标签:bin config abs 技术分享 ora open ubuntu file hdfs
1.环境:ubuntu、hadoop2.7.3
2.在Ubuntu下创建hadoop用户组和用户
① 添加hadoop用户到系统用户
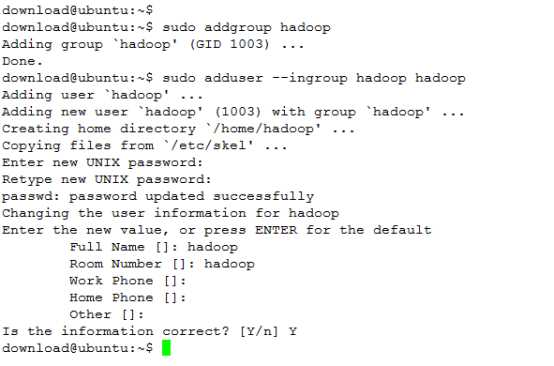
② 现在只是添加了一个用户hadoop,它并不具备管理员权限,我们给hadoop用户添加权限,打开/etc/sudoers文件
命令:sudo vi /etc/sudoers
③ 在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL
此文件为只读文件,修改后强制保存::wq!
3.安装ssh服务
命令:sudo apt-get install ssh openssh-server
4.使用ssh进行无密码验证登录
① 先进入hadoop用户
命令: su hadoop
② 作为一个安全通信协议(ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式),使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
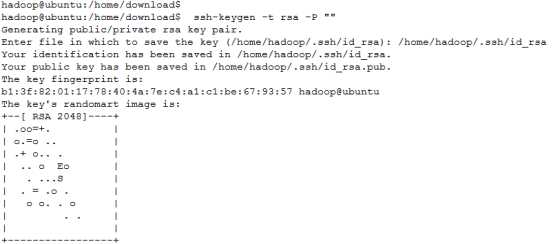
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的前者为私钥,后者为公钥)
进入~/.ssh/目录下,将公钥id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的(authorized_keys 用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
命令:cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
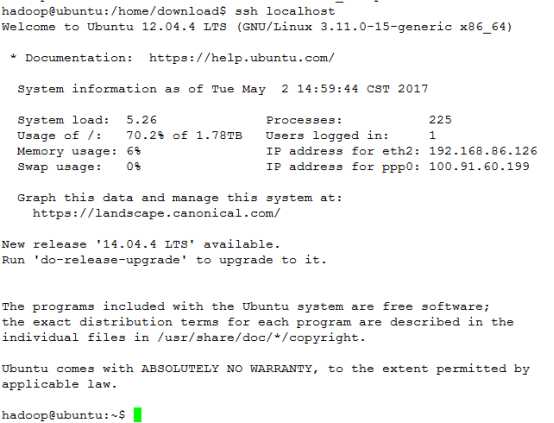
③ 然后即可无密码验证登录了
命令:ssh localhost
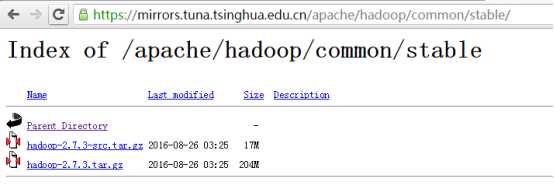
5.下载Hadoop安装包
官网地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
6.解压缩Hadoop安装包

要确保所有的操作都是在用户hadoop下完成的,所以将该hadoop文件夹的属主用户设为hadoop
命令:sudo chown -R hadoop:hadoop hadoop
7.安装Java

8.配置Hadoop中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的文件均位于/usr/local/hadoop/etc/hadoop下面,具体需要的配置如下:
① core-site.xml 配置如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
② mapred-site.xml.template配置如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
③ hdfs-site.xml配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop-env.sh里面,具体如下:
export JAVA_HOME="/usr/local/jdk1.8.0_91"
9.运行Hadoop
① 初始化HDFS系统
命令:bin/hdfs namenode -format
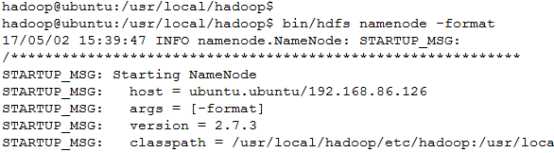
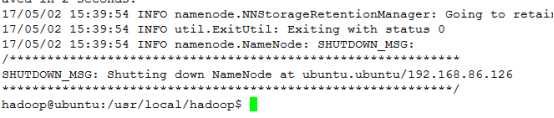
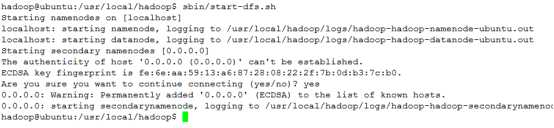
② 开启NameNode和DataNode守护进程
命令:sbin/start-dfs.sh,成功如下:
③ 查看进程信息
命令:jps
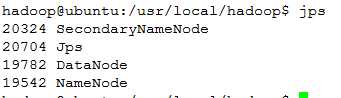
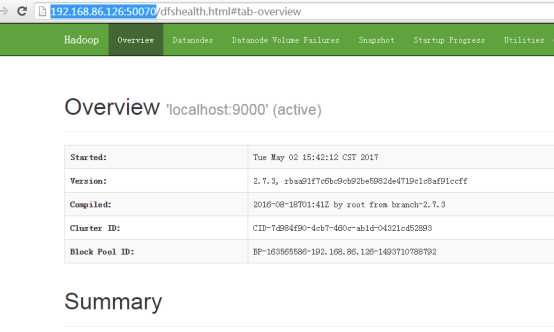
④ 查看Web UI
在浏览器输入http://192.168.86.126:50070/
10.运行WordCount Demo
① 在本地新建一个文件,在/home/download/wangling目录下新建了一个words文档,里面的内容可以随便填写。此words里写的如下:
quux labs foo bar quux
② 在HDFS中新建一个文件夹,用于上传本地的words文档,在hadoop目录下输入如下命令:
命令:bin/hdfs dfs -mkdir /test,表示在hdfs的根目录下建立了一个test目录
使用如下命令可以查看HDFS根目录下的目录结构
命令:bin/hdfs dfs -ls /

③ 将本地words文档上传到test目录中
命令:bin/hdfs dfs -put /home/download/wangling/words /test/

表示已经将本地的words文档上传到了test目录下了。
④ 运行wordcount
命令:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/words /test/out
运行完成后,在/test目录下生成名为out的文件
查看命令:bin/hdfs dfs -ls /test

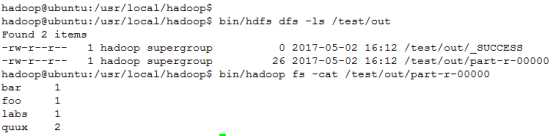
⑤ 查看运行结果
命令:bin/hdfs dfs -ls /test/out
bin/hadoop fs -cat /test/out/part-r-00000
标签:bin config abs 技术分享 ora open ubuntu file hdfs
原文地址:http://www.cnblogs.com/lingwang3/p/6820779.html