标签:des style blog http color 使用 strong ar 数据
以前都是使用mysql和oracle,对sqlserver的使用不多。最近因项目原因,要读取其他项目的数据库,取出某个门的开关历史记录,而对方使用的是sqlserver,所以研究起了sqlserver的分页,经过几次实践,慢慢的从低效的分页写到了高效的分页。
history表
历史记录ID:id(唯一引索)
操作时间:time
开门或关门:flag
由谁操作:user_Id
属于哪个设备:device_id
下面我们先介绍四种分页的方法,以【一种低效】——【两种较高效】——【一种高效】的顺序进阶的介绍,在最后再附上测试结果。
思路:

最里层:先从history表根据时间倒序查出前50010条记录
中间层:从以上的查询结果中根据时间正序查出前10条记录,一正一反刚好就拿出了第10000条到10010条记录了。
最外层:根据时间倒序拿出以上的查询结果
SQL代码:
select * from ( select top 10 * from ( select top 50010 * from history order by time desc ) h order by h.time asc ) hh order by hh.time desc
经下面的检验,这种查询效率比较低下。
其原因是因为每一层的查询都使用了select * ,即扫描所有的这段,但是 “最里层” 和 “中间层” 根本就没必要select * ,这两层目的只是为了把最后一层的搜索范围定位在第10000-10010条之间,所以,在这两层里,我们只要拿出关键字ID和排序字段time就好。
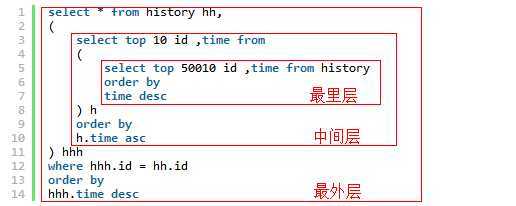
最里层:先从history表根据时间倒序查出前50010条记录,只拿出id和time
中间层:从以上的查询结果中根据时间正序查出前10条记录,只拿出id和time,一正一反刚好就拿出了第10000条到10010条记录了。
最外层:根据时间倒序拿出以上的查询结果,select *拿出所有字段,查询范围用where ... = ... 来匹配。
SQL代码:
select * from history hh, ( select top 10 id ,time from ( select top 50010 id ,time from history order by time desc ) h order by h.time asc ) hhh where hhh.id = hh.id order by hhh.time desc
经检验,这种分页 方法比上一种快一点点。
主要原因在与“最里层”和“中间层”的两次查询,都只是查出id和time,而不是select * ,从这个角度讲提升了效率。但最后又用了where...=语法,比起上一种分页方法,又降低了一点效率。但是where...=语法速度很快,所以总体上还是这种分页方法更快一些。
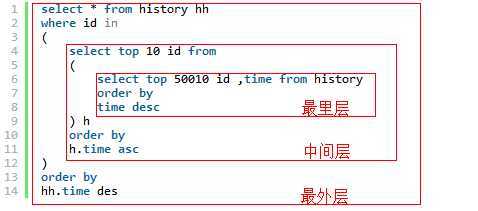
最里层:先从history表根据时间倒序查出前50010条记录,只拿出id和time
中间层:从以上的查询结果中根据时间正序查出前10条记录,只拿出id和time,一正一反刚好就拿出了第10000条到10010条记录了。
最外层:根据时间倒序拿出以上的查询结果,select *拿出所有字段,查询范围用where...in ()来匹配
SQL代码:
select * from history hh where id in ( select top 10 id from ( select top 50010 id ,time from history order by time desc ) h order by h.time asc ) order by hh.time des
这种分页方法,与上一种分页方法比起来,区别是这种使用了where...in(),而不是where...=,原理上差别不大,但可能是SQLServer内部优化的原因,使用where...in比使用where...=要快一些。具体在下面的计较表格可以看出。
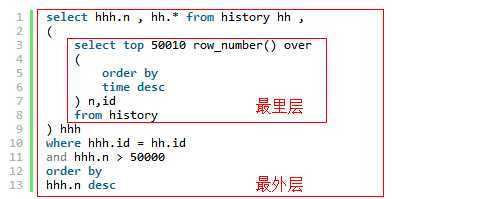
最里层:查询出前50010条数据,只拿出ID字段,同时使用row_number() over 语法,增加一个n字段,代表该条数据时第几行。
最外层:根据where...=来匹配id,同时直接拿出 n>50000 的数据。
SQL代码:
select hhh.n , hh.* from history hh , ( select top 50010 row_number() over ( order by time desc ) n,id from history ) hhh where hhh.id = hh.id and hhh.n > 50000 order by hhh.n desc
这种分页方法,首先只是两次查询,这无非提高了效率。最里层查询出来的“虚列”——n,sqlserver不知道会不会为其加上索引,个人认为会,但想不出什么验证的方法。假如有加入索引的话,那在这个地方,使用 “n >某个数字” 的查询方法,又比前几次查询快了一点。
以下进行两种测试,第一种是查询出1000-1010条数据,第二种是查询出第50000-50010条数据。记录的秒数是查询50次总共的用时,每组测试5次,最后取平均值。
| 【查询1000-1010条数据】 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 |
| 低效的分页 | 6.344s | 5.687s | 5.797s | 5.704s | 5.641s | 5.835s |
| 较高效的分页(1)——where...= | 4.485s | 5.281s | 5.094s | 5.281s | 5.313s | 5.091s(胜出) |
| 较高效的分页(1)——where...in | 5.093s | 5.328s | 5.14s | 5.406s | 5.297s | 5.253s |
| 高效的分页——row_number() over | 5.437s | 5.39s | 5.156s | 5.016s | 5.344s | 5.269 |
从中可以看出,在查询的行数较少时,使用“较高的分页(1)——where...=”是最快的一种分页方法。
| 【查询50000-50010条数据】 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 |
| 低效的分页 | 10.844s | 9.985s | 10.172s | 10.0s | 10.297s | 10.260s |
| 较高效的分页(1)——where...= | 9.625s | 9.469s | 9.14s | 9.171s | 9.219s | 9.325s |
| 较高效的分页(1)——where...in | 9.156s | 9.61s | 9.187s | 9.218s | 9.219s | 9.278s |
| 高效的分页——row_number() over | 7.844s | 6.765s | 6.422s | 7.359s | 6.875s | 7.053s(胜出) |
从中可用看出,在查询的行数较多时,使用"高效的分页——row_number() over"是最快的一种分页方法,而且快了好几个档次!
标签:des style blog http color 使用 strong ar 数据
原文地址:http://www.cnblogs.com/xiaoMzjm/p/3933077.html