标签:指针 目的 特定 分布 继承 loading represent private 光栅化
在我们提交安装包到App Store的时候,如果安装包过大,有可能会收到类似如下内容的一封邮件:
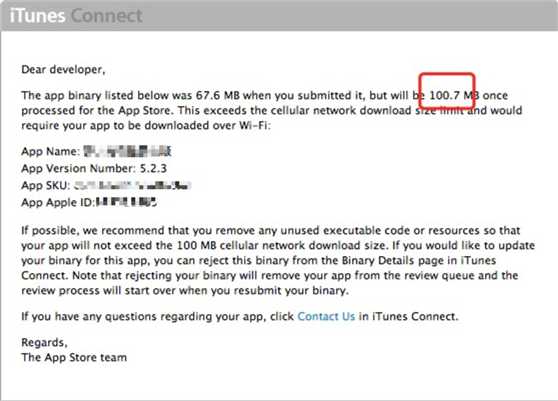
收到这封邮件的时候,意味着安装包在App Store上下载的时候,有的设备下载的安装包大小会超过100M。对于超过100M的安装包,只能在WIFI环境下下载,不能直接通过4G网络进行下载。
在这里,我们提交App Store的安装包大小为67.6MB,在App Store上显示的下载大小和实际下载下来的大小,我们通过下表做一个对比:
|
iPhone型号
|
系统
|
AppStore 显示大小
|
下载到设备大小
|
|---|---|---|---|
| iPhone6 | 10.2.1 | 91.5MB | 88.9MB |
| iPhone6 | 10.1.1 | 91.5MB | 88.9MB |
| iPhone6 | 9.3.5 | 91.5MB | 84.8MB |
| iPhone 5 | 9.2 | 91.5MB | 84.8MB |
| iPhone6 plus | 10.0.2 | 95.7MB | 93.2MB |
| iPhone7 plus | 10.3.0 | 95.7MB | 93.2MB |
| iPhone5C | 9.2 | 83.9MB | 76MB |
| iPhone5S | 7.1.1 | 147MB | 144MB |
| iPhone5C | 7.1.2 | 147MB | 未知 |
| iPhone5C 越狱 | 8.1.1 | 83.9MB | 144MB |
从上表可以看到:
【App Thinning】:对于iOS应用来说,应用分割仅支持最新版本的iTunes,以及运行iOS 9.0或者更高系统的设备,否则的话,App Store将会为用户分发统一的安装包。iOS 9 在发布时隐含一个 Bug , App Thinning ( App 瘦身)无法正确运作。随着 iOS 9.0.2 的发布,此 Bug 已被修复, App 瘦身终于可以运作如常。从 App Store 下载 App 时请谨记这点。App Thinning 会自动检测用户的设备类型(即型号名称)并且只下载当前设备所适用的内容。换句话说,如果使用的是 iPad Mini 1(1x分辨率且非 retina 显示屏)那么只会下载 1x分辨率所使用的文件。更强大和更高分辨率的 ipad(如iPad Mini 3或 4)所使用的资源将不会被下载。因为用户仅需下载自己当前使用的特定设备所需的内容,这不仅加快了下载速度,还节约了设备的存储空间。
在邮件内容中,苹果建议删除一些无用的执行代码或资源文件。下面我们分别从这两方面来分析安装包瘦身的一些方法和工具。
资源文件包括图片、声音、配置文件、文本文件(例如rtf文件)、xib(在安装包中后缀名为nib)、storyboard等。对于声音、配置文件、文本文件这三类资源文件,一般在安装包中数量不多,可自行在工程中根据实际情况,进行删除或保留。声音文件过大的话,可以考虑用如下命令做压缩:
//tritone.caf为声音文件 afconvert -f AIFC -d ima4 tritone.caf
xib和storyboard结合后面的可执行文件一起分析。这里主要说一下对图片资源的处理方式。
对图片资源类文件,一般采取的方法是这几种:
首先,使用python脚本搜索工程中没有使用的图片资源,脚本代码示例如下:
#!/bin/sh PROJ=`find . -name ‘*.xib‘ -o -name ‘*.[mh]‘` for png in `find . -name ‘*.png‘` do name=`basename $png` if ! grep -qhs "$name" "$PROJ"; then echo "$png is not referenced" fi done
但上面的脚本具有如下缺点:不够智能,不够通用,速度太慢,结果不正确。
在这里推荐使用工具LSUnusedResources。它在脚本的基础上,做了两个改进:
接下来,打开工具LSUnusedResources,点击“Browse...”按钮,选择工程所在目录,点击"Search"按钮,即可开始搜索,如下图所示:
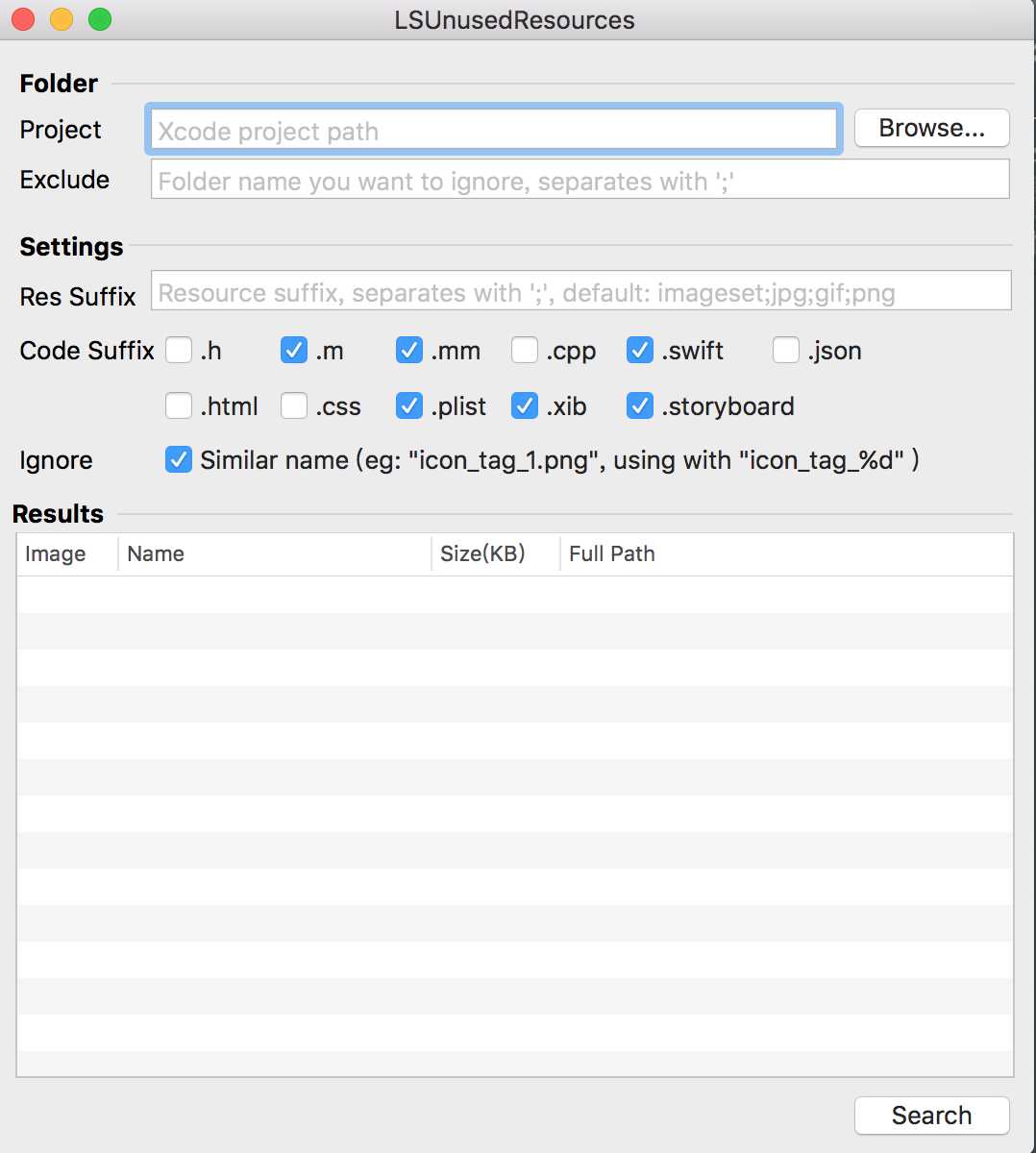
搜索结果出来之后,选中某行,点击“Delete”按钮即可直接删除资源。
压缩工具有很多,这里介绍两个好用的:
【建议】:对于较大尺寸的图片,可以和设计沟通,在不失真和影响效果的前提下,使用TinyPNG进行压缩;较小尺寸的图片,建议使用ImageOptiom。
我们都知道,图片资源的导入方式有如下几种:
1. Assets.xcassets。
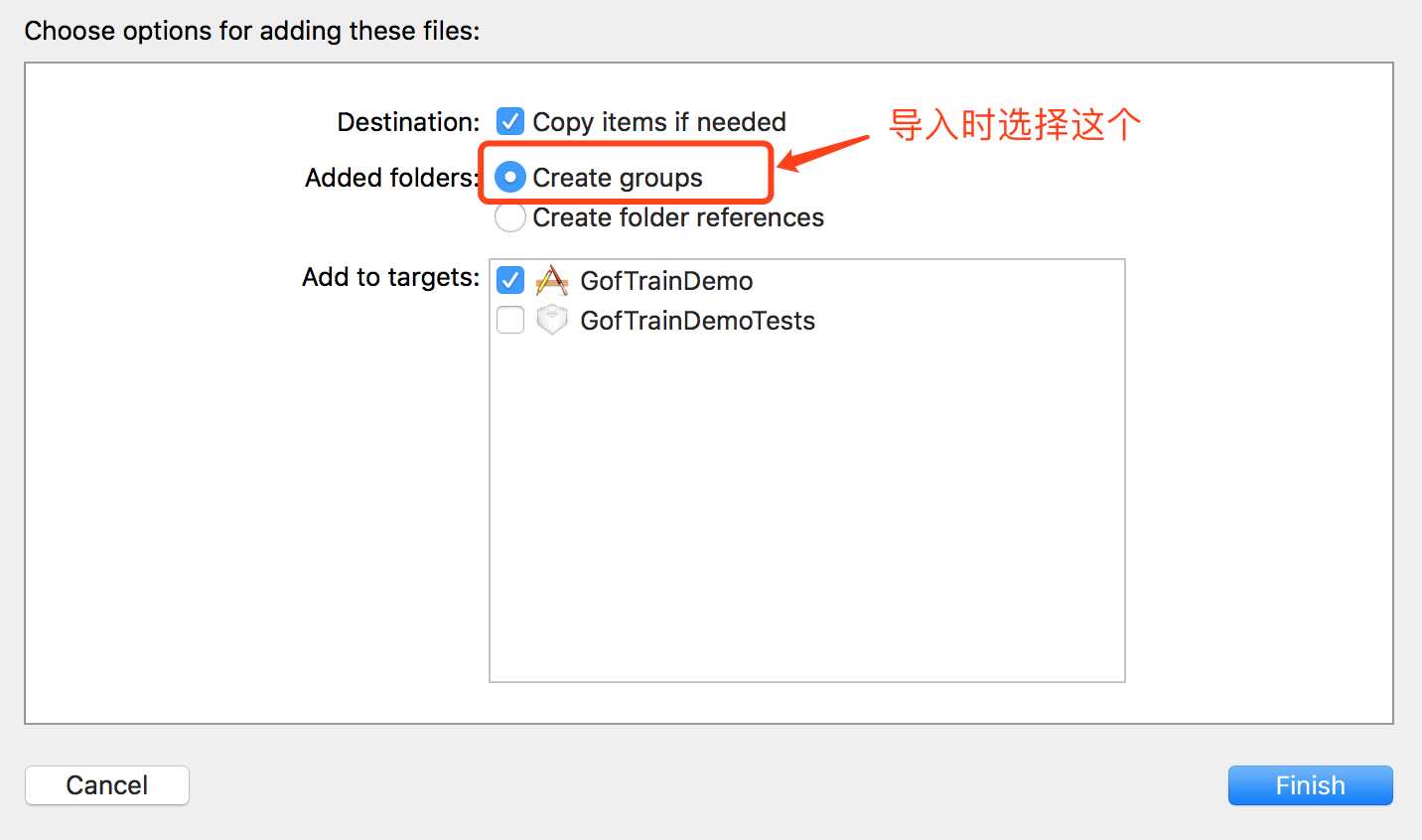
2. CreateGroup
3. CreateFolderRefences
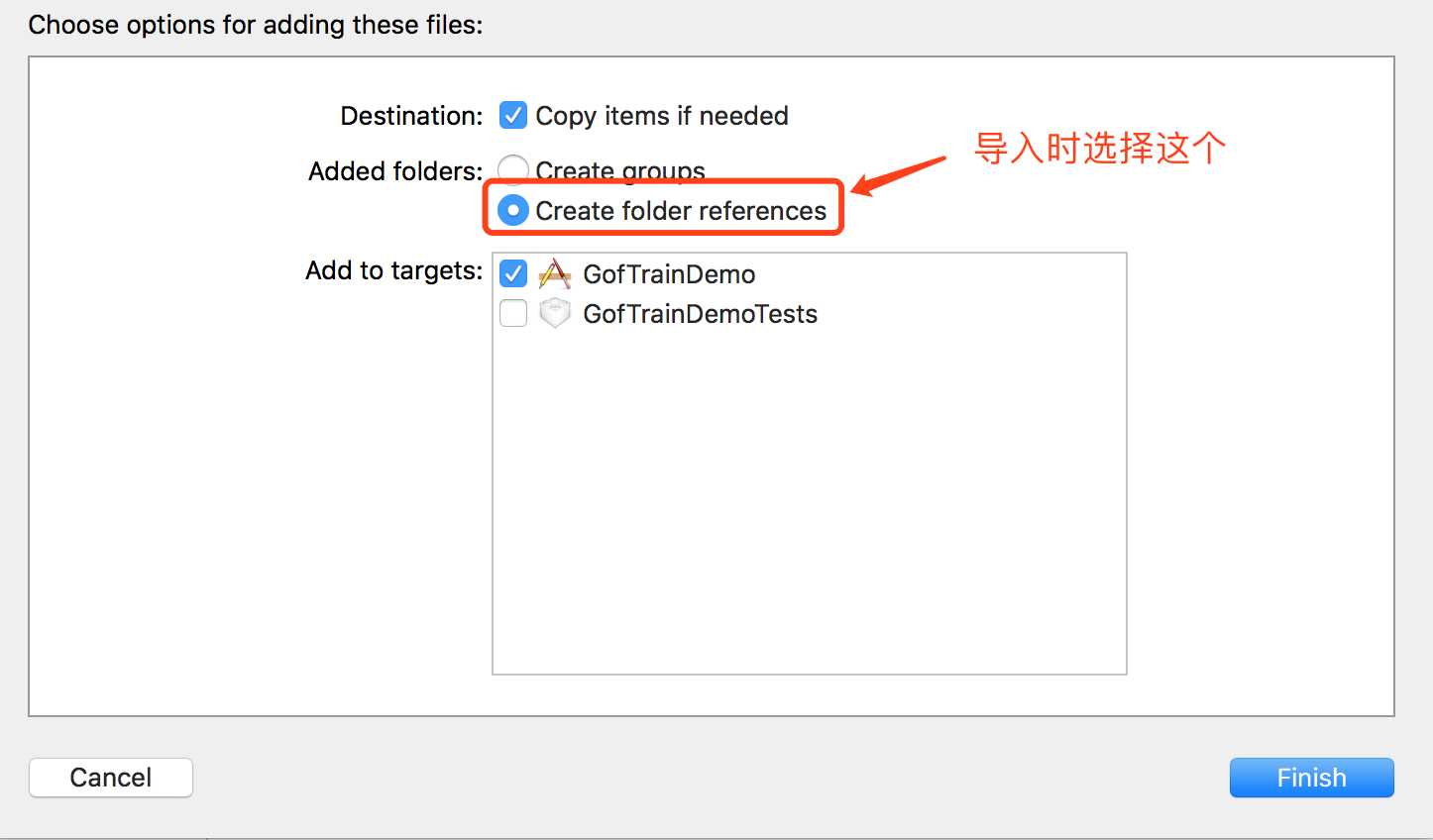
【说明】:蓝色文件夹只是将文件单纯的创建了引用,这些文件不会被编译,所以在使用的时候需要加入其路径。
4. PDFs矢量图(Xcode6+)
5. Bundle(包)
对于上面这几种不同的导入方式,会对打出的包的大小有影响么?
经过测试得知:CreateGroup、CreateFolderRefences两种方式打出来的包,图片都会直接放在.app文件中,所以打包前后,图片的大小不会改变。而加入到Assets.xcassets中的方法则不同,打包后,在.app中会生成Assets.car文件来存储Assets.xcassets中的图片,并且文件大小也大大降低。
| 测试 |
打包前Assets.xcassets文件夹 |
打包后的Assets.car文件夹 |
| 第一次 |
32.7MB |
16.3MB |
| 第二次 | 33.5MB | 26.1MB |
从表格数据可以看到,使用Assets.xcassets来管理图片也可以达到ipa瘦身的效果。
值得留意的是,在将图片资源移到Assets.xcassets管理的时候,一般情况下会自动生成与图片名称相同的,比如loading@2x.png和loading@3x.png会自动放置到一个同名的loading文件夹中。然而有一些不规则命名的图片,会出现一些奇怪的问题:
因此在移动的时候,一定要细致对比。
我们知道,iPhone设备目前主要有四种尺寸:3.5英寸、4英寸、4.7英寸、5.5英寸,对于这几个尺寸的设备,我们来看一下具体的设备型号和屏幕相关信息:
| 机型 | 屏幕宽高(point) | 渲染像素(pixel) | 物理像素(pixel) | 屏幕对角线长度(英寸) | 屏幕模式 |
| iPhone 2G, 3G, 3GS | 320 * 480 | 320 * 480 | 320 * 480 | 3.5(163PPI) | 1x |
| iPhone 4, 4s | 320 * 480 | 640 * 960 | 640 * 960 | 3.5 (326PPI) | 2x |
| iPhone 5, 5s | 320 * 568 | 640 * 1136 | 640 * 1136 | 4 (326PPI) | 2x |
| iPhone 6, 6s, 7 | 375 * 667 | 750 * 1334 | 750 * 1334 | 4.7 (326PPI) | 2x |
| iPhone 6 Plus, 6s Plus, 7 Plus | 414 * 736 | 1242 * 2208 | 1080 * 1920 | 5.5 (401PPI) | 3x |
对于上表中的几个概念,这里做一下说明:
在实际的开发中,所有控件的坐标以及控件大小都是以点为单位的,假如屏幕上需要展示一张 20 * 20 (单位:point)大小的图片,那么设计师应该怎么给图呢?这里就会用到屏幕模式的概念,如果屏幕是 2x,那么就需要提供 40 * 40 (单位: pixel)大小的图片,如果屏幕是 3x,那么就提供 60 * 60 大小的图片,且图片的命名需要遵守以下规范:
<ImageName><device_modifier>.<filename_extension><ImageName>@2x<device_modifier>.<filename_extension><ImageName>@3x<device_modifier>.<filename_extension>其中:
~ipad 或者 ~iphone, 当需要为 iPad 和 iPhone 分别指定一套图时需要加上此字段2x屏幕的设备会自动加载 xxx@2x.png 命名的图片资源,3x屏幕的设备会自动加载 xxx@3x.png 的图片。从友盟统计数据可以看到,现在基本没有 1x屏幕的设备了,所以可以不用提供这个分辨率的图片。
至于开发中,技术人员和设计人员关于设计和切图的工作流程和规范,可以参看知乎上的这篇文章介绍。
我们用 Xcode 构建一个程序的过程中,会把源文件 (.m 和 .h) 文件转换为一个可执行文件。这个可执行文件中包含的字节码会被 CPU (iOS 设备中的 ARM 处理器或 Mac 上的 Intel 处理器) 执行。对于这个可执行文件,我们可以用工具MachOView来查看。
Mach-O为Mach Object文件格式的缩写,是mac上可执行文件的格式,类似于windows上的PE格式 (Portable Executable )或 linux上的elf格式 (Executable and Linking Format)。Mach-O文件分为这几类:
对于这几种类型的Mach-O文件,我们可以使用MachOView进行查看。MachOView是一个开源的工具,源码在GitHub上:https://github.com/gdbinit/MachOView,感兴趣的可以研究一下。
下面我们用MachOView来打开一个静态链接库文件看看,了解Mach-O文件的结构:
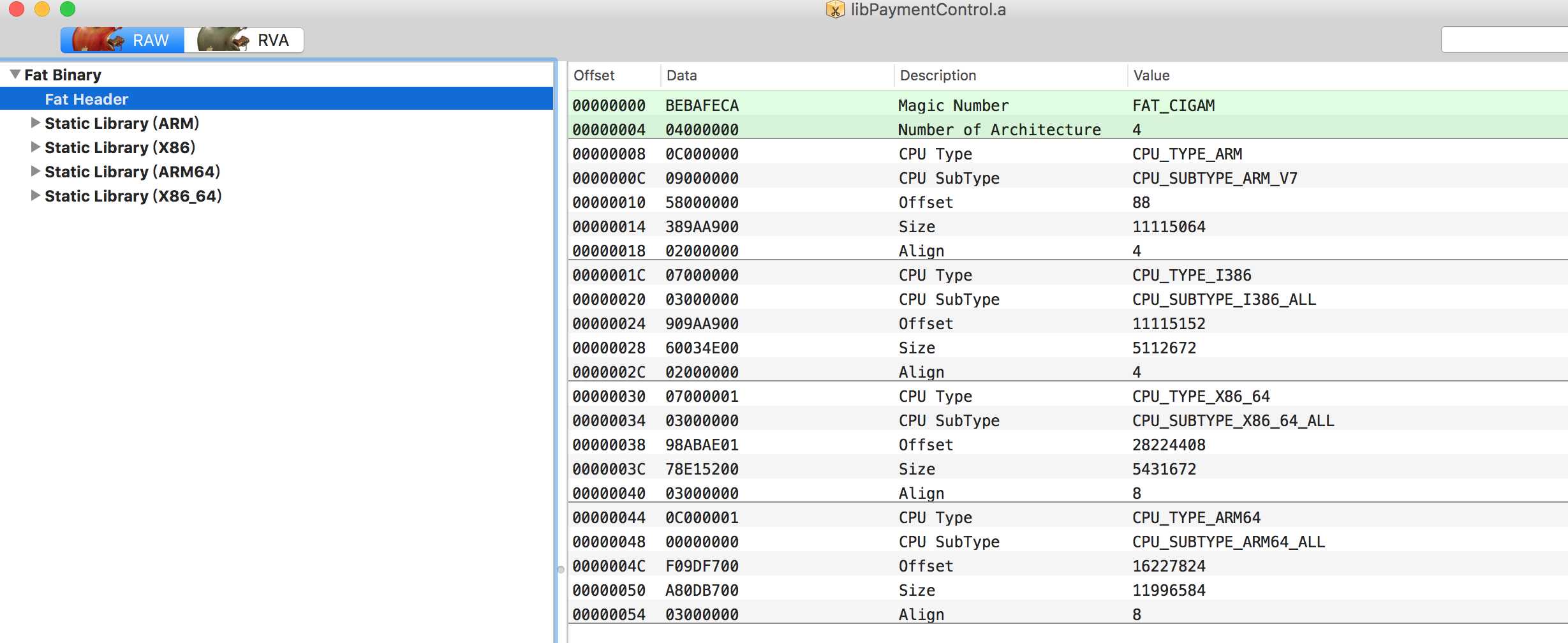
首先,我们来看一下“Fat Header”里面的内容:它是对各种架构文件的组装,可以看到每种类型的CPU架构信息,从上图可以看到支持的架构,图中显示的支持ARM_V7 、i386 、 X86_64、ARM_64。
接下来我们点开一个Static Library看看:
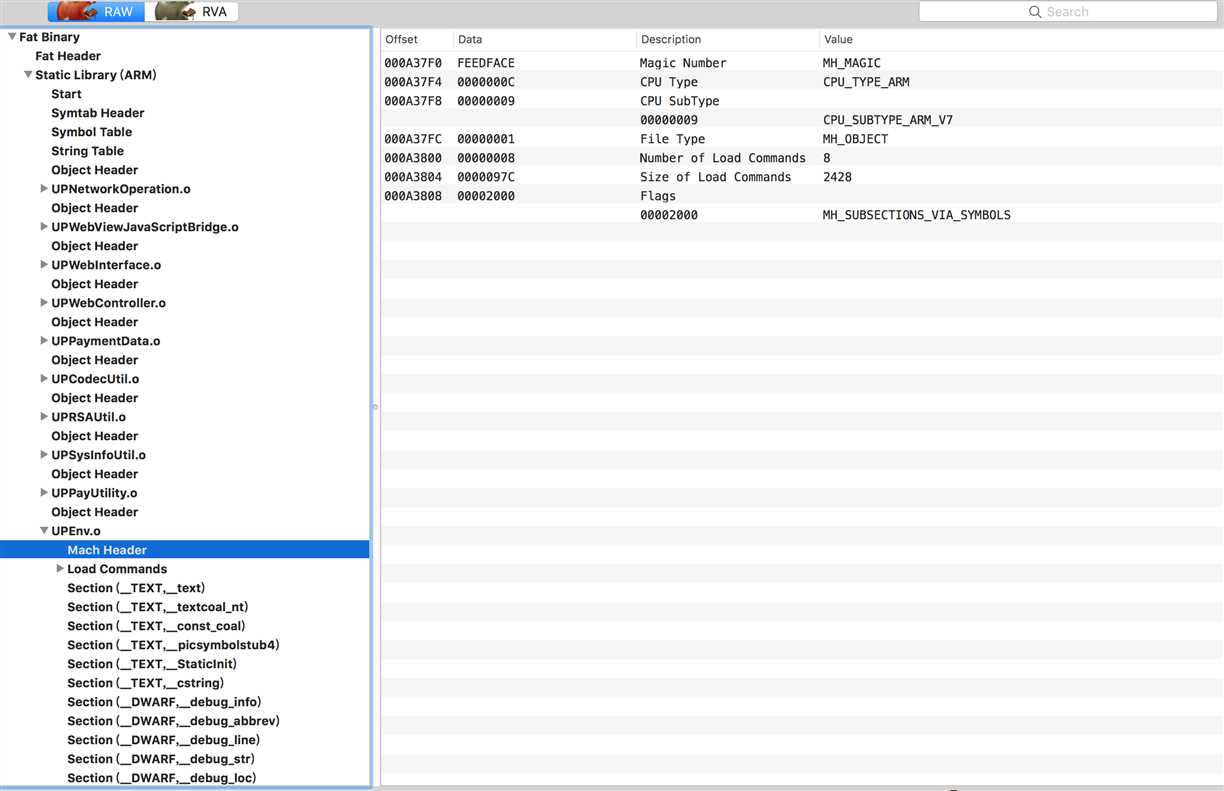
从上图可以看到,Static Library有很多.o文件,每个.o文件都对应一个类编译后的文件,展开查看“Mach Header”信息,可以看到每个类的CPU架构信息、Load Commands数量 、Load Commands Size 、File Type等信息。
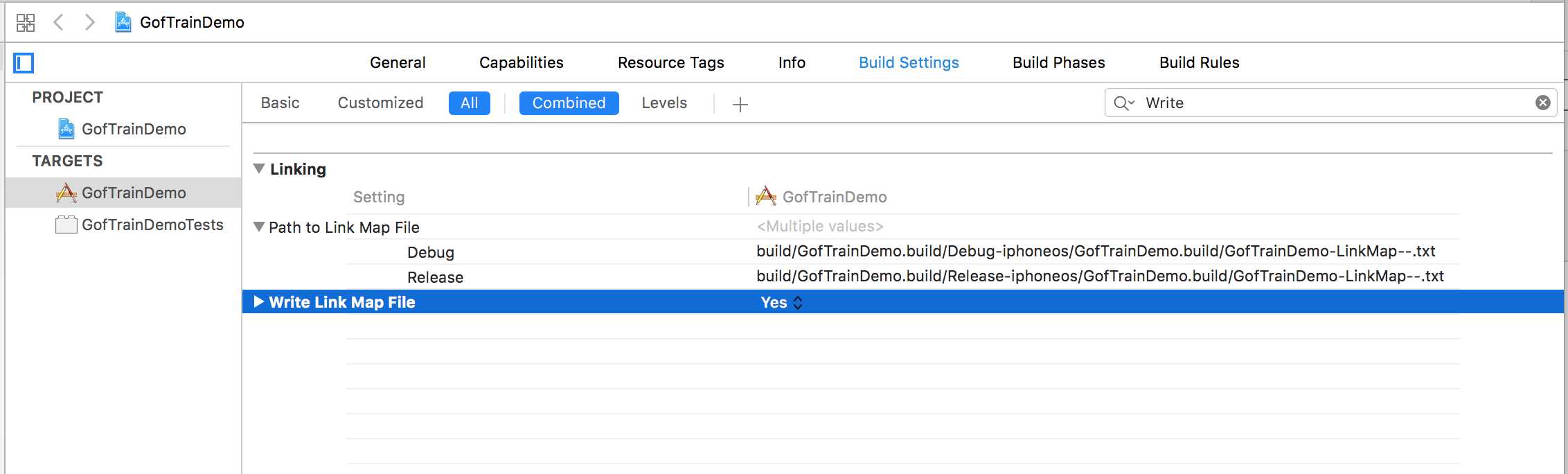
当然,我们也可以在Xcode中,开启编译选项Write Link Map File,编译之后来查看可执行文件的全貌。
LinkMap文件是Xcode产生可执行文件的同时生成的链接信息,用来描述可执行文件的构造成分,包括代码段(__TEXT)和数据段(__DATA)的分布情况。
在Xcode中,选择XCode -> Target -> Build Settings -> 搜map -> 把Write Link Map File选项设为YES,并指定好linkMap的存储位置,如下图所示:
编译后,到编译目录里找到该txt文件,文件名和路径就是上述的Path to Link Map File。这个LinkMap里展示了整个可执行文件的全貌,列出了编译后的每一个.o目标文件的信息(包括静态链接库.a里的),以及每一个目标文件的代码段,数据段存储详情。下面来简单分析一下这个文件的结构。
打开LinkMap文件,首先看到的就是编译后的每一个.o目标文件的信息,如下图所示:
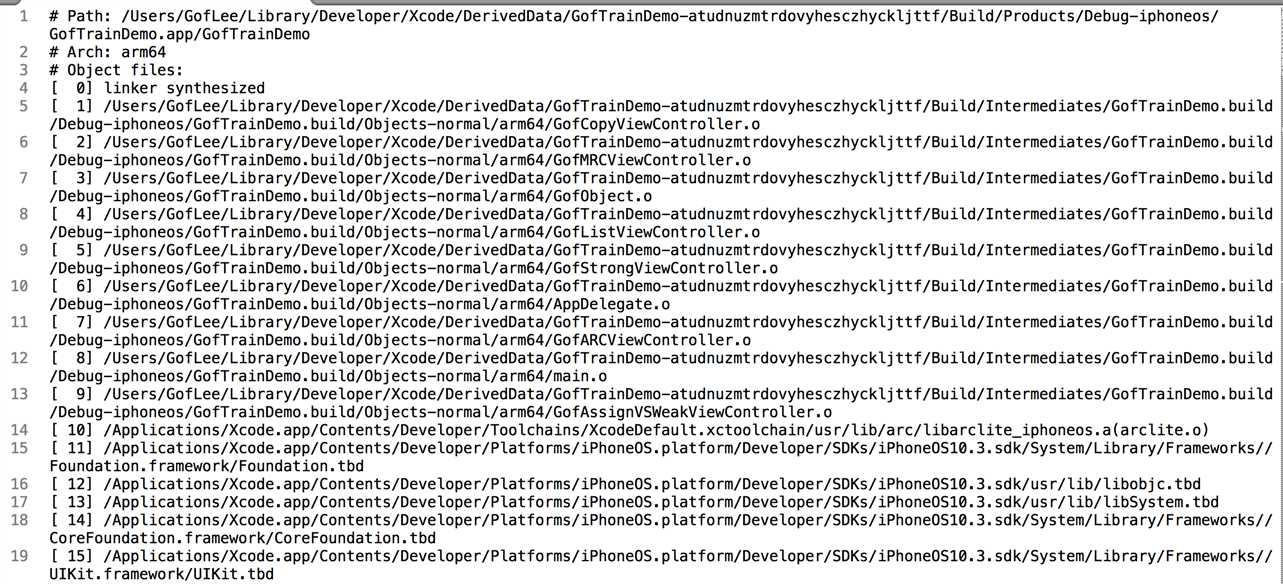
前面中括号里的是这个文件的编号,后面会用到。包括工程中用到的库和Framework,都会在这里列出来。
接着是一个段表,描述各个段在最后编译成的可执行文件中的偏移位置及大小,包括了代码段(__TEXT,保存程序代码段编译后的机器码)和数据段(__DATA,保存变量值)。
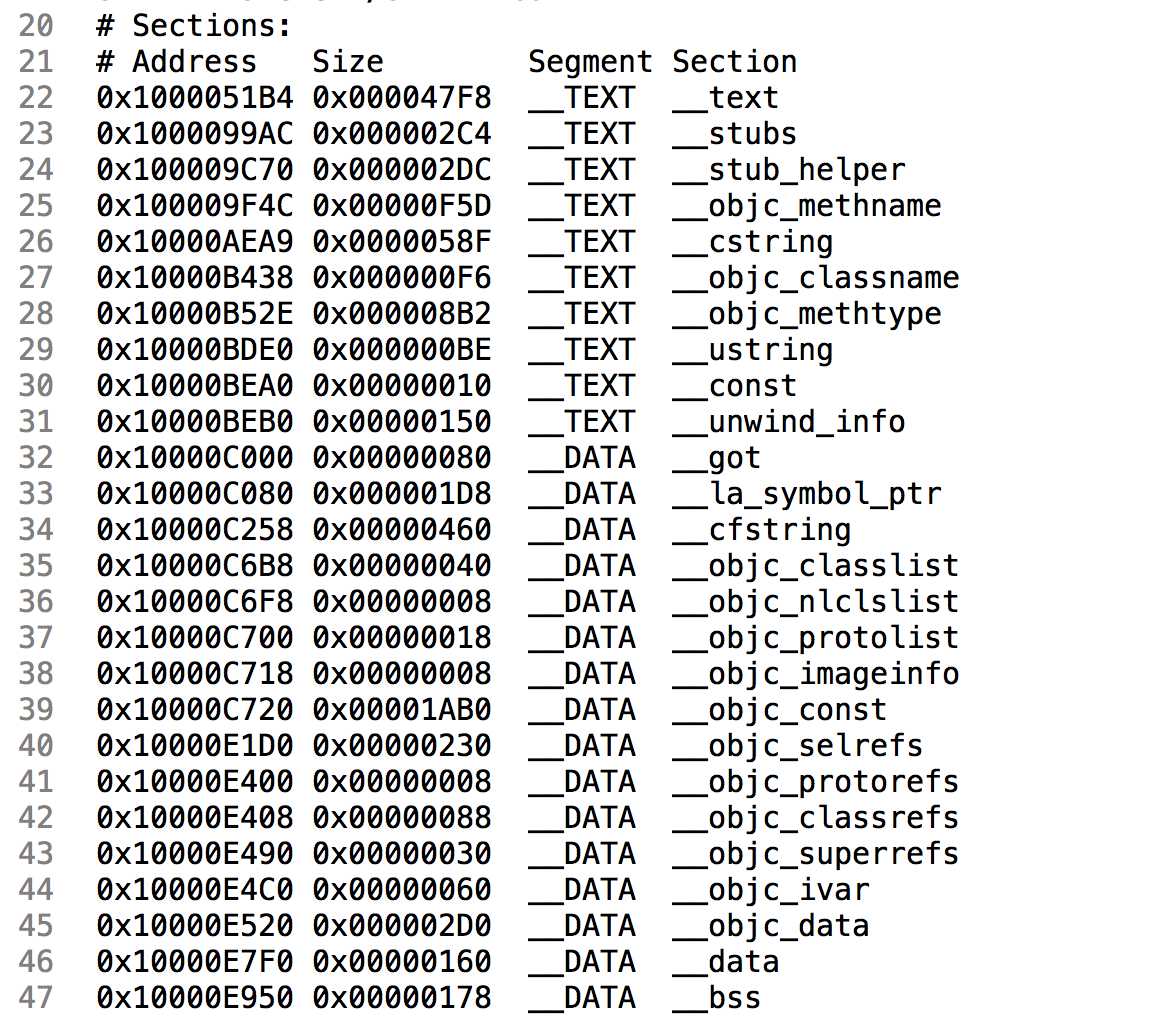
首列是数据在文件的偏移位置,第二列是这一段占用大小,第三列是段类型,代码段和数据段,第四列是段名称。
每一行的数据都紧跟在上一行后面,如第二行__stubs的地址0x1000099AC就是第一行__text的地址0x1000051B4加上大小0x000047F8,整个可执行文件大致数据分布就是这样。
这里可以清楚看到各种类型的数据在最终可执行文件里占的比例,例如__text表示编译后的程序执行语句,__data表示已初始化的全局变量和局部静态变量,__bss表示未初始化的全局变量和局部静态变量,__cstring表示代码里的字符串常量,等等。
Symbols 是对 Sections 进行了再划分,这里会描述所有的 methods、ivar 和字符串,以及它们对应的地址、大小、文件编号信息。

同样首列是数据在文件的偏移地址,第二列是占用大小,第三列是所属文件序号,对应2.2.1中的文件编号,最后是名字。
例如第70行代表了文件序号为3(反查上面就是GofObject.o)的gofName方法占用了48byte大小。
计算某个.o文件在最终安装包中占用的大小,主要是解析目标文件和符号表两个部分,从目标文件读取出每个.o文件名和对应的序号,然后对Symbols中序号相同的文件的Size字段相加,即可得到每个.o文件在最终包的大小。
在上面两节中,我们初步接触了可执行文件的内容,本节我们来分析一下编译过程,以便更深入的熟悉可执行文件。
Xcode 的默认编译器是Clang,Clang 的功能是首先对 Objective-C 代码做分析检查,然后将其转换为低级的类汇编代码:LLVM Intermediate Representation(LLVM 中间表达码)。接着 LLVM 会执行相关指令将 LLVM IR 编译成目标平台上的本地字节码,这个过程的完成方式可以是即时编译 (Just-in-time),或在编译的时候完成。
LLVM 的优点主要得益于它的三层式架构。 第一层支持多种语言作为输入(例如 C, ObjectiveC, C++ 和 Haskell),第二层是一个共享式的优化器(对 LLVM IR 做优化处理),第三层是许多不同的目标平台(例如 Intel, ARM 和 PowerPC)。在这三层式的架构中,如果想要添加一门语言到 LLVM 中,那么可以把重要精力集中到第一层上,如果想要增加另外一个目标平台,那么没必要过多的考虑输入语言。
【说明】:从功能的角度来说,微观的LLVM可以认为是一个编译器的后端,而Clang是一个编译器的前端。关于Clang和LLVM的关系,可以看一下这篇文章。
从一个简单的例子开始:
#include <stdio.h> #define YEAR 2017 int main(int argc, const char * argv[]) { printf("Hello, %d!\n", YEAR); return 0; }
在编译一个源文件时,编译器的处理过程分为几个阶段。要想查看编译 main.m 源文件需要几个不同的阶段,我们可以让通过 clang 命令观察:
clang -ccc-print-phases main.m
结果如下:
0: input, "main.m", objective-c 1: preprocessor, {0}, objective-c-cpp-output 2: compiler, {1}, ir 3: backend, {2}, assembler 4: assembler, {3}, object 5: linker, {4}, image 6: bind-arch, "x86_64", {5}, image
从结果可以看到,从源文件到可执行文件,经过了这么几个过程:预处理、编译、汇编、链接,最终生成可执行文件。
当程序执行时,操作系统将可执行文件拷贝到内存中。那么我们的程序最终是怎么执行的呢?程序的执行是在进程中进行的,程序转化为进程大致分为这么几个步骤:
经过上面几个步骤,操作系统向内核数据结构中添加了适当的信息,并为运行程序代码分配了必要的资源之后,程序就变成了进程。下面我们来分析编译的几个阶段。
执行指令,我们看一下预处理阶段都做了哪些事情:
clang -fmodules -E main.m | open -f
【说明】:目前预处理中引入了模块 - modules功能,这使预处理变得更加的高级。
通过上面的指令,我们看一下输出的结果:
# 1 "main.m" # 1 "<built-in>" 1 # 1 "<built-in>" 3 # 342 "<built-in>" 3 # 1 "<command line>" 1 # 1 "<built-in>" 2 # 1 "main.m" 2 @import Darwin.C.stdio; /* clang -E: implicit import for "/usr/include/stdio.h" */ int main() { printf("Hello, %d!\n", 2017); return 0; }
从结果可以看到,预处理阶段,会进行宏的替换,头文件的导入,以及类似#if的处理。
在Xcode中,可以通过这样的方式查看任意文件的预处理结果:Product -> Perform Action -> Preprocess。如下图所示:
在预处理完成之后,会进行词法分析,这里会把代码切成一个个 Token,比如大小括号,等于号还有字符串等。我们可以通过指令看一下词法分析:
clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m
输出结果如下:
annot_module_include ‘#include <stdio.h> #define YEAR 2017 int main() { printf("Hello, %d!\n", YEAR); // NSLog(@"hello, %@", @"world"); return 0; } ‘ Loc=<main.m:9:1> int ‘int‘ [StartOfLine] Loc=<main.m:12:1> identifier ‘main‘ [LeadingSpace] Loc=<main.m:12:5> l_paren ‘(‘ Loc=<main.m:12:9> r_paren ‘)‘ Loc=<main.m:12:10> l_brace ‘{‘ [LeadingSpace] Loc=<main.m:12:12> identifier ‘printf‘ [StartOfLine] [LeadingSpace] Loc=<main.m:13:5> l_paren ‘(‘ Loc=<main.m:13:11> string_literal ‘"Hello, %d!\n"‘ Loc=<main.m:13:12> comma ‘,‘ Loc=<main.m:13:26> numeric_constant ‘2017‘ [LeadingSpace] Loc=<main.m:13:28 <Spelling=main.m:11:14>> r_paren ‘)‘ Loc=<main.m:13:32> semi ‘;‘ Loc=<main.m:13:33> return ‘return‘ [StartOfLine] [LeadingSpace] Loc=<main.m:15:5> numeric_constant ‘0‘ [LeadingSpace] Loc=<main.m:15:12> semi ‘;‘ Loc=<main.m:15:13> r_brace ‘}‘ [StartOfLine] Loc=<main.m:16:1> eof ‘‘ Loc=<main.m:16:2>
然后进行语法分析,验证语法是否正确,然后将所有节点组成抽象语法树 AST:
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m
结果如下:
TranslationUnitDecl 0x7fbdb7020cd0 <<invalid sloc>> <invalid sloc> |-TypedefDecl 0x7fbdb7021218 <<invalid sloc>> <invalid sloc> implicit __int128_t ‘__int128‘ | `-BuiltinType 0x7fbdb7020f40 ‘__int128‘ |-TypedefDecl 0x7fbdb7021278 <<invalid sloc>> <invalid sloc> implicit __uint128_t ‘unsigned __int128‘ | `-BuiltinType 0x7fbdb7020f60 ‘unsigned __int128‘ |-TypedefDecl 0x7fbdb7021308 <<invalid sloc>> <invalid sloc> implicit SEL ‘SEL *‘ | `-PointerType 0x7fbdb70212d0 ‘SEL *‘ | `-BuiltinType 0x7fbdb7021180 ‘SEL‘ |-TypedefDecl 0x7fbdb70213e8 <<invalid sloc>> <invalid sloc> implicit id ‘id‘ | `-ObjCObjectPointerType 0x7fbdb7021390 ‘id‘ | `-ObjCObjectType 0x7fbdb7021360 ‘id‘ |-TypedefDecl 0x7fbdb70214c8 <<invalid sloc>> <invalid sloc> implicit Class ‘Class‘ | `-ObjCObjectPointerType 0x7fbdb7021470 ‘Class‘ | `-ObjCObjectType 0x7fbdb7021440 ‘Class‘ |-ObjCInterfaceDecl 0x7fbdb7021518 <<invalid sloc>> <invalid sloc> implicit Protocol |-TypedefDecl 0x7fbdb7021878 <<invalid sloc>> <invalid sloc> implicit __NSConstantString ‘struct __NSConstantString_tag‘ | `-RecordType 0x7fbdb7021680 ‘struct __NSConstantString_tag‘ | `-Record 0x7fbdb70215e0 ‘__NSConstantString_tag‘ |-TypedefDecl 0x7fbdb7021908 <<invalid sloc>> <invalid sloc> implicit __builtin_ms_va_list ‘char *‘ | `-PointerType 0x7fbdb70218d0 ‘char *‘ | `-BuiltinType 0x7fbdb7020d60 ‘char‘ |-TypedefDecl 0x7fbdb78049e8 <<invalid sloc>> <invalid sloc> implicit __builtin_va_list ‘struct __va_list_tag [1]‘ | `-ConstantArrayType 0x7fbdb7804990 ‘struct __va_list_tag [1]‘ 1 | `-RecordType 0x7fbdb7804800 ‘struct __va_list_tag‘ | `-Record 0x7fbdb7021958 ‘__va_list_tag‘ |-ImportDecl 0x7fbdb7805230 <main.m:9:1> col:1 implicit Darwin.C.stdio |-FunctionDecl 0x7fbdb78052b8 <line:12:1, line:16:1> line:12:5 main ‘int ()‘ | `-CompoundStmt 0x7fbdb8861140 <col:12, line:16:1> | |-CallExpr 0x7fbdb88610a0 <line:13:5, col:32> ‘int‘ | | |-ImplicitCastExpr 0x7fbdb8861088 <col:5> ‘int (*)(const char *, ...)‘ <FunctionToPointerDecay> | | | `-DeclRefExpr 0x7fbdb7805798 <col:5> ‘int (const char *, ...)‘ Function 0x7fbdb78053c0 ‘printf‘ ‘int (const char *, ...)‘ | | |-ImplicitCastExpr 0x7fbdb88610f0 <col:12> ‘const char *‘ <BitCast> | | | `-ImplicitCastExpr 0x7fbdb88610d8 <col:12> ‘char *‘ <ArrayToPointerDecay> | | | `-StringLiteral 0x7fbdb8861000 <col:12> ‘char [12]‘ lvalue "Hello, %d!\n" | | `-IntegerLiteral 0x7fbdb8861038 <line:11:14> ‘int‘ 2017 | `-ReturnStmt 0x7fbdb8861128 <line:15:5, col:12> | `-IntegerLiteral 0x7fbdb8861108 <col:12> ‘int‘ 0 `-<undeserialized declarations>
我们可以用下面的命令让 clang 输出汇编代码:
clang -S -o - main.m | open -f
结果如下:
//.section 指令指定接下来会执行哪一个段 .section __TEXT,__text,regular,pure_instructions .macosx_version_min 10, 12 //.globl 指令说明 _main 是一个外部符号。这就是我们的 main() 函数。这个函数对于二进制文件外部来说是可见的,因为系统要调用它来运行可执行文件。 .globl _main //.align 指令指出了后面代码的对齐方式。在我们的代码中,后面的代码会按照 16(2^4) 字节对齐,如果需要的话,用 0x90 补齐。 .p2align 4, 0x90 //main 函数的头部: //_main 函数真正开始的地址。这个符号会被 export。二进制文件会有这个位置的一个引用。 _main: ## @main //.cfi_startproc 指令通常用于函数的开始处。CFI 是调用帧信息 (Call Frame Information) 的缩写。这个调用 帧 以松散的方式对应着一个函数。当开发者使用 debugger 和 step in 或 step out 时,实际上是 stepping in/out 一个调用帧。在 C 代码中,函数有自己的调用帧,当然,别的一些东西也会有类似的调用帧。.cfi_startproc 指令给了函数一个 .eh_frame 入口,这个入口包含了一些调用栈的信息(抛出异常时也是用其来展开调用帧堆栈的)。这个指令也会发送一些和具体平台相关的指令给 CFI。它与后面的 .cfi_endproc 相匹配,以此标记出 main() 函数结束的地方。 .cfi_startproc ## BB#0: //ABI ( 应用二进制接口 application binary interface) 指定了函数调用是如何在汇编代码层面上工作的。在函数调用期间,ABI 会让 rbp 寄存器 (基础指针寄存器 base pointer register) 被保护起来。当函数调用返回时,确保 rbp 寄存器的值跟之前一样,这是属于 main 函数的职责。pushq %rbp 将 rbp 的值 push 到栈中,以便我们以后将其 pop 出来。 pushq %rbp Ltmp0: //和.cfi_offset %rbp, -16一起,会输出一些关于生成调用堆栈展开和调试的信息。我们改变了堆栈和基础指针,而这两个指令可以告诉编译器它们都在哪儿,或者更确切的,它们可以确保之后调试器要使用这些信息时,能找到对应的东西。 .cfi_def_cfa_offset 16 Ltmp1: .cfi_offset %rbp, -16 //把局部变量放置到栈上 movq %rsp, %rbp Ltmp2: .cfi_def_cfa_register %rbp //将栈指针移动 16 个字节,也就是函数会调用的位置 subq $16, %rsp //leaq 会将 L_.str 的指针加载到 rdi 寄存器中。 leaq L_.str(%rip), %rdi movl $2017, %esi ## imm = 0x7E1 movl $0, -4(%rbp) //把使用来存储参数的寄存器数量存储在寄存器 al 中 movb $0, %al //调用 printf() 函数 callq _printf //下面的代码将 ecx 寄存器设置为 0,并把 eax 寄存器的值保存至栈中,然后将 ect 中的 0 拷贝至 eax 中。ABI 规定 eax 将用来保存一个函数的返回值 xorl %esi, %esi movl %eax, -8(%rbp) ## 4-byte Spill movl %esi, %eax //把堆栈指针 rsp 上移 32 字节 addq $16, %rsp //把之前存储至 rbp 中的值从栈中弹出来 popq %rbp //返回调用者, ret 会读取出栈的返回地址 retq .cfi_endproc //.section 指令指出下面将要进入的段 .section __TEXT,__cstring,cstring_literals //L_.str 标记运行在实际的代码中获取到字符串的一个指针 L_.str: ## @.str //.asciz 指令告诉编译器输出一个以 ‘\0’ (null) 结尾的字符串。 .asciz "Hello, %d!\n" .section __DATA,__objc_imageinfo,regular,no_dead_strip L_OBJC_IMAGE_INFO: .long 0 .long 64 //.subsections_via_symbols 指令是静态链接编辑器使用的 .subsections_via_symbols
关于汇编指令的资料,可以在 苹果的 OS X Assembler Reference 中进行查看和学习。
在Xcode中,可以通过这样的方式查看任意文件的汇编输出结果:Product -> Perform Action -> Assemble。如下图所示:
汇编器将可读的汇编代码转换为机器代码。它会创建一个目标对象文件,一般简称为 对象文件。这些文件以 .o 结尾。如果用 Xcode 构建应用程序,可以在工程的 derived data 目录中,Objects-normal 文件夹下找到这些文件。
我们也可以通过如下指令来生成:
clang -fmodules -c main.m -o main.o
链接器解决了目标文件和库之间的链接。 如上面的汇编代码:
callq _printf
printf() 是 libc 库中的一个函数。无论怎样,最后的可执行文件需要能需要知道 printf() 在内存中的具体位置:例如,_printf 的地址符号是什么。链接器会读取所有的目标文件 (此处只有一个) 和库 (此处是 libc),并解决所有未知符号 (此处是 _printf) 的问题。然后将它们编码进最后的可执行文件中 (可以在 libc 中找到符号 _printf),接着链接器会输出可以运行的执行文件。
这里我们讲一个复杂点的可执行文件。
//main.m #import "GofClass.h" int main() { GofClass *gofClass = [[GofClass alloc] init]; [gofClass doSomethingWithName:@"写代码"]; return 0; } //GofClass.h #import <Foundation/Foundation.h> @interface GofClass : NSObject /** 做某项事情 @param workName 事情名称 */ - (void)doSomethingWithName:(NSString *)workName; @end //GofClass.m #import "GofClass.h" @implementation GofClass - (void)doSomethingWithName:(NSString *)workName { NSLog(@"开始%@", workName); } @end
通过如下指令来分别生成各个类的目标文件,并最终生成可执行文件:
clang -fmodules -c main.m -o main.o clang -fmodules -c GofClass.m -o GofClass.o //生成可执行文件 clang main.o GofClass.o -o GofMachOFile
可执行文件和目标文件都有一个符号表,这个符号表规定了它们的符号。如果我们用 nm(1) 工具观察一下 main.o 目标文件,可以看到如下内容:
//指令 xcrun nm -nm main.o //结果 (undefined) external _OBJC_CLASS_$_GofClass (undefined) external ___CFConstantStringClassReference (undefined) external _objc_msgSend 0000000000000000 (__TEXT,__text) external _main 00000000000000b0 (__TEXT,__ustring) non-external l_.str
external _OBJC_CLASS_$_GofClass是GofClass Objective-C 类的符号。该符号是 undefined, external 。External 的意思是指对于这个目标文件该类并不是私有的,相反,non-external 的符号则表示对于目标文件是私有的。我们的 helloworld.o 目标文件引用了类 Foo,不过这并没有实现它。因此符号表中将其标示为 undefined。
同样的我们也看一下GofClass.o:
//指令 xcrun nm -nm GofClass.o //结果 (undefined) external _NSLog (undefined) external _OBJC_CLASS_$_NSObject (undefined) external _OBJC_METACLASS_$_NSObject (undefined) external ___CFConstantStringClassReference (undefined) external __objc_empty_cache 0000000000000000 (__TEXT,__text) non-external -[GofClass doSomethingWithName:] 0000000000000030 (__TEXT,__ustring) non-external l_.str 0000000000000070 (__DATA,__objc_const) non-external l_OBJC_METACLASS_RO_$_GofClass 00000000000000b8 (__DATA,__objc_const) non-external l_OBJC_$_INSTANCE_METHODS_GofClass 00000000000000d8 (__DATA,__objc_const) non-external l_OBJC_CLASS_RO_$_GofClass 0000000000000120 (__DATA,__objc_data) external _OBJC_METACLASS_$_GofClass 0000000000000148 (__DATA,__objc_data) external _OBJC_CLASS_$_GofClass
接下来我们看一下可执行文件:
//指令 xcrun nm -nm GofMachOFile //结果 (undefined) external _NSLog (from Foundation) (undefined) external _OBJC_CLASS_$_NSObject (from CoreFoundation) (undefined) external _OBJC_METACLASS_$_NSObject (from CoreFoundation) (undefined) external ___CFConstantStringClassReference (from CoreFoundation) (undefined) external __objc_empty_cache (from libobjc) (undefined) external _objc_msgSend (from libobjc) (undefined) external dyld_stub_binder (from libSystem) 0000000100000000 (__TEXT,__text) [referenced dynamically] external __mh_execute_header 0000000100000ea0 (__TEXT,__text) external _main 0000000100000f10 (__TEXT,__text) non-external -[GofClass doSomethingWithName:] 0000000100001140 (__DATA,__objc_data) external _OBJC_METACLASS_$_GofClass 0000000100001168 (__DATA,__objc_data) external _OBJC_CLASS_$_GofClass
可以看到所有的 Foundation 和 Objective-C 运行时符号依旧是 undefined,不过现在的符号表中已经多了如何解析它们的信息,例如在哪个动态库中可以找到对应的符号。
在运行时,动态链接器 dyld也可以解析这些 undefined 符号,并指向它们在 Foundation 中的实现等。
当构建一个程序时,将会链接各种各样的库。它们又会依赖其他一些 framework 和 动态库。需要加载的动态库会非常多。而对于相互依赖的符号就更多了。可能将会有上千个符号需要解析处理,这将花费很长的时间:一般是好几秒钟。
为了缩短这个处理过程所花费时间,在 OS X 和 iOS 上的动态链接器使用了共享缓存,共享缓存存于 /var/db/dyld/。对于每一种架构,操作系统都有一个单独的文件,文件中包含了绝大多数的动态库,这些库都已经链接为一个文件,并且已经处理好了它们之间的符号关系。当加载一个 Mach-O 文件 (一个可执行文件或者一个库) 时,动态链接器首先会检查 共享缓存 看看是否存在其中,如果存在,那么就直接从共享缓存中拿出来使用。每一个进程都把这个共享缓存映射到了自己的地址空间中。这个方法大大优化了 OS X 和 iOS 上程序的启动时间。
上面介绍了可执行文件的结构以及整个编译过程,介绍这些内容是为了对可执行文件以及它的来历有一个了解,下面我们分析一下对可执行文件的瘦身都有哪些方法。
我们知道,可执行文件是由我们编写的代码产生的。通过脚本分析前面说的LinkMap文件,我们可以更加清晰的知道具体的某个文件大小。
#!usr/bin/python ## -*- coding: UTF-8 -*- # #使用简介:python linkmap.py XXX-LinkMap-normal-xxxarch.txt 或者 python linkmap.py XXX-LinkMap-normal-xxxarch.txt | open -f #使用参数-g会统计每个模块.o的统计大小 # __author__ = "zmjios" __date__ = "2017-05-05" import os import re import shutil import sys class SymbolModel: file = "" size = 0 def verify_linkmapfile(args): if len(sys.argv) < 2: print("请输入linkMap文件") return False path = args[1] if not os.path.isfile(path): print("请输入文件") return False file = open(path) content = file.read() file.close() #查找是否存在# Object files: if content.find("# Object files:") == -1: print("输入linkmap文件非法") return False #查找是否存在# Sections: if content.find("# Sections:") == -1: print("输入linkmap文件非法") return False #查找是否存在# Symbols: if content.find("# Symbols:") == -1: print("输入linkmap文件非法") return False return True def symbolMapFromContent(): symbolMap = {} reachFiles = False reachSections = False reachSymblos = False file = open(sys.argv[1]) for line in file.readlines(): if line.startswith("#"): if line.startswith("# Object files:"): reachFiles = True if line.startswith("# Sections:"): reachSections = True if line.startswith("# Symbols:"): reachSymblos = True else: if reachFiles == True and reachSections == False and reachSymblos == False: #查找 files 列表,找到所有.o文件 location = line.find("]") if location != -1: key = line[:location+1] if symbolMap.get(key) is not None: continue symbol = SymbolModel() symbol.file = line[location + 1:] symbolMap[key] = symbol elif reachFiles == True and reachSections == True and reachSymblos == True: #‘\t‘分割成三部分,分别对应的是Address,Size和 File Name symbolsArray = line.split(‘\t‘) if len(symbolsArray) == 3: fileKeyAndName = symbolsArray[2] #16进制转10进制 size = int(symbolsArray[1],16) location = fileKeyAndName.find(‘]‘) if location != -1: key = fileKeyAndName[:location + 1] symbol = symbolMap.get(key) if symbol is not None: symbol.size = symbol.size + size file.close() return symbolMap def sortSymbol(symbolList): return sorted(symbolList, key=lambda s: s.size,reverse = True) def buildResultWithSymbols(symbols): results = ["文件大小\t文件名称\r\n"] totalSize = 0 for symbol in symbols: results.append(calSymbol(symbol)) totalSize += symbol.size results.append("总大小: %.2fM" % (totalSize/1024.0/1024.0)) return results def buildCombinationResultWithSymbols(symbols): #统计不同模块大小 results = ["库大小\t库名称\r\n"] totalSize = 0 combinationMap = {} for symbol in symbols: names = symbol.file.split(‘/‘) name = names[len(names) - 1].strip(‘\n‘) location = name.find("(") if name.endswith(")") and location != -1: component = name[:location] combinationSymbol = combinationMap.get(component) if combinationSymbol is None: combinationSymbol = SymbolModel() combinationMap[component] = combinationSymbol combinationSymbol.file = component combinationSymbol.size = combinationSymbol.size + symbol.size else: #symbol可能来自app本身的目标文件或者系统的动态库 combinationMap[symbol.file] = symbol sortedSymbols = sortSymbol(combinationMap.values()) for symbol in sortedSymbols: results.append(calSymbol(symbol)) totalSize += symbol.size results.append("总大小: %.2fM" % (totalSize/1024.0/1024.0)) return results def calSymbol(symbol): size = "" if symbol.size / 1024.0 / 1024.0 > 1: size = "%.2fM" % (symbol.size / 1024.0 / 1024.0) else: size = "%.2fK" % (symbol.size / 1024.0) names = symbol.file.split(‘/‘) if len(names) > 0: size = "%s\t%s" % (size,names[len(names) - 1]) return size def analyzeLinkMap(): if verify_linkmapfile(sys.argv) == True: print("**********正在开始解析*********") symbolDic = symbolMapFromContent() symbolList = sortSymbol(symbolDic.values()) if len(sys.argv) >= 3 and sys.argv[2] == "-g": results = buildCombinationResultWithSymbols(symbolList) else: results = buildResultWithSymbols(symbolList) for result in results: print(result) print("***********解析结束***********") if __name__ == "__main__": analyzeLinkMap()
执行脚本之后,输出结果示例如下:
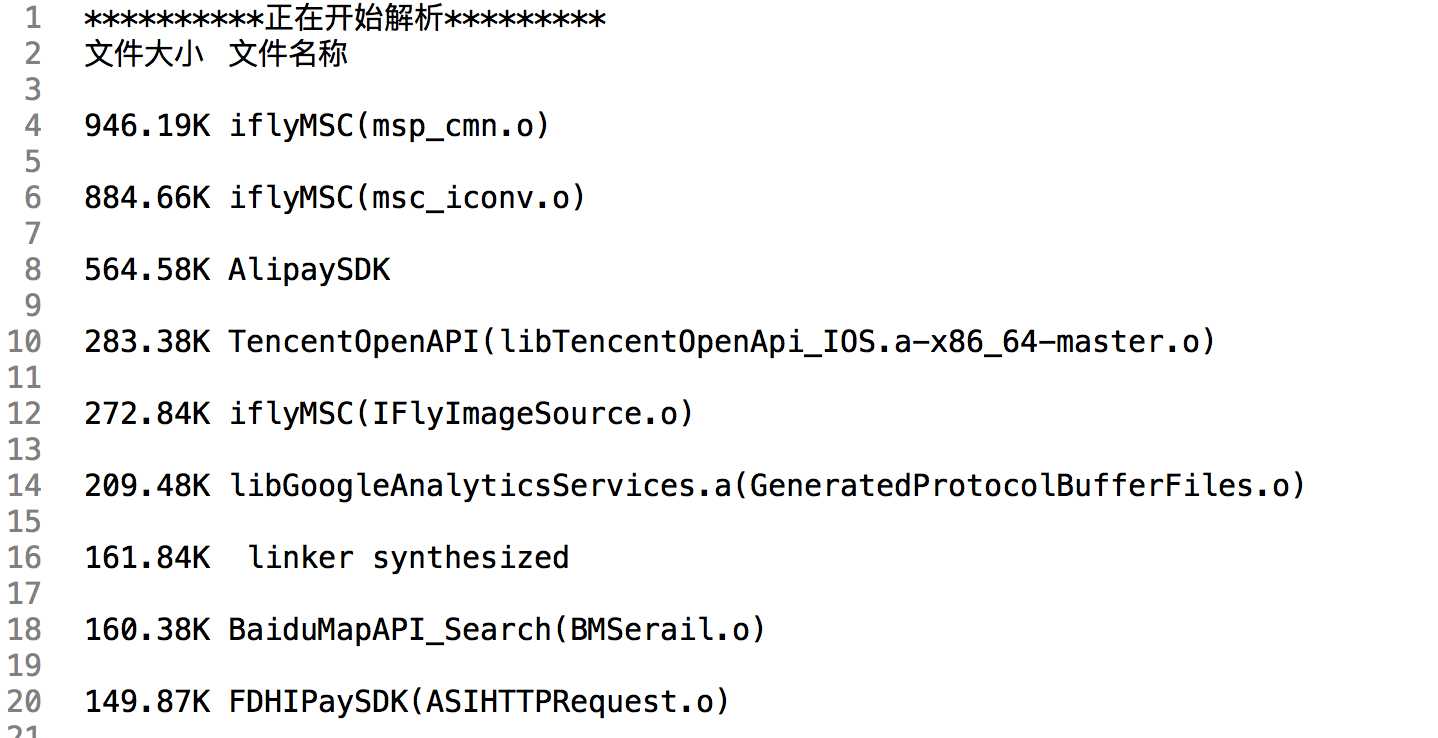
从结果看到,不仅是我们编写的类的大小可以统计出来,第三方的也可以。在实际工程中,我们可以对一些可执行文件中过大的第三方库,思考其存在的必要性,对于不需要存在或者有替换方案的,可以考虑替换或删除。
从结果看到,不仅是我们编写的类的大小可以统计出来,第三方的也可以。在实际工程中,我们可以对一些可执行文件中过大的第三方库,思考其存在的必要性,对于不需要存在或者有替换方案的,可以考虑替换或删除。
AppCode是一种智能的Objective-C集成开发环境,由专业的开发收费IDE的公司Jetbrains开发,具有这些特点:
在这里,我们可以用它的inspect code来扫描无用代码,包括无用的类、函数、宏定义、value、属性等,而safe delete功能使得删除一些由于runtime被调用到的代码时更加安全智能。扫描结果示例:
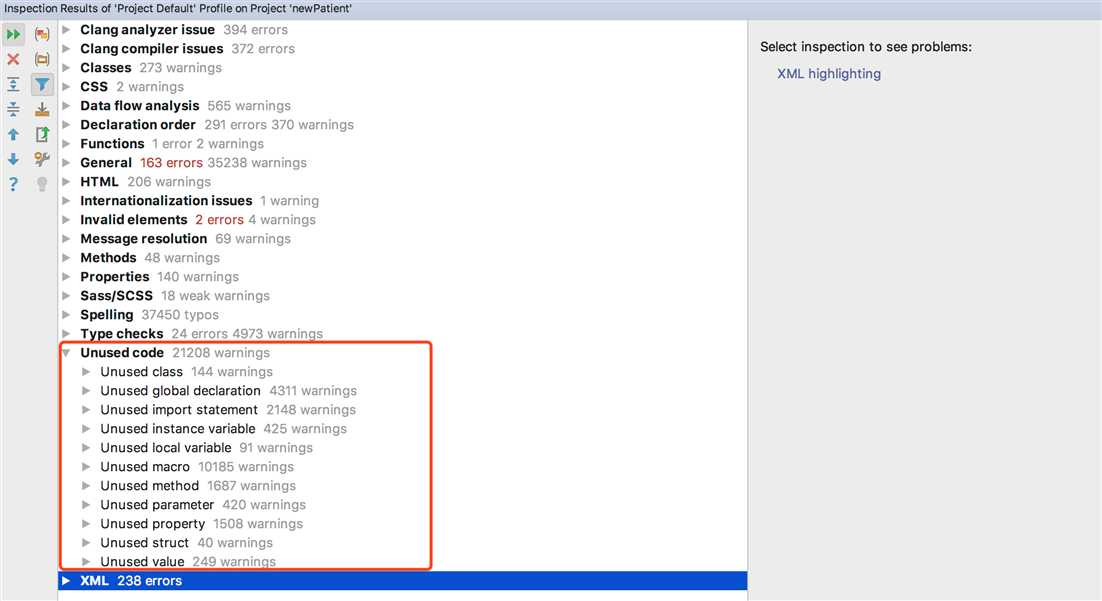
【说明】:如果工程很大,这个扫描的时间可能会比较长。我们现在的工程中,大概有2700个类,扫描时间在一个半小时。
实际上,在2.4.1的扫描结果中,包含无用类,但2.4.1的扫描时间会比较长,另外扫描出来的内容也较多。如果只是需要清理无用类的话,可以用如下脚本:
#!/usr/bin/env python # 使用方法:python py文件 Xcode工程文件目录 # -*- coding:UTF-8 -*- import sys import os import re if len(sys.argv) == 1: print ‘请在.py文件后面输入工程路径‘ sys.exit() projectPath = sys.argv[1] print ‘工程路径为%s‘ % projectPath resourcefile = [] totalClass = set([]) unusedFile = [] pbxprojFile = [] def Getallfile(rootDir): for lists in os.listdir(rootDir): path = os.path.join(rootDir, lists) if os.path.isdir(path): Getallfile(path) else: ex = os.path.splitext(path)[1] if ex == ‘.m‘ or ex == ‘.mm‘ or ex == ‘.h‘: resourcefile.append(path) elif ex == ‘.pbxproj‘: pbxprojFile.append(path) Getallfile(projectPath) print ‘工程中所使用的类列表为:‘ for ff in resourcefile: print ff for e in pbxprojFile: f = open(e, ‘r‘) content = f.read() array = re.findall(r‘\s+([\w,\+]+\.[h,m]{1,2})\s+‘,content) see = set(array) totalClass = totalClass|see f.close() print ‘工程中所引用的.h与.m及.mm文件‘ for x in totalClass: print x print ‘--------------------------‘ for x in resourcefile: ex = os.path.splitext(x)[1] if ex == ‘.h‘: #.h头文件可以不用检查 continue fileName = os.path.split(x)[1] print fileName if fileName not in totalClass: unusedFile.append(x) for x in unusedFile: resourcefile.remove(x) print ‘未引用到工程的文件列表为:‘ writeFile = [] for unImport in unusedFile: ss = ‘未引用到工程的文件:%s\n‘ % unImport writeFile.append(ss) print unImport unusedFile = [] allClassDic = {} for x in resourcefile: f = open(x,‘r‘) content = f.read() array = re.findall(r‘@interface\s+([\w,\+]+)\s+:‘,content) for xx in array: allClassDic[xx] = x f.close() print ‘所有类及其路径:‘ for x in allClassDic.keys(): print x,‘:‘,allClassDic[x] def checkClass(path,className): f = open(path,‘r‘) content = f.read() if os.path.splitext(path)[1] == ‘.h‘: match = re.search(r‘:\s+(%s)\s+‘ % className,content) else: match = re.search(r‘(%s)\s+\w+‘ % className,content) f.close() if match: return True ivanyuan = 0 totalIvanyuan = len(allClassDic.keys()) for key in allClassDic.keys(): path = allClassDic[key] index = resourcefile.index(path) count = len(resourcefile) used = False offset = 1 ivanyuan += 1 print ‘完成‘,ivanyuan,‘共:‘,totalIvanyuan,‘path:%s‘%path while index+offset < count or index-offset > 0: if index+offset < count: subPath = resourcefile[index+offset] if checkClass(subPath,key): used = True break if index - offset > 0: subPath = resourcefile[index-offset] if checkClass(subPath,key): used = True break offset += 1 if not used: str = ‘未使用的类:%s 文件路径:%s\n‘ %(key,path) unusedFile.append(str) writeFile.append(str) for p in unusedFile: print ‘未使用的类:%s‘ % p filePath = os.path.split(projectPath)[0] writePath = ‘%s/未使用的类.txt‘ % filePath f = open(writePath,‘w+‘) f.writelines(writeFile) f.close()
同样的工程,这个脚本执行速度大概是三分钟,结果如下:

以往C++在链接时,没有被用到的类和方法是不会编进可执行文件里。但Objctive-C不同,由于它的动态性,它可以通过类名和方法名获取这个类和方法进行调用,所以编译器会把项目里所有OC源文件编进可执行文件里,哪怕该类和方法没有被使用到。
结合LinkMap文件的__TEXT.__text,通过正则表达式([+|-][.+\s(.+)]),我们可以提取当前可执行文件里所有objc类方法和实例方法(SelectorsAll)。再使用otool命令otool -v -s __DATA __objc_selrefs逆向__DATA.__objc_selrefs段,提取可执行文件里引用到的方法名(UsedSelectorsAll),我们可以大致分析出SelectorsAll里哪些方法是没有被引用的(SelectorsAll-UsedSelectorsAll)。
标签:指针 目的 特定 分布 继承 loading represent private 光栅化
原文地址:http://www.cnblogs.com/LeeGof/p/6803146.html