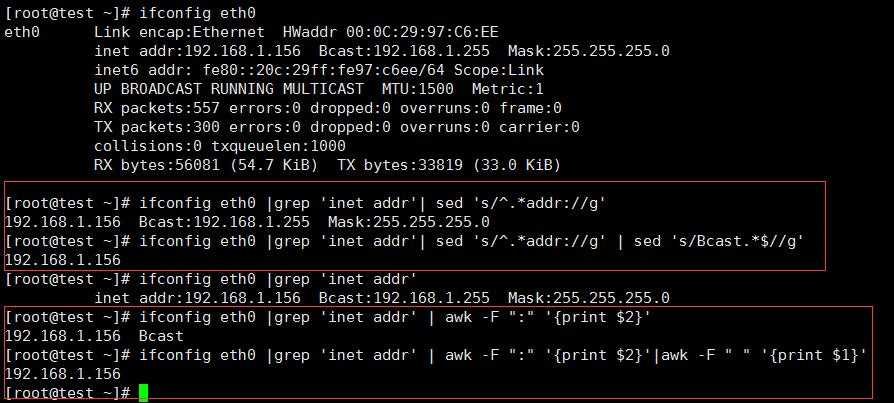
取得eth0网卡IP地址:
2.删除行:d命令
从某文件中删除包含 "how" 的所有行
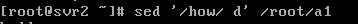
将/etc/passwd的内容显示并找印行号,同时将2~5删除
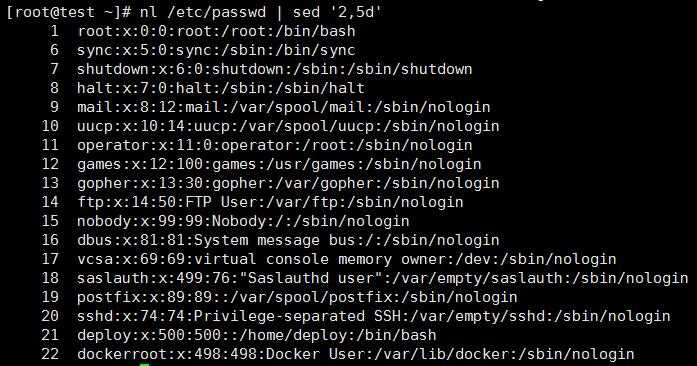
附:nl命令在linux系统中用来计算文件中行号。nl 可以将输出的文件内容自动的加上行号
如果只要删除第2行,可以使用nl /etc/passwd | sed ‘2d‘ 来达成,至于若是要删除第 3 到最后一行,则是nl /etc/passwd | sed ‘3,$d‘即可。
3.增加行:a命令(在指定的行后新增)或i命令(在指定的行前新增)
a的后面可以接字符串,而这些字符串会在新的一行出现
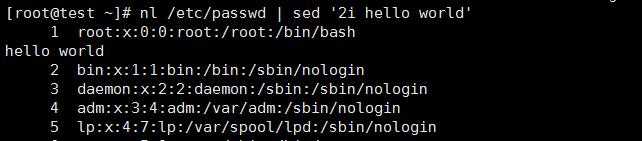
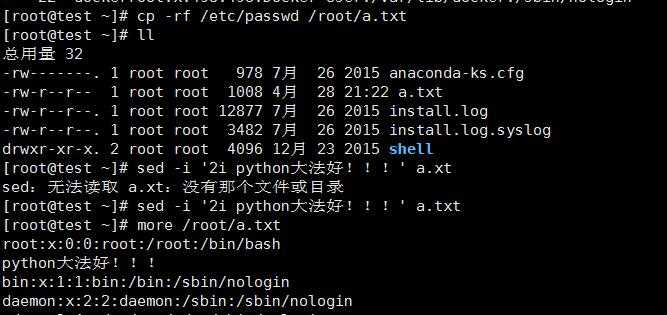
在/etc/passwd的第二行后增加“XXXXX”字样的新行
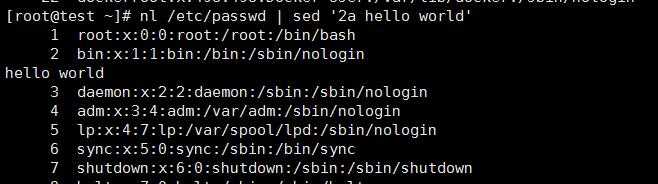
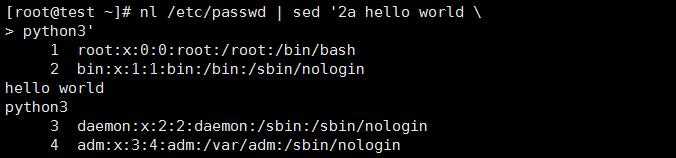
在/etc/passwd的第二行前增加“XXXXX”字样的新行
如果要同时新增多行,则每行之间要用反斜杠\来进行新行的添加
4、取代行:c命令
c的后面可以接字符串,这些字符串可以取代n1,n2之间的行

5、打印:p命令
sed ‘/north/p‘ datafile 默认输出所有行,找到north的行重复打印
sed –n ‘/north/p‘ datafile 禁止默认输出,只打印找到north的行
nl /etc/passwd | sed -n ‘5,7p‘ 仅列出/etc/passwd文件中的第5~7行内容
注:sed 的-i选项可以直接修改文件中的内容
6.扩展:
调用sed有三种方式:
l 在命令行键入命令
l 将sed命令插入脚本文件,然后调用sed
l 将sed命令插入脚本文件,并使sed脚本可执行。
A、 使用sed命令行格式为:
sed [选项] sed命令 输入文件。
记住在命令行使用sed命令时,实际命令要加单引号。sed也允许加双引号。
B、使用sed脚本文件,格式为:
sed [选项] -f sed脚本文件 输入文件
C、要使用第一行具有sed命令解释器的sed脚本文件,其格式为:
sed脚本文件 [选项] 输入文件
不管是使用shell命令行方式或脚本文件方式,如果没有指定输入文件, sed从标准输入中接受输入,一般是键盘或重定向结果。
sed选项如下:
-f, --filer=script-file 引导sed脚本文件名
五、awk命令:
awk也是一个数据处理工具!相较于 sed 常常作用于一整个行的处理, awk 则比较倾向于一行当中分成数个字段来处理。
.awk语言的最基本功能是在文件或字符串中基于指定规则来分解抽取信息,也可以基于指定的规则来输出数据。
有三种方式调用awk
1.命令行方式
awk [-F field-separator] ‘commands‘ input-files
其中,[-F域分隔符]是可选的,因为awk使用空格或tab键作为缺省的域分隔符,因此如果要浏览域间有空格的文本,不必指定这个选项,如果要浏览诸如passwd文件,此文件各域以冒号作为分隔符,则必须指明-F选项,如:awk -F: ‘commands‘ input-file。
commands 是真正awk命令, input-files 是待处理的文件。
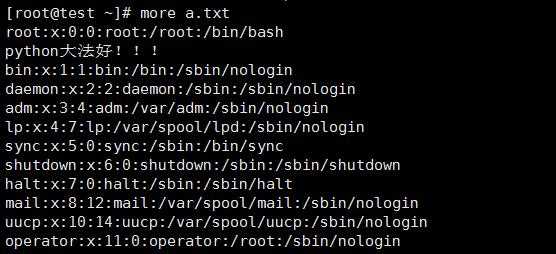
输出结果如下,字段以:分割,取到每行的第一个字段

iput_files可以是多于一个文件的文件列表,awk将按顺序处理列表中的每个文件。
在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格或tab键。
2.shell脚本方式
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,以便通过键入脚本名称来调用。
相当于shell脚本首行的:#!/bin/sh可以换成:#!/bin/awk
3.将所有的awk命令插入一个单独文件,然后调用:
Awk -f awk-script-file input-files
其中,-f选项加载awk-script-file中的awk脚本,input-files跟上面的是一样的。
awk的模式和动作
任何awk语句都由模式和动作组成(awk_pattern { actions })。
在一个awk脚本中可能有许多语句。
模式部分决定动作语句何时触发及触发事件。处理即对数据进行的操作。如果省略模式部分,动作将时刻保持执行状态。即省略时不对输入记录进行匹配比较就执行相应的actions。
模式可以是任何条件语句或正则表达式等。awk_pattern可以是以下几种类型:
1) 正则表达式用作awk_pattern: /regexp/
例如:awk ‘/ ^[a-z]/‘ input_file
2) 布尔表达式用作awk_pattern,表达式成立时,触发相应的actions执行。
① 表达式中可以使用变量(如字段变量$1,$2等)和/regexp/
② 布尔表达式中的操作符:
关系操作符: <
> <= >= == !=
匹配操作符: value ~ /regexp/ 如果value匹配/regexp/,则返回真
value
!~ /regexp/ 如果value不匹配/regexp/,则返回真
例如: awk ‘$2 > 10 {print "ok"}‘ input_file
awk ‘$3 ~ /^d/ {print
"ok"}‘ input_file
③ &&(与) 和 ||(或) 可以连接两个/regexp/或者布尔表达式,构成混合表达式。!(非) 可以用于布尔表达式或者/regexp/之前。
例如: awk ‘($1
< 10 ) && ($2 > 10) {print "ok"}‘ input_file
awk ‘/^d/ || /x$/ {print "ok"}‘
input_file
模式包括两个特殊字段 BEGIN和END。使用BEGIN语句设置计数和打印头。BEGIN语句使用在任何文本浏览动作之前,之后文本浏览动作依据输入文本开始执行。END语句用来在awk完成文本浏览动作后打印输出文本总数和结尾状态标志。
实际动作在大括号{ }内指明。动作大多数用来打印,但是还有些更长的代码诸如i f和循环语句及循环退出结构。如果不指明采取动作,awk将打印出所有浏览出来的记录。
awk执行时,其浏览域标记为$1,$2...$n。这种方法称为域标识。使用这些域标识将更容易对域进行进一步处理。
使用$1 , $3表示参照第1和第3域,注意这里用逗号做域分隔。如果希望打印一个有5个域
的记录的所有域,不必指明$1 , $2 , $3 , $4 , $5,可使用$0,意即所有域。
为打印一个域或所有域,使用print命令。这是一个awk动作
awk的运行过程:
① 如果BEGIN 区块存在,awk执行它指定的actions。
② awk从输入文件中读取一行,称为一条输入记录。(如果输入文件省略,将从标准输入读取)
③ awk将读入的记录分割成字段,将第1个字段放入变量$1中,第2个字段放入$2,以此类推。$0表示整条记录。
④ 把当前输入记录依次与每一个awk_cmd中awk_pattern比较,看是否匹配,如果相匹配,就执行对应的actions。如果不匹配,就跳过对应的actions,直到比较完所有的awk_cmd。
⑤ 当一条输入记录比较了所有的awk_cmd后,awk读取输入的下一行,继续重复步骤③和④,这个过程一直持续,直到awk读取到文件尾。
⑥ 当awk读完所有的输入行后,如果存在END,就执行相应的actions。
实例:
例1:显示/etc/passwd文件中的用户名和登录shell
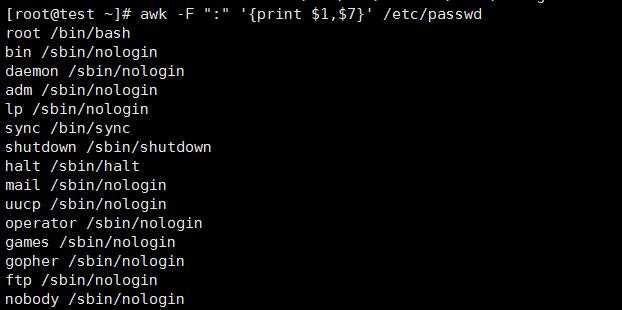
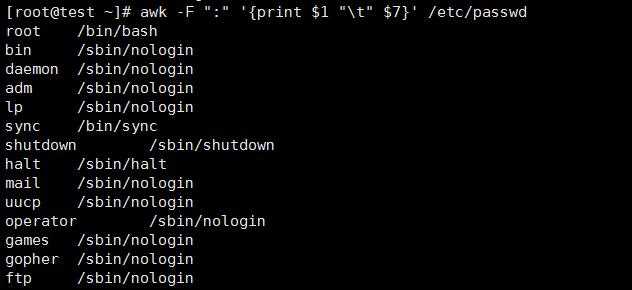
显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
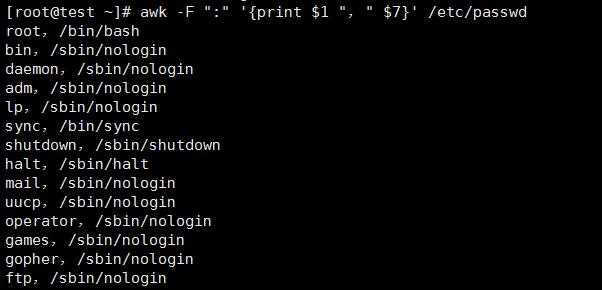
显示/etc/passwd文件中的用户名和登录shell, 而账户与shell之间以逗号分割
注:
1.awk 后面接两个单引号并加上大括号 {} 来设定想要对数据进行的处理动作
2.awk工作流程是这样的:先执行BEGING,然后读取文件,读入有\n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n
标签:记录 filename datafile 在线编辑器 host put 特殊字符 使用 文件内容
原文地址:http://www.cnblogs.com/menglingqian/p/6783527.html