标签:极限 ant ted 冒泡排序 指针 最大值 ram i+1 停止
快速排序是一种排序算法,对包含 n 个数的输入数组,最坏情况运行时间为O(n2)。虽然这个最坏情况运行时间比较差,但快速排序通常是用于排序的最佳的实用选择,
这是因为其平均性能相当好:期望的运行时间为O(nlgn),且O(nlgn)记号中隐含的常数因子很小。另外,它还能够进行就地排序,在虚存环境中也能很好的工作。
数组 A[p……r]被划分为两个(可能空)子数组 A[p……q-1] 和 A[q+1……r] ,使得 A[p……q-1] 中的每个元素都小于等于 A(q) , 而且,小于等于 A[q+1……r] 中的元素。小标q也在这个划分过程中进行计算。
通过递归调用快速排序,对于数组 A[p……q-1] 和 A[q+1……r] 排序。
因为两个子数组是就地排序的,将它们的合并不需要操作:整个数组 A[p……r] 已排序。
下面的过程实现快速排序(伪代码):
QUICK SORT(A,p,r)
1 if p<r 2 then q<-PARTITION(A,p,r) 3 QUICKSORT(A,p,q-1) 4 QUICKSORT(A,q+1,r)
为排序一个完整的数组A,最初的调用是QUICKSORT(A,1,length[A])。
快速排序算法的关键是PARTITION过程,它对子数组 A[p……r]进行就地重排(伪代码):
PARTITION(A,p,r)
1 x <- A[r] 2 i <- p-1 3 for j <- p to r-1 4 do if A[j]<=x 5 then i <- i+1 6 exchange A[i] <-> A[j] 7 exchange A[i + 1] <-> A[j] 8 return i+1
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
|
数据
|
6
|
2
|
7
|
3
|
8
|
9
|
|
下标
|
0
|
1
|
2
|
3 |
4
|
5
|
|
数据
|
3
|
2
|
7
|
6
|
8
|
9
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
|
数据
|
3
|
2
|
6
|
7
|
8
|
9
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
|
数据
|
3
|
2
|
6
|
7
|
8
|
9
|
注意:第一遍快速排序不会直接得到最终结果,只会把比k大和比k小的数分到k的两边。为了得到最后结果,需要再次对下标2两边的数组分别执行此步骤,然后再分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果。
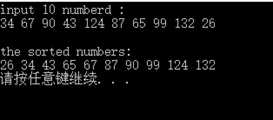
1 #include<stdio.h> 2 3 4 void Quick_Sort(int *a, int left, int right) //方法 5 { 6 if(left >= right)/*如果左边索引大于或者等于右边的索引就代表已经整理完成一个组了*/ 7 return ; 8 int i = left; 9 int j = right; 10 int key = a[left]; 11 while( i < j) /*控制在当组内寻找一遍*/ 12 { 13 while(i < j && key <= a[j]) 14 /*而寻找结束的条件就是,1,找到一个大于key的数(大于或小于取决于你想升 15 序还是降序,这里是升序)2,没有符合条件1的,并且i与j的大小没有反转*/ 16 { 17 j--; 18 } 19 a[i] = a[j]; 20 while(i < j && key >= a[i]) 21 /*这是i在当组内向前寻找,同上,不过注意与key的大小关系停止循环和上面相反, 22 因为排序思想是把数往两边扔,所以左右两边的数大小与key的关系相反*/ 23 { 24 i++; 25 } 26 a[j] = a[i]; 27 } 28 a[i] = key;/*当在当组内找完一遍以后就把中间数key回归*/ 29 Quick_Sort(a, left, i - 1);/*最后用同样的方式对分出来的左边的小组进行同上的做法*/ 30 Quick_Sort(a, i +1, right); /*用同样的方式对分出来的右边的小组进行同上的做法*/ 31 } 32 int main() 33 { 34 int a[10]; 35 int i,j,t; 36 printf("input 10 numbers :\n");//输入 37 for(i = 0;i < 10; i++) //数组 38 scanf("%d",&a[i]); //a[0]~a[9] 39 printf("\n"); 40 void Quick_Sort(int *a, int left, int right); 41 Quick_Sort(a, 0, 9); 42 printf("the sorted numbers :\n"); 43 for(i = 0;i < 10; i++) //输出 44 printf("%d ",a[i]); //数组 45 printf("\n"); 46 return 0; 47 }
输入/输出:
快速排序由 C. A. R. Hoare(东尼霍尔,Charles Antony Richard Hoare)在1960年提出,之后又有许多人做了进一步的优化。如果你对快速排序感兴趣可以去看看东尼霍尔1962年在Computer Journal发表的论文“Quicksort”以及《算法导论》的第七章。快速排序算法仅仅是东尼霍尔在计算机领域才能的第一次显露,后来他受到了老板的赏识和重用,公司希望他为新机器设计一个新的高级语言。你要知道当时还没有PASCAL或者C语言这些高级的东东。后来东尼霍尔参加了由Edsger Wybe Dijkstra(1972年图灵奖得主,这个大神我们后面还会遇到的到时候再细聊)举办的“ALGOL 60”培训班,他觉得自己与其没有把握去设计一个新的语言,还不如对现有的“ALGOL 60”进行改进,使之能在公司的新机器上使用。于是他便设计了“ALGOL 60”的一个子集版本。这个版本在执行效率和可靠性上都在当时“ALGOL 60”的各种版本中首屈一指,因此东尼霍尔受到了国际学术界的重视。后来他在“ALGOL X”的设计中还发明了大家熟知的“case”语句,后来也被各种高级语言广泛采用,比如PASCAL、C、Java语言等等。当然,东尼霍尔在计算机领域的贡献还有很多很多,他在1980年获得了图灵奖。
三平均分区法
关于这一改进的最简单的描述大概是这样的:与一般的快速排序方法不同,它并不是选择待排数组的第一个数作为中轴,而是选用待排数组最左边、最右边和最中间的三个元素的中间值作为中轴。这一改进对于原来的快速排序算法来说,主要有两点优势:
(1) 首先,它使得最坏情况发生的几率减小了。
(2) 其次,未改进的快速排序算法为了防止比较时数组越界,在最后要设置一个哨点。根据分区大小调整算法
这一方面的改进是针对快速排序算法的弱点进行的。快速排序对于小规模的数据集性能不是很好。可能有人认为可以忽略这个缺点不计,因为大多数排序都只要考虑大规模的适应性就行了。但是快速排序算法使用了分治技术,最终来说大的数据集都要分为小的数据集来进行处理。由此可以得到的改进就是,当数据集较小时,不必继续递归调用快速排序算法,而改为调用其他的对于小规模数据集处理能力较强的排序算法来完成。Introsort就是这样的一种算法,它开始采用快速排序算法进行排序,当递归达到一定深度时就改为堆排序来处理。这样就克服了快速排序在小规模数据集处理中复杂的中轴选择,也确保了堆排序在最坏情况下O(n log n)的复杂度。
另一种优化改进是当分区的规模达到一定小时,便停止快速排序算法。也即快速排序算法的最终产物是一个“几乎”排序完成的有序数列。数列中有部分元素并没有排到最终的有序序列的位置上,但是这种元素并不多。可以对这种“几乎”完成排序的数列使用插入排序算法进行排序以最终完成整个排序过程。因为插入排序对于这种“几乎”完成的排序数列有着接近线性的复杂度。这一改进被证明比持续使用快速排序算法要有效的多。
另一种快速排序的改进策略是在递归排序子分区的时候,总是选择优先排序那个最小的分区。这个选择能够更加有效的利用存储空间从而从整体上加速算法的执行。不同的分区方案考虑
对于快速排序算法来说,实际上大量的时间都消耗在了分区上面,因此一个好的分区实现是非常重要的。尤其是当要分区的所有的元素值都相等时,一般的快速排序算法就陷入了最坏的一种情况,也即反复的交换相同的元素并返回最差的中轴值。无论是任何数据集,只要它们中包含了很多相同的元素的话,这都是一个严重的问题,因为许多“底层”的分区都会变得完全一样。
对于这种情况的一种改进办法就是将分区分为三块而不是原来的两块:一块是小于中轴值的所有元素,一块是等于中轴值的所有元素,另一块是大于中轴值的所有元素。另一种简单的改进方法是,当分区完成后,如果发现最左和最右两个元素值相等的话就避免递归调用而采用其他的排序算法来完成。并行的快速排序
由于快速排序算法是采用分治技术来进行实现的,这就使得它很容易能够在多台处理机上并行处理。
在大多数情况下,创建一个线程所需要的时间要远远大于两个元素比较和交换的时间,因此,快速排序的并行算法不可能为每个分区都创建一个新的线程。一般来说,会在实现代码中设定一个阀值,如果分区的元素数目多于该阀值的话,就创建一个新的线程来处理这个分区的排序,否则的话就进行递归调用来排序。
对于这一并行快速排序算法也有其改进。该算法的主要问题在于,分区的这一步骤总是要在子序列并行处理之前完成,这就限制了整个算法的并行程度。解决方法就是将分区这一步骤也并行处理。改进后的并行快速排序算法使用2n个指针来并行处理分区这一步骤,从而增加算法的并行程度。
随机化快排
快速排序的最坏情况基于每次划分对主元的选择。基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。一位前辈做出了一个精辟的总结:“随机化快速排序可以满足一个人一辈子的人品需求。”随机化快速排序的唯一缺点在于,一旦输入数据中有很多的相同数据,随机化的效果将直接减弱。对于极限情况,即对于n个相同的数排序,随机化快速排序的时间复杂度将毫无疑问的降低到O(n^2)。解决方法是用一种方法进行扫描,使没有交换的情况下主元保留在原位置。平衡快排
每次尽可能地选择一个能够代表中值的元素作为关键数据,然后遵循普通快排的原则进行比较、替换和递归。通常来说,选择这个数据的方法是取开头、结尾、中间3个数据,通过比较选出其中的中值。取这3个值的好处是在实际问题中,出现近似顺序数据或逆序数据的概率较大,此时中间数据必然成为中值,而也是事实上的近似中值。万一遇到正好中间大两边小(或反之)的数据,取的值都接近最值,那么由于至少能将两部分分开,实际效率也会有2倍左右的增加,而且利于将数据略微打乱,破坏退化的结构。外部快排
与普通快排不同的是,关键数据是一段buffer,首先将之前和之后的M/2个元素读入buffer并对该buffer中的这些元素进行排序,然后从被排序数组的开头(或者结尾)读入下一个元素,假如这个元素小于buffer中最小的元素,把它写到最开头的空位上;假如这个元素大于buffer中最大的元素,则写到最后的空位上;否则把buffer中最大或者最小的元素写入数组,并把这个元素放在buffer里。保持最大值低于这些关键数据,最小值高于这些关键数据,从而避免对已经有序的中间的数据进行重排。完成后,数组的中间空位必然空出,把这个buffer写入数组中间空位。然后递归地对外部更小的部分,循环地对其他部分进行排序。三路基数快排
(Three-way Radix Quicksort,也称作Multikey Quicksort、Multi-key Quicksort):结合了基数排序(radix sort,如一般的字符串比较排序就是基数排序)和快排的特点,是字符串排序中比较高效的算法。该算法被排序数组的元素具有一个特点,即multikey,如一个字符串,每个字母可以看作是一个key。算法每次在被排序数组中任意选择一个元素作为关键数据,首先仅考虑这个元素的第一个key(字母),然后把其他元素通过key的比较分成小于、等于、大于关键数据的三个部分。然后递归地基于这一个key位置对“小于”和“大于”部分进行排序,基于下一个key对“等于”部分进行排序。
标签:极限 ant ted 冒泡排序 指针 最大值 ram i+1 停止
原文地址:http://www.cnblogs.com/denglw/p/6783796.html