标签:电话 int and headers rip als range 二手房 员工
第一步先分析网站结构http://esf.zs.fang.com/
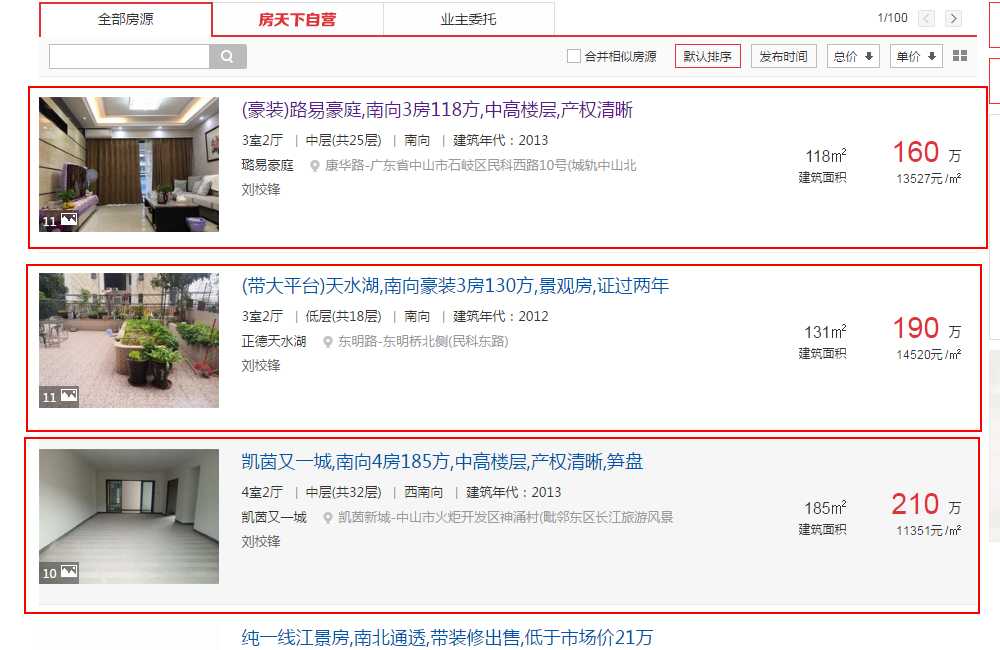
寻找我们需要获取的信息,点击进去看看,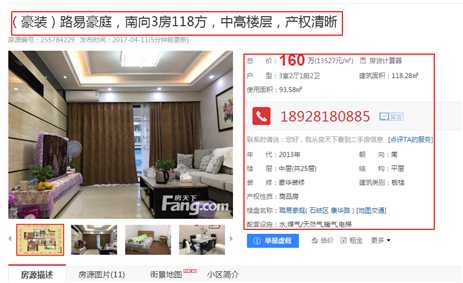
链接里面信息更加详细,这些就是我们要获取的。
1.我们可以先获取http://esf.zs.fang.com/链接下的所有详细链接http://esf.zs.fang.com/chushou/3_255784229.htm
2.然后可以在详细链接下分析获取我们所需要的数据
3.获取数据之后存取到数据库mongodb
打开管理员工具F12观察http://esf.zs.fang.com/的详细链接情况
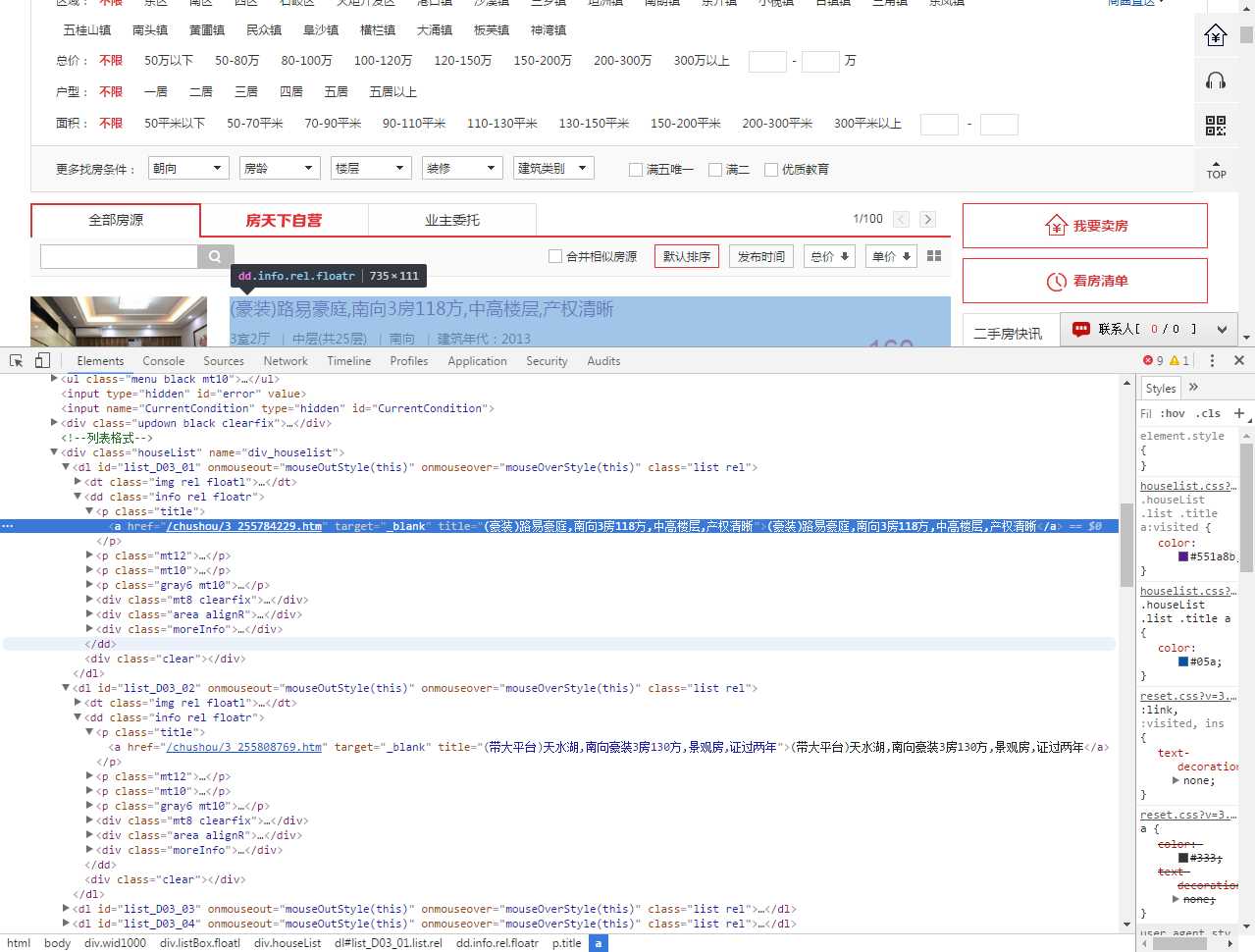
发现详细的链接在dl标签里面的
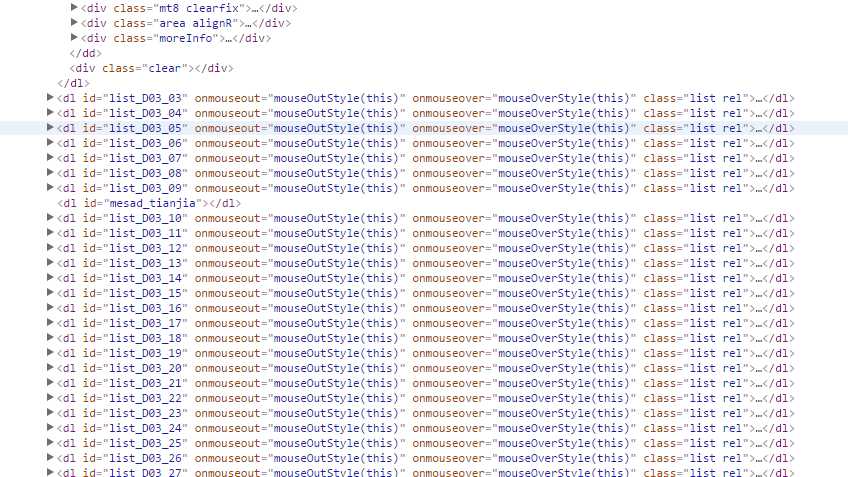
都是整齐的,这样我们就可以用BeautifulSoup方法获取这个详细链接,但是这个链接并不是完整的
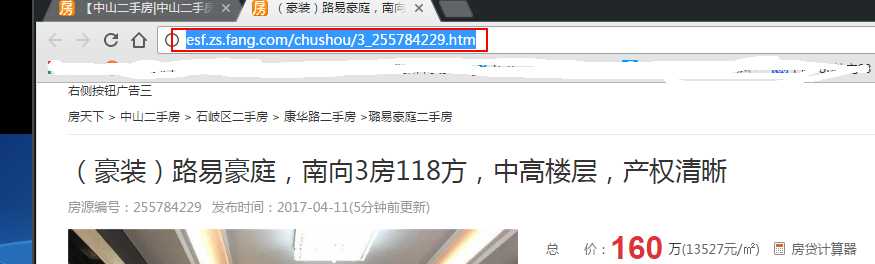
观察详细页的链接发现它们事有关联的http://esf.zs.fang.com + chushou/3_255784229.htm
然后我们就可以开始写了
我们先要获取全部详情页
 http://esf.zs.fang.com/house/i33/
http://esf.zs.fang.com/house/i33/
 http://esf.zs.fang.com/house/i34/
http://esf.zs.fang.com/house/i34/
发现页数是跟url有关联的,我们就可以弄一个生成器生成这些原始链接
def get_url(user_in_city,user_in_nub): #获取user_in_city,user_in_nub的链接
url_home = (‘http://esf.‘+ user_in_city + ‘.fang.com/house/i3{}/‘)
for url_next in range(1, int(user_in_nub)):
yield url_home.format(url_next)
user_in_city,user_in_nub分别是http://esf.zs.fang.com/house/i34/的zs和 i34,city和nub当参数传给函数,我们后面可以通过调用来改变生成的网页
调用一下
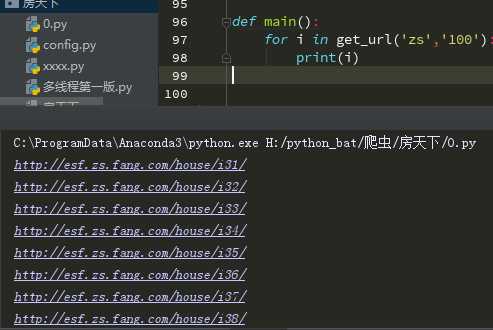
因为这是一个生成器我们要迭代生成
获取了url然后我们就要分析获取url里面的详细url:
用开发者工具观察结构

链接实在a标签里面的href 这样我们可以def一个方法获取然后生成一个完整的详细链接。
def open_url(url,user_in_city):
try:
res = requests.get(url, headers=headers1)
if res.status_code == 200:
soup = BeautifulSoup(res.text, ‘html5lib‘)
url_start = ‘http://esf.‘ + user_in_city + ‘.fang.com‘
for title in soup.select(‘.title‘): # 网址链接列表
url_end = title.select(‘a‘)[0][‘href‘]
yield url_start + url_end
except RequestException:
return print(‘检查open_url‘)
先要import requests,from bs4 import BeautifulSoup来获取及分析
加入status_code异常处理,如果status_code不等于200返回‘检查open_url‘
不行了直接上源码吧老怼
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author;Tsukasa
import pymongo
Mongo_Url=‘localhost‘
Mongo_DB=‘fangtianxia‘
Mongo_TABLE=‘fangtianxia_fs‘
import json
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import pandas as pd
import time
from fake_useragent import UserAgent
from multiprocessing import Pool
ua = UserAgent()
headers1 = {‘User-Agent‘:‘ua.ramdom‘}
client = pymongo.MongoClient(Mongo_Url)
db = client[Mongo_DB]
def get_url(user_in_city,user_in_nub): #获取user_in_city,user_in_nub的链接
url_home = (‘http://esf.‘+ user_in_city + ‘.fang.com/house/i3{}/‘)
for url_next in range(1, int(user_in_nub)):
yield url_home.format(url_next)
def open_url(url,user_in_city):
try:
res = requests.get(url, headers=headers1)
if res.status_code == 200:
soup = BeautifulSoup(res.text, ‘html5lib‘)
url_start = ‘http://esf.‘ + user_in_city + ‘.fang.com‘
for title in soup.select(‘.title‘): # 网址链接列表
url_end = title.select(‘a‘)[0][‘href‘]
yield url_start + url_end
except RequestException:
return print(‘检查open_url‘)
def one_page(house_url):
try:
res = requests.get(house_url, headers=headers1)
if res.status_code ==200:
soup = BeautifulSoup(res.text, ‘html5lib‘)
info = {}
info[‘网页‘] = house_url
info[‘标题‘] = soup.select(‘h1‘)[0].text.strip() # 获取标题
info[‘总价‘] = soup.select(‘.red20b‘)[0].text + ‘万‘ # 总价
info[‘联系电话‘] = soup.select(‘#mobilecode‘)[0].text # 电话
#now_time = time.strftime(‘%Y-%m-%d\t%H:%M‘,time.localtime(time.time()))
#info[‘Obj更新时间‘] = now_time
for sl in soup.select(‘span‘): # 获取发布时间
if ‘发布时间‘ in sl.text.lstrip(‘<span>‘):
key, value = (sl.text.strip().rstrip(‘(‘).split(‘:‘))
info[key] = value + ‘*‘ + soup.select(‘#Time‘)[0].text
for dd in soup.select(‘dd‘): # 获取详细内容
if ‘:‘ in dd.text.strip():
key, value = (dd.text.strip().split(‘:‘))
info[key] = value
print(info)
return info
except RequestException:
return print(‘检查one_page‘)
def writer_to_text(text):
with open(‘房天下.text‘,‘a‘,encoding=‘utf-8‘)as f:
f.write(json.dumps(text,ensure_ascii=False)+‘\n‘)
f.close()
def pandas_to_xlsx(pd_list):
pd_look = pd.DataFrame(pd_list)
pd_look.to_excel(‘房天下.xlsx‘,sheet_name=‘房天下‘)
def pandas_to_csv(pd_list):
pd_look = pd.DataFrame(pd_list)
pd_look.to_csv(‘房天下.csv‘,mode=‘a+‘,header=False)
def save_to_MongoDB(one_page): #添加到MongoDB
if db[Mongo_TABLE].insert(one_page):
print(‘储存到MongoDB OK!‘,one_page)
return True
return False
def update_to_MongoDB(one_page): #update到MongoDB
if db[Mongo_TABLE].update({‘网页‘:one_page[‘网页‘]},{‘$set‘:one_page},True):
print(‘储存MongoDB 成功!‘)
return True
return False
def main(url):
data=[]
save = one_page(url)
data.append(save)
pandas_to_csv(data)
update_to_MongoDB(save)
#writer_to_text(one_page(url))
if __name__ == ‘__main__‘:
user_in_city = input(‘输入你所需要城市的字母简写:\n如:中山 zs , 广州 gz\n!!!不要乱输入,不然运行不了‘)
user_in_nub = 1 + int(input(‘输入爬取页数:‘))
pool = Pool()
for url in get_url(user_in_city, user_in_nub):
pool.map(main,[url_open for url_open in open_url(url, user_in_city)])
‘‘‘
屋里臭居居呼呼好大声(???)
‘‘‘
标签:电话 int and headers rip als range 二手房 员工
原文地址:http://www.cnblogs.com/Tsukasa/p/6790210.html