标签:disabled for setting dex either value 字符 div ctf
Lucene索引的一个特点就filed,索引以field组合。这一特点为索引和搜索提供了很大的灵活性。elasticsearch则在Lucene的基础上更近一步,它可以是 no scheme。实现这一功能的秘密就Mapping。Mapping是对索引各个字段的一种预设,包括索引与分词方式,是否存储等,数据根据字段名在Mapping中找到对应的配置,建立索引。这里将对Mapping的实现结构简单分析,Mapping的放置、更新、应用会在后面的索引fenx中进行说明。
首先看一下Mapping的实现关系结构,如下图所示:
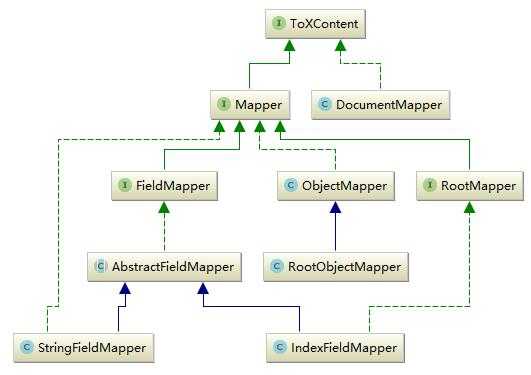
这只是Mapping中的一部分内容。Mapping扩展了lucene的filed,定义了更多的field类型既有Lucene所拥有的string,number等字段又有date,IP,byte及geo的相关字段,这也是es的强大之处。如上图所示,可以分为两类,mapper与documentmapper,前者是所有mapper的父接口。而DocumentMapper则是Mapper的集合,它代表了一个索引的mapper定义。
Mapper的有三类,第一类就是核心field结构FileMapper—>AbstractFieldMapper—>StringField这种核心数据类型,它代表了一类数据类型,如字符串类型,int类型这种;第二类是Mapper—>ObjectMapper—>RootObjectMapper,object类型的Mapper,这也是elasticsearch对lucene的一大改进,不想lucene之支持基本数据类型;最后一类是Mapper—>RootMapper—>IndexFieldMapper这种类型,只存在于根Mapper中的一种Mapper,如IdFieldMapper及图上的IndexFieldMapper,它们类似于index的元数据,只可能存在于某个index内部。
Mapper中一个比较重要的方法就是parse(ParseContext context),Mapper的子类对这个方法都有各自的实现。它的主要功能是通过解析ParseContext获取到对应的field,这个方法主要用于建立索引时。索引数据被继续成parsecontext,每个field解析parseContext构建对应的lucene Field。它在AbstractFieldMapper中的实现如下所示:
public void parse(ParseContext context) throws IOException { final List<Field> fields = new ArrayList<>(2); try { parseCreateField(context, fields);//实际Filed解析方法 for (Field field : fields) { if (!customBoost()) {//设置boost field.setBoost(boost); } if (context.listener().beforeFieldAdded(this, field, context)) { context.doc().add(field);//将解析完成的Field加入到context中 } } } catch (Exception e) { throw new MapperParsingException("failed to parse [" + names.fullName() + "]", e); } multiFields.parse(this, context);//进行mutiFields解析,MultiFields作用是对同一个field做不同的定义,如可以进行不同分词方式的索引这样便于通过各种方式查询 if (copyTo != null) { copyTo.parse(context); } }
这里的parseCreateField是一个抽象方法,每种数据类型都有自己的实现,如string的实现方式如下所示:
protected void parseCreateField(ParseContext context, List<Field> fields) throws IOException { ValueAndBoost valueAndBoost = parseCreateFieldForString(context, nullValue, boost);//解析成值和boost if (valueAndBoost.value() == null) { return; } if (ignoreAbove > 0 && valueAndBoost.value().length() > ignoreAbove) { return; } if (context.includeInAll(includeInAll, this)) { context.allEntries().addText(names.fullName(), valueAndBoost.value(), valueAndBoost.boost()); } if (fieldType.indexed() || fieldType.stored()) {//构建LuceneField Field field = new Field(names.indexName(), valueAndBoost.value(), fieldType); field.setBoost(valueAndBoost.boost()); fields.add(field); } if (hasDocValues()) { fields.add(new SortedSetDocValuesField(names.indexName(), new BytesRef(valueAndBoost.value()))); } if (fields.isEmpty()) { context.ignoredValue(names.indexName(), valueAndBoost.value()); } }
//解析出字段的值和boost public static ValueAndBoost parseCreateFieldForString(ParseContext context, String nullValue, float defaultBoost) throws IOException { if (context.externalValueSet()) { return new ValueAndBoost((String) context.externalValue(), defaultBoost); } XContentParser parser = context.parser(); if (parser.currentToken() == XContentParser.Token.VALUE_NULL) { return new ValueAndBoost(nullValue, defaultBoost); } if (parser.currentToken() == XContentParser.Token.START_OBJECT) { XContentParser.Token token; String currentFieldName = null; String value = nullValue; float boost = defaultBoost; while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) { if (token == XContentParser.Token.FIELD_NAME) { currentFieldName = parser.currentName(); } else { if ("value".equals(currentFieldName) || "_value".equals(currentFieldName)) { value = parser.textOrNull(); } else if ("boost".equals(currentFieldName) || "_boost".equals(currentFieldName)) { boost = parser.floatValue(); } else { throw new ElasticsearchIllegalArgumentException("unknown property [" + currentFieldName + "]"); } } } return new ValueAndBoost(value, boost); } return new ValueAndBoost(parser.textOrNull(), defaultBoost); }
以上就是Mapper如何将一个值解析成对应的Field的过程,这里只是简单介绍,后面会有详细分析。
DocumentMapper是一个索引所有Mapper的集合,它表述了一个索引所有field的定义,可以说是lucene的Document的定义,同时它还包含以下index的默认值,如index和search时默认分词器。它的部分Field如下所示:
private final DocumentMapperParser docMapperParser; private volatile ImmutableMap<String, Object> meta; private volatile CompressedString mappingSource; private final RootObjectMapper rootObjectMapper; private final ImmutableMap<Class<? extends RootMapper>, RootMapper> rootMappers; private final RootMapper[] rootMappersOrdered; private final RootMapper[] rootMappersNotIncludedInObject; private final NamedAnalyzer indexAnalyzer; private final NamedAnalyzer searchAnalyzer; private final NamedAnalyzer searchQuoteAnalyzer;
DocumentMapper的功能也体现在parse方法上,它的作用是解析整条数据。之前在Mapper中看到了Field是如何解析出来的,那其实是在DocumentMapper解析之后。index请求发过来的整条数据在这里被解析出Field,查找Mapping中对应的Field设置,交给它去解析。如果没有且运行动态添加,es则会根据值自动创建一个Field同时更新Mapping。方法代码如下所示:
public ParsedDocument parse(SourceToParse source, @Nullable ParseListener listener) throws MapperParsingException { ParseContext.InternalParseContext context = cache.get(); if (source.type() != null && !source.type().equals(this.type)) { throw new MapperParsingException("Type mismatch, provide type [" + source.type() + "] but mapper is of type [" + this.type + "]"); } source.type(this.type); XContentParser parser = source.parser(); try { if (parser == null) { parser = XContentHelper.createParser(source.source()); } if (sourceTransforms != null) { parser = transform(parser); } context.reset(parser, new ParseContext.Document(), source, listener); // will result in START_OBJECT int countDownTokens = 0; XContentParser.Token token = parser.nextToken(); if (token != XContentParser.Token.START_OBJECT) { throw new MapperParsingException("Malformed content, must start with an object"); } boolean emptyDoc = false; token = parser.nextToken(); if (token == XContentParser.Token.END_OBJECT) { // empty doc, we can handle it... emptyDoc = true; } else if (token != XContentParser.Token.FIELD_NAME) { throw new MapperParsingException("Malformed content, after first object, either the type field or the actual properties should exist"); } // first field is the same as the type, this might be because the // type is provided, and the object exists within it or because // there is a valid field that by chance is named as the type. // Because of this, by default wrapping a document in a type is // disabled, but can be enabled by setting // index.mapping.allow_type_wrapper to true if (type.equals(parser.currentName()) && indexSettings.getAsBoolean(ALLOW_TYPE_WRAPPER, false)) { parser.nextToken(); countDownTokens++; } for (RootMapper rootMapper : rootMappersOrdered) { rootMapper.preParse(context); } if (!emptyDoc) { rootObjectMapper.parse(context); } for (int i = 0; i < countDownTokens; i++) { parser.nextToken(); } for (RootMapper rootMapper : rootMappersOrdered) { rootMapper.postParse(context); } } catch (Throwable e) { // if its already a mapper parsing exception, no need to wrap it... if (e instanceof MapperParsingException) { throw (MapperParsingException) e; } // Throw a more meaningful message if the document is empty. if (source.source() != null && source.source().length() == 0) { throw new MapperParsingException("failed to parse, document is empty"); } throw new MapperParsingException("failed to parse", e); } finally { // only close the parser when its not provided externally if (source.parser() == null && parser != null) { parser.close(); } } // reverse the order of docs for nested docs support, parent should be last if (context.docs().size() > 1) { Collections.reverse(context.docs()); } // apply doc boost if (context.docBoost() != 1.0f) { Set<String> encounteredFields = Sets.newHashSet(); for (ParseContext.Document doc : context.docs()) { encounteredFields.clear(); for (IndexableField field : doc) { if (field.fieldType().indexed() && !field.fieldType().omitNorms()) { if (!encounteredFields.contains(field.name())) { ((Field) field).setBoost(context.docBoost() * field.boost()); encounteredFields.add(field.name()); } } } } } ParsedDocument doc = new ParsedDocument(context.uid(), context.version(), context.id(), context.type(), source.routing(), source.timestamp(), source.ttl(), context.docs(), context.analyzer(), context.source(), context.mappingsModified()).parent(source.parent()); // reset the context to free up memory context.reset(null, null, null, null); return doc; }
将整条数据解析成ParsedDocument,解析后的数据才能进行后面的Field解析建立索引。
总结:以上就是Mapping的结构和相关功能概括,Mapper赋予了elasticsearch索引的更强大功能,使得索引和搜索可以支持更多数据类型,灵活性更高。
标签:disabled for setting dex either value 字符 div ctf
原文地址:http://www.cnblogs.com/zziawanblog/p/6828490.html