标签:排序 ges obj employee 利用 独立 而在 其他 二分
在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能。但索引可以在大多数情况下大大提升查询性能高。在OLAP中尤其明显,要完全理解索引的概念,需要了解大量原理性的知识,包括B树,堆,数据库页,区,填充因子,碎片,文件组等等一系列相关知识。
索引时对数据库中表中一列和多列的值进行排序的一种结构,使用索引可以快速访问数据表中特定的信息。
精简来说,索引时一种结构,在SQL Server中,索引和表(这里值得是加了聚集索引的表)的存储结构是一样的,都是B树,B树是一种用于查找平衡多叉树,理解B树的概念如下图:
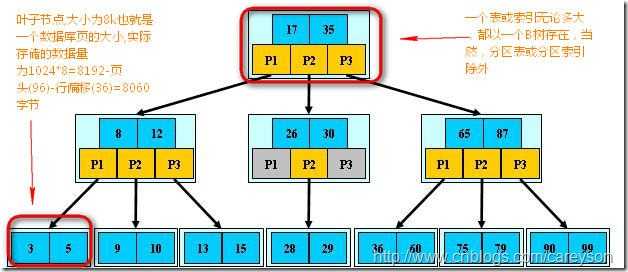
理解为什么使用B树作为索引和表(有聚集索引)的结构,首先需要理解SQL Server存储数据的原理。
B树,即二叉搜索树,结构特点:
1、所有非叶子节点至多拥有两个子节点(Left和Right)
2、所有的节点存储一个关键字
3、非页子节点的左指针指向小于其关键字的子树,右节点指向大于其关键字的子树
看下面结构图:
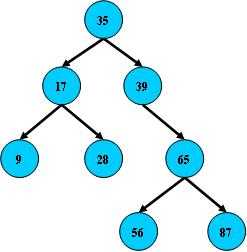
B树的搜索,从根节点开始,如果查询的关键字与结点相等,那么就命中,否则,如果查询的关键字比结点关键字小,则进入左节点,如果比关键字大,就进入右结点;如果左结点或右结点指针为空,则报告找不到相应的关键字。
如果B树的所有非叶子结点的左右子树的节点数目保持差不多(平衡),那么B树的搜索性能逼近二分查找,但它比连续内存空间的二分查找的优点是:改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销,这也是数据表和索引采取这种方式存储的有点。
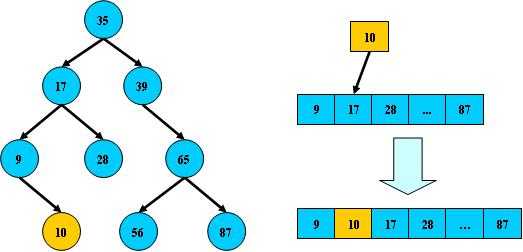
但这样,也会带来相应的缺点,就是B树经过多次插入和删除后,有可能导致结构的变化:
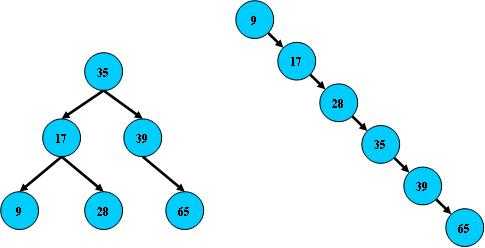
右边也是一个B树,但它的索性能已经是线性的了,同样的关键字集合有可能导致不同的树结构索引,所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,这就出现了平衡二叉树的算法。
实际的使用B树都是在B树的基础上加上平衡算法,即“平衡二叉树”;如果保持B树节点分布均匀的平衡算法是平衡二叉树的关键。平衡算法是一种在B树中插入和删除结点的策略;
另一种是多路搜索树(并不是二叉的)该树所有的特点是:
1、定义任意非叶子子节点最多只有M个子节点,且M>2
2、根节点的子节点数为[2,M]
3、除根节点意外的非叶子结点的子节点数为[M/2,M]
4、每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少两个关键字)
5、非叶子节点的关键字个数=指向子节点的指针个数-1
6、非叶子结点的关键字:k[1],k[2]......k[M-1],且k[i]<k[i+1]
7、非叶子结点的指针:p[1],p[2]....p[M];其中p[1]指向关键字k[1]的子树,p[M]指向关键字大于K[M-1]的子树,其他p[i]指向关键字属于(K[i-1],K[i])的子树;
8、所有叶子结点位于同一层 如:(M=3)
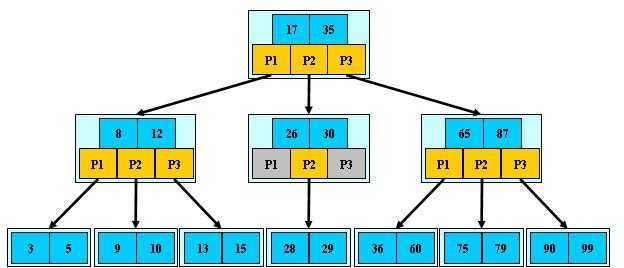
B树的搜索,从根结点开始,对节点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B树的特性:
1、关键字集合分布在整棵树中;
2、任何一个关键字出现而且只出现在一个结点中
3、搜索有可能在非叶子结点结束
4、其搜索性能等价于在关键字全集内做一次二分查找
5、自动层次控制
由于限制了除结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率。其最低搜索性能为:
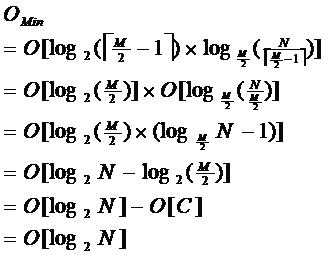
其中,M为设定的非叶子结点最多子树个数,N为关键字总数,所以B-树的性能总是等价于二分查找(与M值无关),也就是没有B树平衡的问题,由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2及诶单,删除结点时,需要将两个不足M/2结点合并,确保平衡。
有点复杂,说实话个人也不了解,大体懂得这种结构的存储形式就可以,在SQL Server中,存储的单位最小的是页(page),页是不可再分的。原子性,这就意味着SQL Server中对于页的读取,要不整个读取,要么完全不读取,没有折中方案。
在数据库检索来说,对于磁盘IO扫描时最消耗时间的,因为磁盘扫描涉及很多物理特性,这些是相当消耗时间的。所以B树涉及的初衷就是最大限度的减少对于磁盘的扫描次数。如果一个表或索引没有使用B树(对于没有聚集索引的表是用堆heap存储),那么查找一个数据,需要在整个表包含的数据库页中全盘扫描。这无疑会大大加重IO负担,而在SQL Server中使用B树进行存储,则仅仅需要将B树的根节点存入内存中,经过几次查找后就可以找到存放需要数据的被叶子结点包含的页,进而避免了全盘扫描从而提高了性能。
下面,通过一个例子来证明:
在SQL Server中,表上如果没有建立聚集索引,则是按照堆Heap存放的,假设我有这样一张表
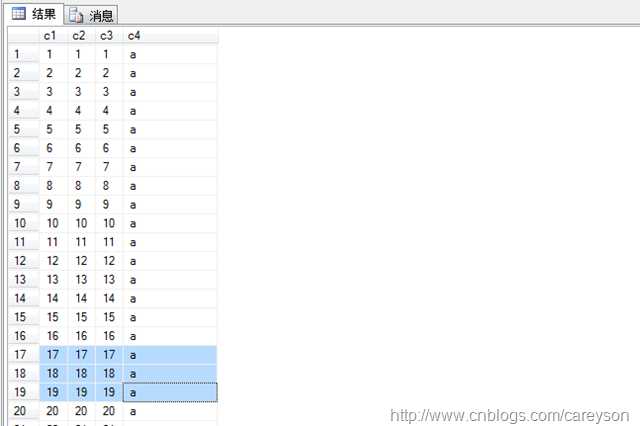
现在这种表上没有任何索引,也就是以堆存放,我们通过在其上加上聚集索引(以B树存放)来展现对IO的减少:
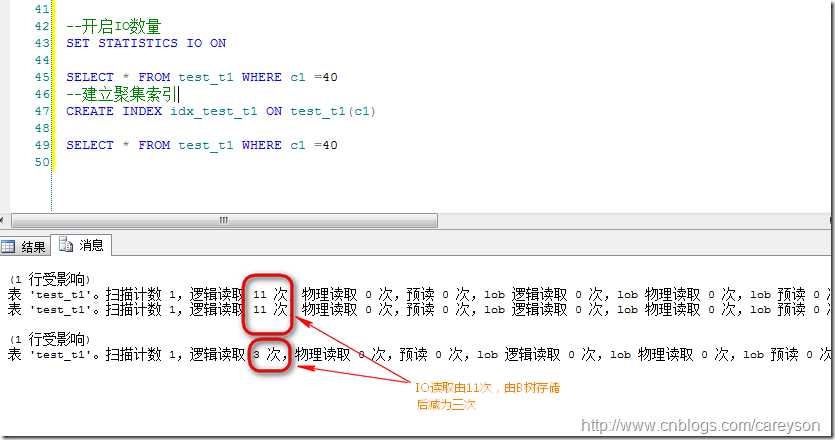
理解聚集和聚集索引
在SQL Server中,最主要的两类索引时聚集索引和非聚集索引。可以看到,这两个分类都是围绕聚集这个关键字进行的,那么首先理解什么是聚集。
聚集在索引中的定义:
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(成为聚集码)上具有相同值得元组集合中存放在连续的物理块成为聚集。
简单来说,聚集索引就是:
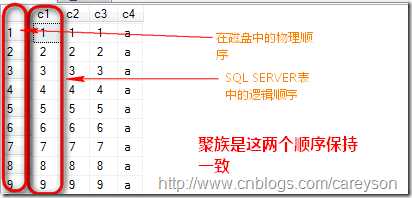
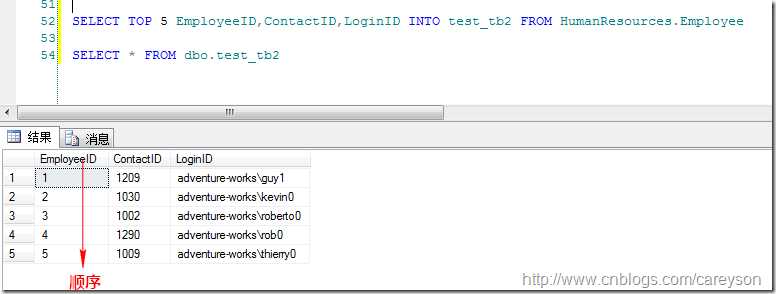
在SQL Server中,聚集的作用就是将某一列(或是多列)的物理顺序改变为和逻辑顺序相一致,比如,我从adventureworks数据库中的employee抽取5条数据:
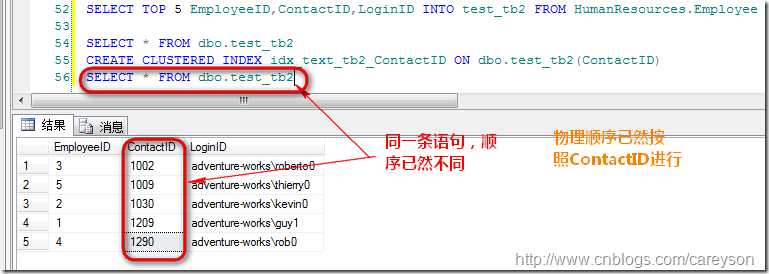
当我在ContactID上建立聚集索引时,再次查询:
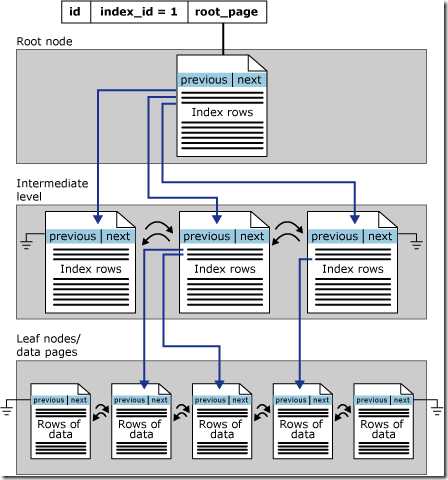
在SQL Server中,聚集索引的存储是以B树存储,B树的叶子直接存储聚集索引的数据:
因为聚集索引改变的是其所在表的物理存储顺序,所以每个表只能有一个聚集索引。
非聚集索引
因为每个表只能有一个聚集索引,如果我们对一个表的查询不仅仅限于聚集索引上的字段。我们又对聚集索引列之外还有索引的要求,那么就需要非聚集索引了。
非聚集索引,本质上来说也是聚集索引的一种,非聚集索引并不改变其所在表的物理结构,而是额外生成一个聚集索引的B树结构,但叶节点是对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号;如果其所在表上已经有了聚集索引,则引用聚集索引的页,从而实现更大限度的使用。
一个简单的非聚集索引概念如下:
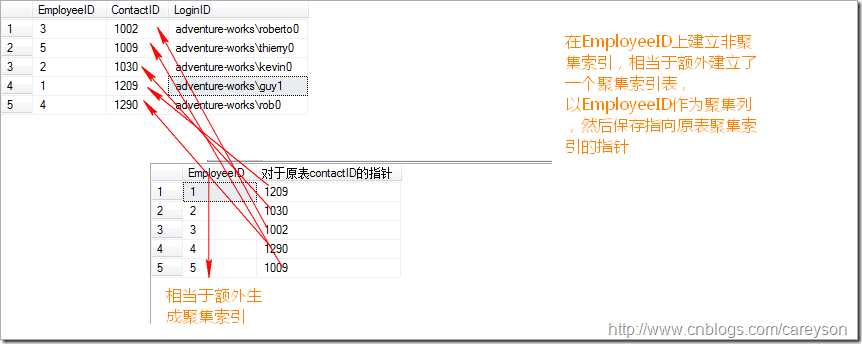
可以看到,非聚集索引需要额外的空间进行空间存储,按照被索引列进行聚集索引,并在B树的叶子结点包含指向非聚集索引所在的指针。
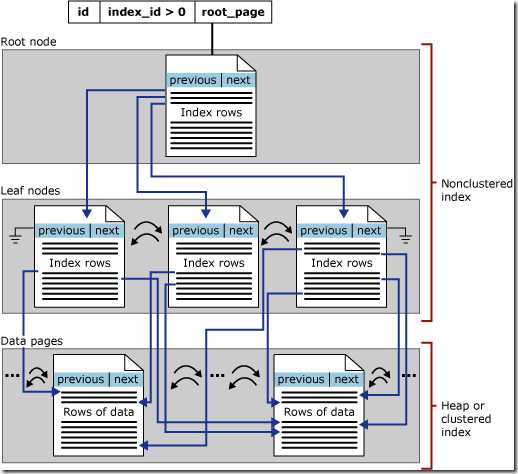
可以看到,非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子结点存的是指向堆或聚集索引的指针。
通过非聚集索引的原理可以看出,如果其所在表的物理结构改变后,比如加上或是删除聚集索引,那么所有非聚集索引都需要被重建,这个对于性能的耗损是相当大的。所以最好要建立聚集索引,再建立对应的非聚集索引。
聚集索引VS非聚集索引
前面通过对于聚集索引和非聚集索引的原理解释,我们不难发现,大多数情况下,聚集索引的速度比非聚集索引要略快一些,因为聚集索引的B树叶子节点直接存放数据,而非聚集索引还需要额外通过叶子节点的指针找到数据。
还有,对于大量连续数据查找,非聚集索引十分乏力,因为非聚集索引需要在非聚集索引的B树中找到每一行的指针,再去其所在表上找数据,性那因此会大打折扣,有时候甚至不如不加非聚集索引。
因此,大多数情况下非聚集索引都要快于非聚集索引。但聚集索引只能有一个,因此选对聚集索引所施加的列对于查询性能提升至关紧要。
填充因子
在B树组作为索引的物理存储结构的时候,这里面还涉及一个新的概念:填充因子,因为从上面的B树结构看以看出,当数据表在面积的删除和增加的时候,需要动态的修改B树中的索引结构,为了实现B树的平衡,达到搜索二分法优化查询的作用,需要在B树非页结点中每个结点都留出一定的空间来记录新数据或者描述删除数据,这一部分就被称作填充因子,看MSDN中的解释:
提供填充因子选项是为了优化索引存储和性能。当创建或重新生成索引时,填充因子的值可确定每个页级页上要填充数据的空间百分比,以便在每一页上保留一些剩余空间作为以后扩展索引的可用空间。例如,指定填充因子的值为80表示每个叶级页上将有20%的空间保留为空,以便随着向基础表中添加数据而为扩展索引提供空间。在索引之间保留可用空间,而不是在索引的末尾保留。但这里需要注意,当填充因子为0并不表示页全部为数据,反而表示完全填充级页。填充因子的值得是1到100之间的百分比。
索引的使用
索引的使用并不需要显示使用,建立索引后查询分析器会自动找到最短路径使用索引。
但是这种情况,当随着数据量的增长,产生了索引碎片,很多存储的数据进行了不适当的跨页,会造成碎片,所以我们需要重新建立索引加快性能。
比如前面的Test_tb2上建立的一个聚集索引和非聚集索引,可以通过DMV语句查询器索引情况:
SELECT index_type_desc,alloc_unit_type_desc,avg_fragmentation_in_percent,fragment_count,avg_fragment_size_in_pages,page_count,record_count,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(‘AdventureWorks‘),OBJECT_ID(‘test_tb2‘),NULL,NULL,‘Sampled‘)
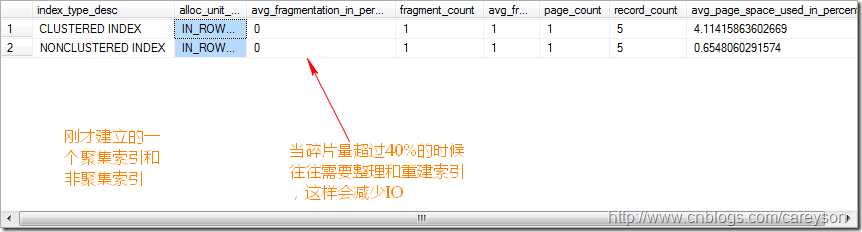
我们可以通过重建索引来提高速度:
ALTER INDEX idx_text_tb2_EmployeeID ON test_tb2 REBUILD
还有一种情况是,当随着表数据量的增大,有时候需要更新表上的统计信息,让查询分析器根据这些信息选择路径,使用:
UPDATE STATISTICS 表名
那么什么时候知道需要更新这些统计信息呢,就是当执行计划中估计行数和实际表的行数有出入时:
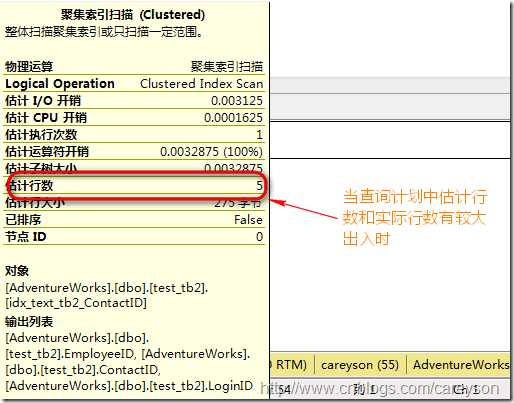
索引的代价
当然索引的使用也是要付出代价的:
1、通过聚集索引的原理我们知道,当表建立索引后,就可以B树来存储数据,所以当对其进行更新插入删除,就需要页在物理上移动以调整B树,因此当更新插入删除数据时,会带来性能的下降。而对于非聚集索引,当更新表后,非聚集索引需要进行更新,相当于多更新了N(N=非聚集索引数量)个表。因此也下降了性能。
2、通过上面对非聚集索引原理的介绍,可以看到,非聚集索引需要额外的磁盘空间。
3、前文提过,不恰当的非聚集索引反而会减低性能。
所以使用索引需要根据实际情况进行权衡.通常我都会将非聚集索引全部放到另外一个独立硬盘上,这样可以分散IO,从而使查询并行.
标签:排序 ges obj employee 利用 独立 而在 其他 二分
原文地址:http://www.cnblogs.com/liaods/p/6817180.html