标签:print png 服务 class img main exce src 编码
作为一个咸鱼大学打了3年游戏才幡然醒悟,现在开始学点东西,这里记录下自己的所学。
urllib库之前有些了解就不写了,从requests 库开始吧(ˉ▽ ̄~) 。
首先要说的是一定要用好官方文档:http://docs.python-requests.org/en/master/
先来看个列子吧:
下面介绍requests库的几种基本用法:
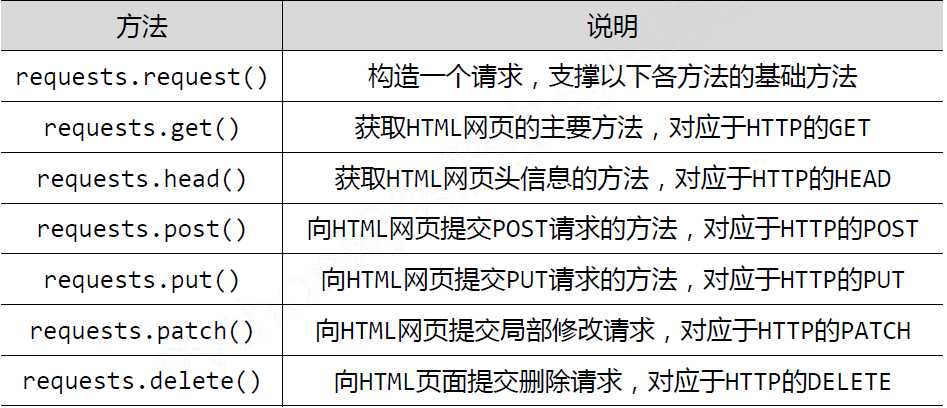
具体代码略过参考官方文档练习就好,这里面get是最常用的方法。
response对象包含了服务器返回的所有信息,也包含了requests的请求信息。

属性

给一个标准的爬取网页的代码:
1 import requests 2 3 def geturl(url): 4 try: 5 r=requests.get(url,timeout=100) 6 r.raise_for_status() 7 r.encoding=r.apparent_encoding #替换编码有些网页猜测编码会报错 8 return r.text 9 except: 10 return "异常" 11 12 13 if __name__=="__main__": 14 url="http://jwweb.scujcc.cn/" 15 print(geturl(url))
代码中给的是我们学校的教务网网址如果不用r.apparent_encoding替换r.enconding会报编码错误大家可以试一下
第一次写这个也没有什么思路大佬轻喷,内容以后有新的理解也会加进来慢慢完善也希望大家给点建议。
标签:print png 服务 class img main exce src 编码
原文地址:http://www.cnblogs.com/franklv/p/6791972.html