标签:uil lte cci b-tree drop dex 升级 提升 维护
SQL Server 自2012以来引入了列存储的概念,至今2016对列存储的支持已经是非常友好了。由于我这边线上环境主要是2014,所以本文是以2014为基础的SQL Server 的列存储的介绍。下面我们主要看一下列存储的发展以及一些原理:
列存储的开发是想要处理超大量数据进行分析计算,于是在SQL Server 2012时,SQL Server 引入了列存储索引,用以显著提供高传统数据仓库类型语句的性能,并在SQL Server 2014中做了进一步加强。列存储会将一个列的数据单独存放在一起,所以主要会有以下两个优点。
1:同一个列中的数据的相似性比较高,因此压缩比例会更高。磁盘操作时,磁盘的IO也会相应的降低。当然,当压缩的数据读取到内存后解压会需要额外的CPU。
2:由于数据是按照列进行存储和读取的,因此如果某些列在访问中并不需要,那么实际的操作时也会不访问这些列,那么磁盘IO会进一步降低。
3:由于数据是按照列进行存储和读取的,大批量的数据聚合访问等会较以往的行存储更快。
对于列存储来说,主要来说就是数据仓库这个使用场景了,微软最近几年也是在这个方面频频发力。对于数据仓库来说,CPU,内存,磁盘都可能称为性能的瓶颈,但是我们指导磁盘的操作来说相比内存和CPU性能是最慢的,而列存储恰恰是对IO的性能提升是很大的,列存储会减少磁盘的IO操作,提升运算的效率,特别是大量数据的聚合。当然如果是一些线上的精确查找等操作,列存储并不是最好的选择。
对于这些性能的提升和存储 空间的优化,主要是和列存储的实现原理是分不开的(由于非聚集列存储的功能比较鸡肋,我们就不介绍了,因为有非聚集列存储的表成为了一个只读表):
1:Clustered columnstore inde – 整个表都按照列存储进行组织,直接替代了传统的堆表或者聚集索引,可以自由的进行增删改操作。
2:聚集列存储索引虽然相对于非聚集列存储索引在column store这块组织架构基本一样,但是它可以进行增删改操作。原因是它多了一块或者多块行存储部分,这部分称之为delta tore。
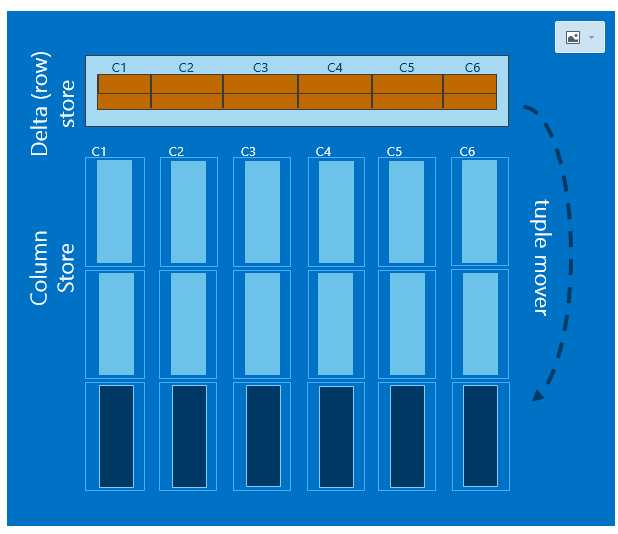
原理大概看完之后,下面给出SQL Server2014对列存储的改进:
● 支持数据的读和写
● 在打破了数据只读的限制后,列存储索引使用的范围和场景大大增加
● 相比传统的ad-hoc的增删改操作,在SQL Server2014还是推荐使用bulk insert和分区交换来进行大批次数据的更新,效率更高,维护成本也会降低
● 支持更多的数据类型
● 添加了更多的数据类型支持:(n)varchar(max), varbinary(max), XML, Spatial, CLR
● 基本说来,SQL Server2014的列存储支持所有的non-blob数据类型
● 整个表可建立并且只能建立一个聚集列存储索引。传统的行存储会需要非聚集索引帮助提高访问效率,但是列存储无需这样。并且由于只有一份数据,因此存储需要的磁盘空间大大降低
● 非聚集列索引仍然支持,并且还是只读的结构。
当我们有了聚集列存储索引后,就不需要非聚集列索引了,因为此时所有的数据都是按照列存储了。但是如果表上需要添加Constraints或者工作负载仍然需要B-tree形式的非聚集索引,那么我们还是只能考虑使用非聚集列存储索引。
● 语句的执行上有以下改进
○ 基于矢量的计算方式得到改
○ 支持更多的语法
■ 所有的join方式(包括OUTER, HASH, SEMI (NOT IN, IN)
■ UNION ALL
■ Scalar aggregates
■ “Mixed mode” plans
● 对bitmap和spill操作有进一步的改进
● 对hash join有所改进
其实我在SQL Server 2014列存储的实践当中,还发现有几个不是非常友好的地方
1:SQL Server 2014聚集列存储并不支持视图功能,这个还是比较坑的,因为列存储的主要应用场景就是数据仓库,有很多视图来说要提供报表或者提供给报表部门查询权限,通过视图能够隐藏很多敏感信息,而不支持视图就会很难做决定来具体修改为列存储了
2:SQL Server 2014聚集列存储并不支持alwayson从库的查询
3:SQL Server 2014 12.0.2版本对列存储有漏洞,alwayson日志同步的时候容易造成内部锁争用,影响主从的同步,这点功能我们可能要升级SP1补丁才能解决,我这边从库升级后至今没有出现这个问题,这也是SQL Server 2014列存储的一个BUG吧
以上也算是在生产环境走过的坑,因为考虑不是很周全走了不少路。希望大家能够引以为戒。除了以上几个坑以外,列存储还不支持以下的功能:
在列存储索引中不可使用以下数据类型:
binary(n)、varbinary(n)(在2014及更高版本中允许使用,但不包括varbinary(max)),image、text、ntext、varchar(max)、nvarchar(max),sql_variant,xml
只能通过删除及创建索引的方式重建索引,而不可使用ALTER INDEX命令
在视图或索引视图中无法使用列存储索引
列存储索引无法结合使用以下特性:分发,变更数据捕获,变更追踪,Filestream
列存储索引不可包含多于1024个列
对应的表不可包含唯一性约束、主键约束或外键约束
接下来我们看一下列存储的一些实践:
1:创建列存储的表
CREATE TABLE maxiangqian( id [int] NOT NULL, age [int] NOT NULL, sex [tinyint] NOT NULL, name varchar(20)); GO CREATE CLUSTERED COLUMNSTORE INDEX cci_Simple ON maxiangqian; GO :
2:行聚集索引转换为列存储:
CREATE TABLE maxiangqian( id [int] NOT NULL, age [int] NOT NULL, sex [tinyint] NOT NULL, name varchar(20)); GO CREATE CLUSTERED INDEX cl_simple ON maxiangqian (id); GO CREATE CLUSTERED COLUMNSTORE INDEX cl_simple ON maxiangqian WITH (DROP_EXISTING = ON);
或者说我们也可以直接删除聚集索引,然后再
CREATE CLUSTERED COLUMNSTORE INDEX cl_simple ON maxiangqian
效果是一样一样的。
3 将一个堆表转化为列存储表:
第一步就是删除堆表现有的索引,然后创建聚集列存储索引:
CREATE TABLE maxiangqian( id [int] NOT NULL, age [int] NOT NULL, sex [tinyint] NOT NULL, name varchar(20)); GO create index pid on maxiagnqian(id) drop index pid on maxiangqian CREATE CLUSTERED COLUMNSTORE INDEX cci_Simple ON maxiangqian; GO :
上面基本上已经满足你建立列存储的一些功能,下面我们看一下怎么把一个聚集列存储的表转化为普通表:
CREATE CLUSTERED INDEX pid ON maxiangqian WITH ( DROP EXISTING = ON ); 或者 DROP INDEX cci_Simple ON MyFactTable;
OK,我们基本上已经可以知道怎么创建列存储索引了
但是我们指导由于列存储删除的时候只是标记,所以说列存储如果经常更新删除,碎片还是会很大的,下面我们看下怎么消除碎片---重建:
CREATE CLUSTERED COLUMNSTORE INDEX cci_Simple ON maxiagnqian WITH ( DROP_EXISTING = ON ); ALTER INDEX cci_Simple ON maxiangqian REBUILD PARTITION = ALL WITH ( DROP_EXISTING = ON );
以上两种方式是都可以实现的。
其实对于列存储来说,卧铺,我这边给我比较大的惊喜就是磁盘空间的节约,列存储的压缩比例可以达到10:1甚至15:1,而且相对来说对于我数据仓库一些大批量的聚合操作性能提升。在节省空间又提高性能的情况下,你还有什么理由不选用列存储呢。
标签:uil lte cci b-tree drop dex 升级 提升 维护
原文地址:http://www.cnblogs.com/shengdimaya/p/6824349.html