标签:getname 线程变量 设置 .com 支持 生成 ret list ==
操作系统进程切换:
1 出现IO操作:
2 固定时间:
进程就是一个程序在一个数据集上的一次动态执行过程,进程一般由程序、数据集、进程控制块三部分组成。
实现并发过程
进程是相互独立的。
线程的出现是为了降低上下文切换的消耗,提供系统的并发性,并突破一个进程只能干一样的缺陷,使到进程内并发成为可能。
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配
和调度的基本单位,是操作系统结构的基础
线程则是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位
进程与线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源
(3)CPU分给线程,即真正在CPU上运行的是线程
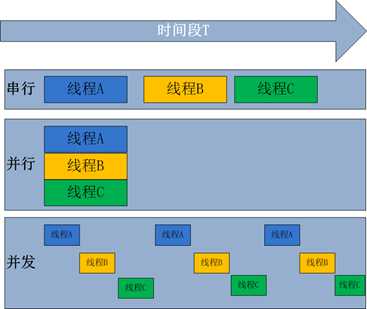
并行处理(Parallel Processing)
是计算机系统中能同时执行两个或更多个处理的一种计算方法。并行处理可同时工作与统一程序的不同方面。并行处理的主要目的是节省大型和复杂问题的解决时间
并发处理(concurrency Processing)
指一个时间段中有几个程序处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机(CPU)上运行
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力,所以说,并行是并发的子集
注意:
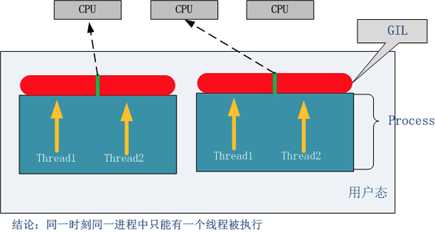
Python败笔多线程:由于GIL,导致同一时刻,同一进程只能有一个线程被运行。多进程可以并行,多线程不能并行。
同步:在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去
异步:是指进程不需要一直等待下去,而是继续执行面的操作,不管其他进程的状态,当有消息返回时系统会通知进程进行处理
Thread类执行创建:
import threading
import time
def listen():
print("listen to the music")
time.sleep(3)
print("listne stop")
def write():
print("writing blog")
time.sleep(5)
print("writing stop")
t1=threading.Thread(target=listen) #生成一条线程
t2=threading.Thread(target=write) #生成第二条线程
t1.start() #启动线程
t2.start()
print("ending") #主线程
执行效果:
listen to the music
writing blog
ending
listne stop
writing stop
Thread类继承式创建:
import threading
import time
class Mythread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num=num
def run(self):
print("running on number:%s"%self.num)
time.sleep(3)
t1=Mythread(56)
t2=Mythread(73)
t1.start()
t2.start()
print("ending")
执行结果:
running on number:56
running on number:73
ending
Thread类的实例方法:
Join()
t.join() : 线程对象t未执行完,会阻塞你的主线程。跟子线程没有关系
import threading
import time
from time import ctime,sleep
def Music(name):
print("Begin listening to {name}".format(name=name,time=ctime()))
sleep(3)
print("end listenting{time}".format(time=ctime()))
def Blog(title):
print("Begin recording the {title}".format(title=title,time=ctime ()))
sleep(5)
print("end recording the {time}".format(time=ctime()))
threads=[]
t1=threading.Thread(target=Music,args=("FILL ME",))
t2=threading.Thread(target=Blog,args=("python",))
threads.append(t1)
threads.append(t2)
if __name__ == ‘__main__‘:
for t in threads:
t.start()
# t.join() # 最后出现主程序 等t1 t2执行完之后
# t1.join() #t1线程不结束 其他线程不能执行 先执行t1,t2 然后在执行t1结束之后再执行主线程
t2.join() #t1 t2执行完之后再打印主程序
print("all over %s" %ctime())
setDeamon(True)
将线程声明为守护线程,必须在start()方法调用之前设置,如果不设置为守护线程程序会被无限挂起。
当我们在程序运行中,执行一个主线程,如果主线程有创建一个子线程 就兵分两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成,如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以用setDeamon方法啦
import threading
import time
from time import ctime,sleep
def Music(name):
print("Begin listening to {name}".format(name=name,time=ctime()))
sleep(3)
print("end listenting{time}".format(time=ctime()))
def Blog(title):
print("Begin recording the {title}".format(title=title,time=ctime ()))
sleep(5)
print("end recording the {time}".format(time=ctime()))
threads=[]
t1=threading.Thread(target=Music,args=("FILL ME",))
t2=threading.Thread(target=Blog,args=("python",))
threads.append(t1)
threads.append(t2)
if __name__ == ‘__main__‘:
# 守护线程跟着主线程走,t1 t2两个都设置为守护线程,主线程执行完 其他就都不执行
# t1.setDaemon(True) #把t1设置为守护线程,等待t2执行结束,但是t1也需要执行,正常执行
t2.setDaemon(True) #把t2设置为守护线程,主线程结束,t2也就跟着结束,不执行
for t in threads: #for遍历
t.start()
print("all over %s" %ctime())
其他方法:
Thread实例对象的方法
isAlive():返回线程是否活动的
getName():返回线程名
setName():设置线程名
threading模块提供的一些方法:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate():返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount():返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
Python中的线程是操作系统的原生线程,python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所有引入了GIL。
加在C python解释其上,为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。
GIL:在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等他它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。
在调用任何Python C API之前,要先获得GIL
GIL缺点:多处理器退化为单处理器;优先:避免大量的加解锁操作
GIL的影响
无论你启多个线程,你有多少个cpu,Python在执行一个进程的时候会谈定的在同一时刻只允许一个线程运行。
所有,python是无法利用多核CPU实现多线程的
这样,python对于计算机密型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
import time
def cal(n):
sum=0
for i in range(n):
sum+=i
s=time.time()
# import threading
# t1=threading.Thread(target=cal,args=(10000000,))
# t2=threading.Thread(target=cal,args=(10000000,))
#
# t1.start()
# t2.start()
# t1.join()
# t2.join()
# # time 10.940000057220459
# # time 1.1090002059936523
cal(10000000)
cal(10000000)
print("time",time.time()-s)
# time 10.986999750137329
# time 1.128000020980835
计算密集型:一直在使用CPU
IO:存在大量IO操作
总结:对于计算密集型任务:Python的多线程并没有用
对于IO密集型任务:Python的多线程是有意义的
Python使用多核:开进程,弊端:开销大而且切换复杂
标签:getname 线程变量 设置 .com 支持 生成 ret list ==
原文地址:http://www.cnblogs.com/niejinmei/p/6827074.html