标签:ide 内存地址 eve ever 文章 python学习 复制 ble 编码
python首次执行某个文件,会生成一个pyc的编译文件,下次执行的时候首先会找是否有pyc文件,再检查文件日期,这样会减少编译时间
import 模块名
现在当前文件路径下找模块名,再在python的环境变量里面找
安装第三方模块,默认会安装在$python3.5\Lib\site-packages目录里
在win上用pip命令安装报错:unable to create process using ‘‘‘‘
百度了下:python -m pip install 模块文件
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
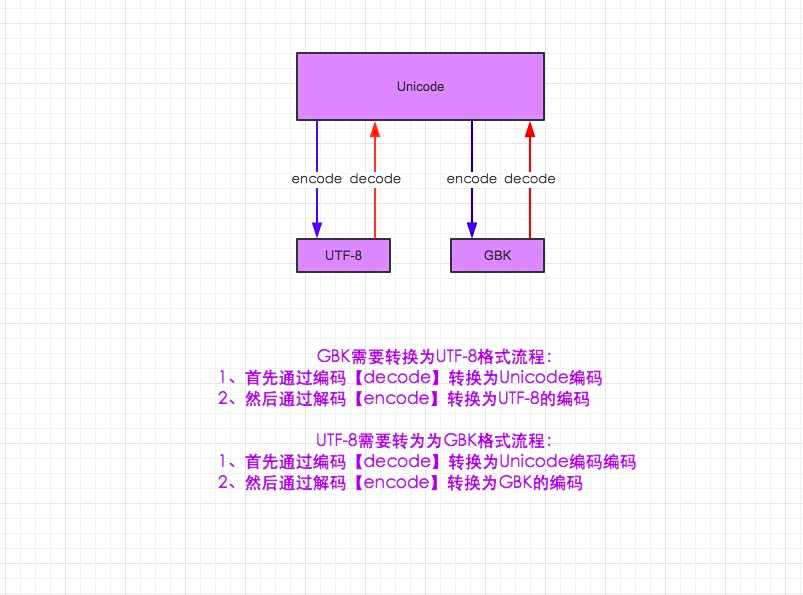
上图仅适用于py2
1 #-*-coding:utf-8-*- 2 __author__ = ‘Alex Li‘ 3 4 import sys 5 print(sys.getdefaultencoding()) 6 7 8 msg = "我爱北京天安门" 9 msg_gb2312 = msg.decode("utf-8").encode("gb2312") 10 gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") 11 12 print(msg) 13 print(msg_gb2312) 14 print(gb2312_to_gbk) 15 16 in python2

#-*-coding:gb2312 -*- #这个也可以去掉 __author__ = ‘Alex Li‘ import sys print(sys.getdefaultencoding()) msg = "我爱北京天安门" #msg_gb2312 = msg.decode("utf-8").encode("gb2312") msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔 gb2312_to_unicode = msg_gb2312.decode("gb2312") gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") print(msg) print(msg_gb2312) print(gb2312_to_unicode) print(gb2312_to_utf8) in python3
可以用.count("name")去查看你
如:
list1 = [1,2,3,4,1,2,5,]
print(list1)
print(list1.count(2))
输出:

names = [‘cui‘,‘wang‘,‘luo‘,‘zhang‘,‘xu‘]
print(names)
names_1 = names
print(names_1)
names[1] = ‘zhao‘
print(names)
print(names_1)
print(id(names))
print(id(names_1))
输出为:
[‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘] [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘] [‘cui‘, ‘zhao‘, ‘luo‘, ‘zhang‘, ‘xu‘] [‘cui‘, ‘zhao‘, ‘luo‘, ‘zhang‘, ‘xu‘]
11928968
11928968
可以看到如果列表采用c = a, a= b,b = c,这种a,b互换值是不行的,列表1 =列表2 仅仅只是复制了对对象的引用,即 names 和 names_1 指向的是同一个对象,所以如果改变了该对象的元素的话,则两个表所指向的对象都会改变,因为实际上就是同一个对象。可以由id(names)和id(names_1)看出两者指向的对象在内存中的地址是相同的,即是同一个对象
补充一下:列表2 = 列表1*n,将列表1里面的元素翻n倍,列表2与列表1为相互独立的列表
>>> names = [‘cui‘,‘hu‘,‘zhang‘,‘wang‘,‘luo‘] >>> names_copy = names * 3 >>> names_copy [‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘, ‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘, ‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘] >>> print(id(names),id(names_copy)) 56032904 55907784
names = [‘cui‘,‘wang‘,‘luo‘,[‘zou‘,29],‘zhang‘,‘xu‘] print(names) names_copy = names.copy() names[0] = ‘CUI‘ #更改names列表里的第一个值 names[3][0] = ‘ZOU min‘ #更改names列表里第三个列表里的第一个值 print(names) print(names_copy)
[‘cui‘, ‘wang‘, ‘luo‘, [‘zou‘, 29], ‘zhang‘, ‘xu‘] [‘CUI‘, ‘wang‘, ‘luo‘, [‘ZOU min‘, 29], ‘zhang‘, ‘xu‘] [‘cui‘, ‘wang‘, ‘luo‘, [‘ZOU min‘, 29], ‘zhang‘, ‘xu‘]
浅copy是最常用的copy,只会copy列表第一层的对象,列表第一层改动的时候,不会影响copy的列表,但是第二层改动便会影响,因为这个例子中的子列表
令有3种实现方式:
import copy names = [‘cui‘,‘wang‘,‘luo‘,[‘zou‘,29],‘zhang‘,‘xu‘] print(names) names_copy = copy.copy(names)
######################
names_copy = list(names)
##########################
names_copy = names[:]
1 import copy 2 names = [‘cui‘,‘wang‘,‘luo‘,[‘zou‘,29],‘zhang‘,‘xu‘] 3 print(names) 4 names_copy = copy.deepcopy(names) 5 names[0] = ‘CUI‘ #更改names列表里的第一个值 6 names[3][0] = ‘ZOU min‘ #更改names列表里第三个列表里的第一个值 7 print(names) 8 print(names_copy)
print(id(names),id(names_copy))
输出
[‘cui‘, ‘wang‘, ‘luo‘, [‘zou‘, 29], ‘zhang‘, ‘xu‘] [‘CUI‘, ‘wang‘, ‘luo‘, [‘ZOU min‘, 29], ‘zhang‘, ‘xu‘] [‘cui‘, ‘wang‘, ‘luo‘, [‘zou‘, 29], ‘zhang‘, ‘xu‘]
14440968 14441480
看出,无论names如何改动,都不影响names_copy,反之亦然,因为两者指定的是完全不同的内存地址
列表元素的下表是从左到右是从0,1,2。。。。。,从右到左是-1,-2,-3
切片的原则是包头不包尾如names[1:-1]指选择第2个元素(下标为1)到倒数第2个(倒数第一个前面那一个)
names [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘] names[-2:-1] [‘zhang‘] names[0:2] [‘cui‘, ‘wang‘] names[0:] [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘] names[:-2] [‘cui‘, ‘wang‘, ‘luo‘] names[:] [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘]
下标0是可以省略的,names[:]表示全部,names[-3:]表示倒数3个
names.append(‘NEW‘) names [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘, ‘NEW‘]
names = [‘cui‘,‘wang‘,‘luo‘,‘zhang‘,‘xu‘] names.insert(1,‘charu1‘) names.insert(-1,‘end‘) #在最后元素的前面插入‘end‘ print(names)
最后面插入可以用上面的追加
names[-2] = ‘haha‘
将倒数第二个元素修改为‘haha‘
del names[2] #删除第3个元素
del names #将列表nanmes整个删除,这样print(names)会报没有定义变形names
或者
names.pop() ##删除最后一个元素
names.pop(2) ###删除第3个元素
names = [‘cui‘,‘wang‘,‘luo‘,‘zhang‘,‘xu‘] age = [1,2,3,5] names.extend(age)
输出:
[‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘, 1, 2, 3, 5]
1的例子已经包含了,names.count(‘cui‘) #统计列表names里面有几个‘cui’
1 >>> names 2 [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘, 1, 2] 3 >>> names[-1] = ‘2‘ 4 >>> names[-2] = ‘1‘ 5 >>> names 6 [‘cui‘, ‘wang‘, ‘luo‘, ‘zhang‘, ‘xu‘, ‘1‘, ‘2‘] 7 >>> names.sort() 8 >>> names 9 [‘1‘, ‘2‘, ‘cui‘, ‘luo‘, ‘wang‘, ‘xu‘, ‘zhang‘] 10 >>> names.reverse() 11 >>> names 12 [‘zhang‘, ‘xu‘, ‘wang‘, ‘luo‘, ‘cui‘, ‘2‘, ‘1‘] 13 >>>
注意:排序前必须同一类型,顺序按照ASCII的顺序
1 [‘zhang‘, ‘xu‘, ‘wang‘, ‘luo‘, ‘cui‘, ‘2‘, ‘1‘] 2 >>> names.index(‘wang‘) 3 2 4 >>>
>>> names [‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘] >>> names.clear() >>> names [] >>>
>>> names_copy [‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘, ‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘, ‘cui‘, ‘hu‘, ‘zhang‘, ‘wang‘, ‘luo‘] >>> set(names_copy) {‘hu‘, ‘luo‘, ‘cui‘, ‘wang‘, ‘zhang‘} >>>
如果 len(names) = len(set(names)),说明列表不包含重复元素,len(list),会显示列表的长度,也就是有多少个元素
names = [‘cuiqing‘,‘luoshuchan‘,‘wanglingpeng‘,‘xuping‘,‘xuping‘,‘hujiaqi‘,1,2,1,2,1] if len(names) != len(set(names)): names_tmp = [] for n in range(len(names)): if names[n] not in names_tmp: names_tmp.append(names[n]) else: print(‘重复元素:‘,names[n],‘索引位置为:‘,n) print(‘重复元素:‘,names[n],‘索引位置为:‘,names.index(names[n])) else: print(names_tmp) else: print(‘列表不包含重复元素‘) 输出为: 重复元素: xuping 索引位置为: 4 重复元素: xuping 索引位置为: 3 重复元素: 1 索引位置为: 8 重复元素: 1 索引位置为: 6 重复元素: 2 索引位置为: 9 重复元素: 2 索引位置为: 7 重复元素: 1 索引位置为: 10 重复元素: 1 索引位置为: 6 [‘cuiqing‘, ‘luoshuchan‘, ‘wanglingpeng‘, ‘xuping‘, ‘hujiaqi‘, 1, 2]
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表。
它只有2个方法,一个是count,一个是index。
>>> age = (1,3,5,7,7) >>> age (1, 3, 5, 7, 7) >>> age.count(7) 2 >>> age.index(7) 3
标签:ide 内存地址 eve ever 文章 python学习 复制 ble 编码
原文地址:http://www.cnblogs.com/cq90/p/6765202.html
