标签:bat 方程组 get output learn 比较 结束 符号 局部最优
先是几个英文:
linear regression线性回归 gradient descent梯度下降 normal equations正规方程组
notation符号:
m denote(指示) the number of training examples
x denote the input variables(also called features)
y denote the output variables(also called target variables)
(x,y) training example
第i行training example (x^(i),y^(i))
n denote features的数量
比如根据房子大小判断房子价钱这个例子,有m个例子就是说有m个(x,y)数据,如果x不止一个,就是说我们还要根据房子的位置啊,房间个数等特征来判断房子价钱,那么这个n就是这些特征的数量。x1是size,x2是beddrooms,那么n=2
开始算法:
现在有一个学习函数h,要使得h(x)能符合结果Y,h(x)可以用下面这样的式子来表示:
![]()
θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
又另![]() (这个1/2就记一下吧,前面乘上的1/2是为了在求导的时候,这个系数就不见了。)
(这个1/2就记一下吧,前面乘上的1/2是为了在求导的时候,这个系数就不见了。)
好的现在我们要让J(Θ)最小对吧。
gradient descent:就是想象你在下山,你要最最陡下降最快的那条路到达山底(J(Θ)最小值),所以这里要求个偏导。
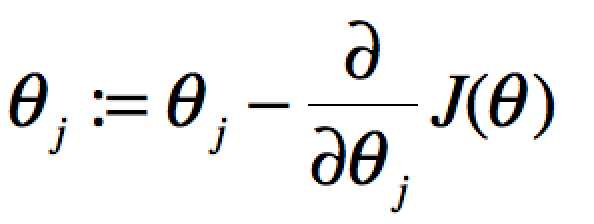
当单个特征值时,上式中j表示系数(权重)的编号,右边的值赋值给左边θj从而完成一次迭代。
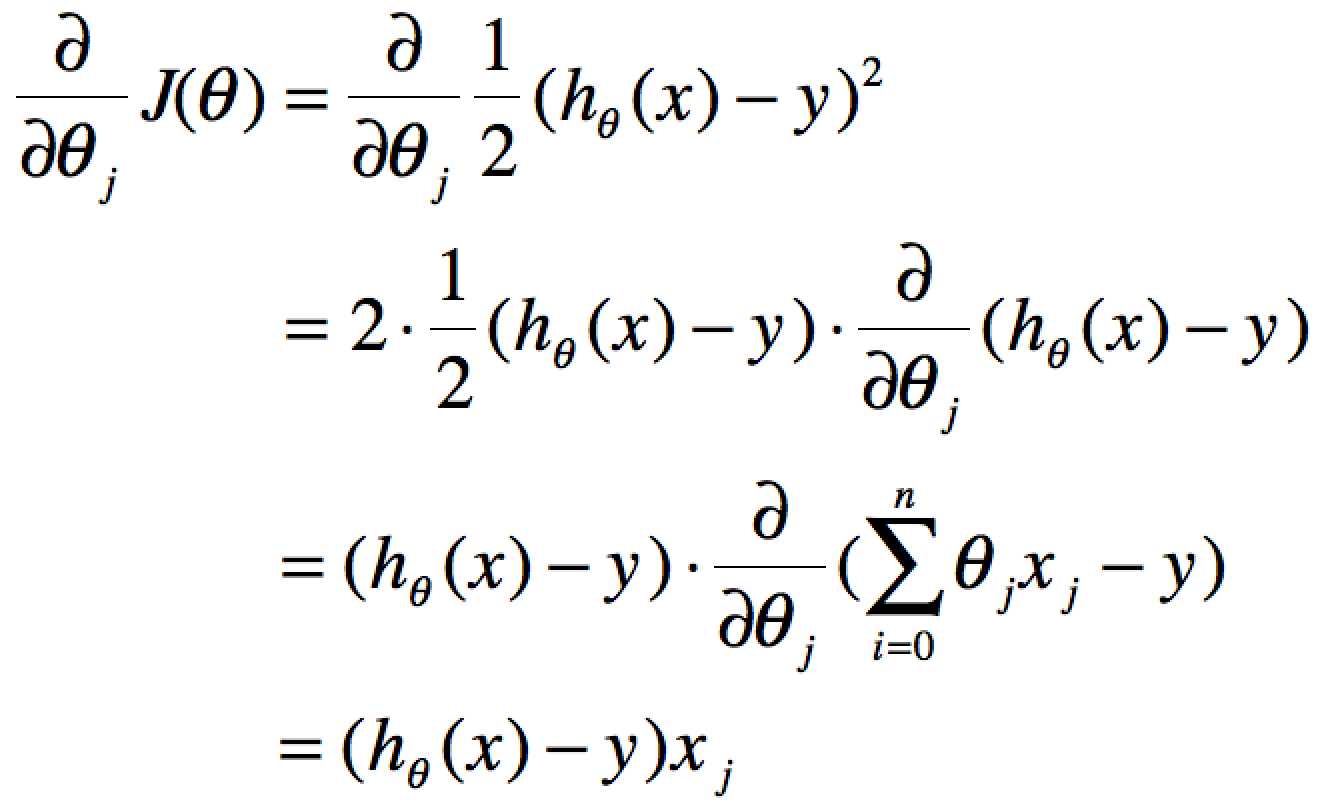
单个特征的迭代如下:
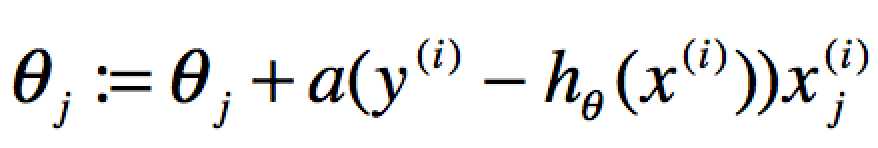
多个特征的迭代如下:
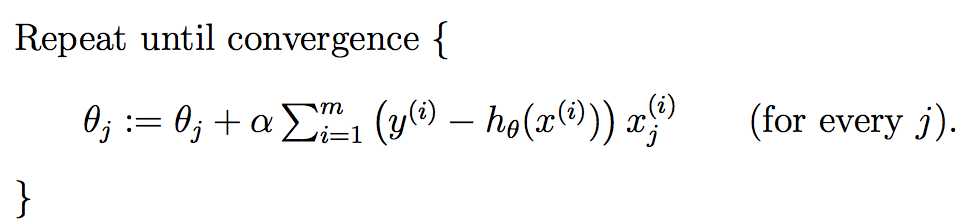
上式就是批梯度下降算法(batch gradient descent),当上式收敛时则退出迭代,何为收敛,即前后两次迭代的值不再发生变化了。一般情况下,会设置一个具体的参数,当前后两次迭代差值小于该参数时候结束迭代。注意以下几点:
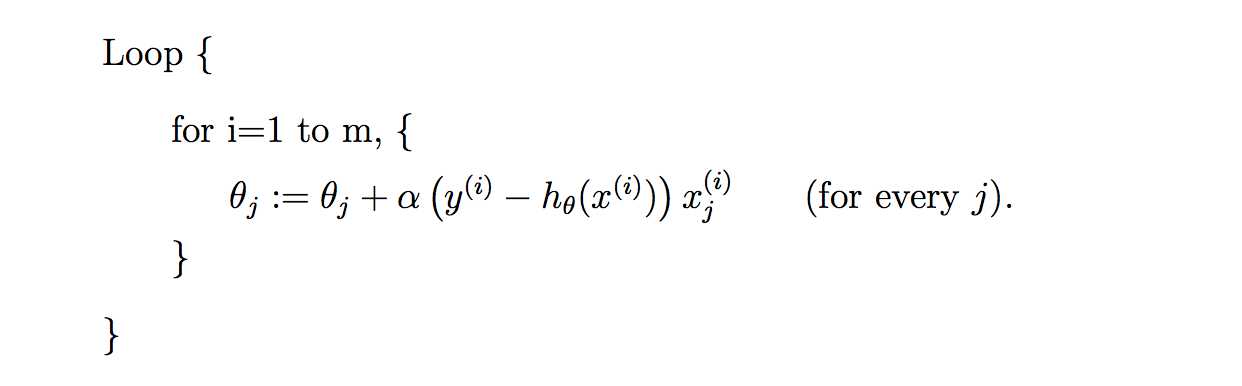
这里整个算法才用了j个training examples
标签:bat 方程组 get output learn 比较 结束 符号 局部最优
原文地址:http://www.cnblogs.com/wangshen31/p/6822560.html