标签:des blog http os 使用 io strong 文件 for
转自:http://blog.csdn.net/wyzxg/article/details/7700394
MySQL官网配置说明地址:http://dev.mysql.com/doc/refman/5.5/en/innodb-parameters.html
其他参考:
《高性能MySQL》 - 8.4.5 InnoDB缓冲池
《MySQL技术内幕InnoDB存储引擎》(第二版内容有所更新) - 2.3 InnoDB体系结构
##############################################
书中是先对后台线程进行说明,然后对内存部分进行说明,这样更好理解innoDB引擎内存池在使用时的过程。
【后台线程】
InnoDB有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作:
维护所有进程/线程需要访问的多个内部数据结构。
缓存磁盘上的数据,方便快速的读取,并且在对磁盘文件的数据进行修改之前在这里缓存。
重做日志(redo log)缓冲。
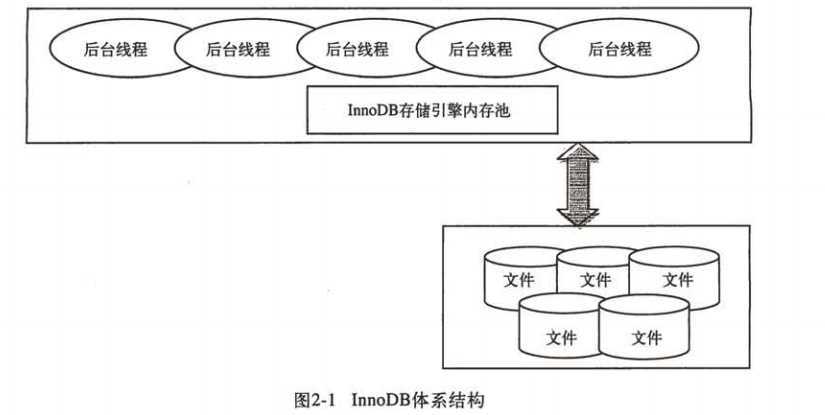
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据。此外,将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常情况下InnoDB能恢复到正常运行状态。
默认情况下,InnoDB存储引擎的后台线程有7个,4个IO thread,1个master thread,1个锁(lock)监控线程,1个错误监控线程。IO thread的数量由配置文件中的innodb_file_io_threads参数控制,默认为4,可以通过show engine innodb status \G查看IO thread,例如:

mysql> show engine innodb status \G *************************** 1. row *************************** Type: InnoDB Name: Status: ===================================== ... -------- FILE I/O -------- I/O thread 0 state: waiting for i/o request (insert buffer thread) I/O thread 1 state: waiting for i/o request (log thread) I/O thread 2 state: waiting for i/o request (read thread) I/O thread 3 state: waiting for i/o request (read thread) I/O thread 4 state: waiting for i/o request (read thread) I/O thread 5 state: waiting for i/o request (read thread) I/O thread 6 state: waiting for i/o request (write thread) I/O thread 7 state: waiting for i/o request (write thread) I/O thread 8 state: waiting for i/o request (write thread) I/O thread 9 state: waiting for i/o request (write thread)
可以看到上面IO线程中的四种分别是insert buffer thread、log thread、read thread、write thread。MySQL 5.5可以对IO thread的read thread、write thread的数量进行配置(下面彩图Memery-Disk结构图中Buffer Pool与Table.ibd中间的就是read thread、write thread),默认的read thread、write thread分别增大到4个,默认的insert buffer thread、log thread仍为一个线程,上面也是MySQL 5.5版本的配置,同时不再使用innodb_file_io_threads参数,而是分别使用innodb_read_io_thread和innodb_write_io_thread参数,此参数可根据CPU核数、磁盘IO性能进行调整,如果将read thread或write thread配置很大但实际服务器性能不能满足,会导致线程请求积压,反而会降低性能。
【内存】
InnoDB存储引擎内存由以下几个部分组成:缓冲池(buffer pool)、重做日志缓冲池(redo log buffer)以及额外的内存池(additional memory pool),分别由配置文件中的参数innodb_buffer_pool_size、innodb_log_buffer_size、innodb_additional_mem_pool_size的大小决定。
缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲(insert buffer),自适应哈希索引(adaptive hash index)、InnoDB存储的锁信息(lock info)、数据字典信息(data dictionary)等,缓冲池不仅有数据页和索引页,只是他们占缓冲池的很大部分,InnoDB存储引擎中内存的结构如下图:
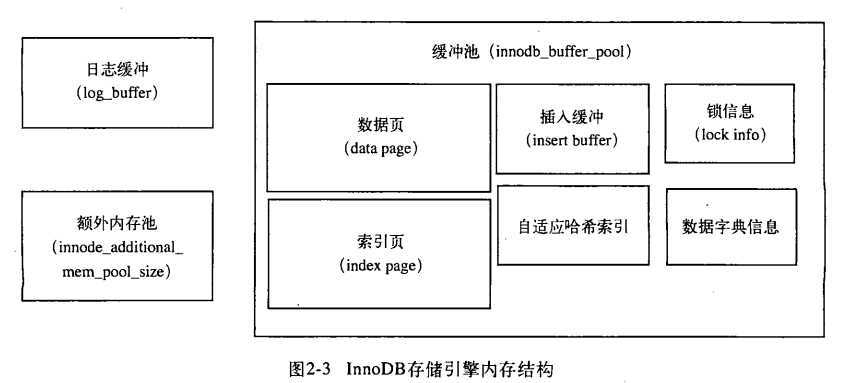
缓冲池是用来存放各种数据的缓冲,因为InnoDB的存储引擎的工作方式总是将数据库文件按页(每页16K)读取到缓冲池,然后按最近最少使用(LRU)的算法来保留在缓冲池中的缓存数据。如果数据库文件需要修改,总是首先修改在缓冲池中的页(发生修改后,该页即为脏页),然后再按照一定的频率将缓冲池的脏页刷新(flush)到文件。
通过show engine innodb status \G查看innodb_buffer_pool的具体使用情况(show engine innodb status查看的并非实时的innodb引擎状态,只是之前一段时间的平均值):
===================================== Per second averages calculated from the last 17 seconds ----------------- ... ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 52747567104; in additional pool allocated 0 Dictionary memory allocated 1147940 Buffer pool size 3145727 Free buffers 3143088 Database pages 2630 Old database pages 950 Modified db pages 0
buffer pool size表明一共有多少个缓冲帧(buffer frame),每个buffer frame为16K。free buffers表示当前空闲的缓冲帧,databases pages表示已经使用的缓冲帧,modified db pages表示脏页的数量。
日志缓冲将重做日志信息先放入这个缓冲区,然后按一定频率将其刷新到重做日志文件,该值一般不需要设置很大,因为一般情况下每一秒就会将重做日志缓冲刷新到日志文件,因此我们只需要保证每秒产生的事务量在innodb_log_buffer_size参数控制的缓冲大小之内即可。
额外的内存池通常被忽略,其实该值十分重要,在InnoDB存储引擎中,对内存的管理是通过一种称为内存堆(heap)的方式进行的。在对一些数据结构本身分配内存时,需要从额外内存池中申请,该区域的内存不够时,会从缓存池中申请。InnoDB实例会申请缓冲池(InnoDB_buffer_pool)的空间,但是每个缓冲池中的帧缓冲(frame buffer)还有对应的缓冲控制对象(buffer control block),而且这些对象记录了诸如LRU、锁、等待方面的信息,而这个对象的内存需要从额外内存池中申请。因此InnoDB缓冲池比较大时,额外内存池也应该增大。
##############################################
网上找到一个XtraDB/InnoDB内核结构图,XtraDB在某些点上对InnoDB做了优化,但是原理基本一样,原图是OSCHINA上面的,原图分辨率很低,大致结构和对应参数可以看清楚。
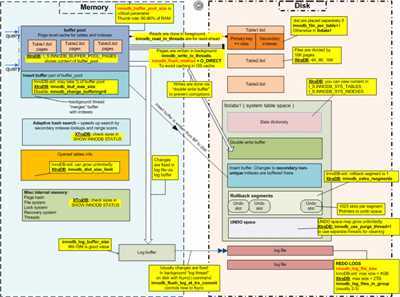
redo和undo,undo先于redo
redo可以理解为需要执行的操作语句备份,保证事务完整性,保存于ib_logfile
undo可以理解为数据受操作语句执行前的原始快照备份,用于rollback,保存于ibdata共享表空间
《MySQL技术内幕InnoDB存储引擎》 - 4.2.1 表空间
##############################################
对于启用了innodb_file_per_table的参数选项,需要注意的是,每张表的表空间内存放的只是数据、索引和插入缓冲,其他类的数据,如撤销(Undo)信息、系统事务信息、二次写缓冲(double write buffer)等还是存放在原来的共享表空间内。
##############################################
mysql buffer pool里的三种链表和三种page
buffer pool是通过三种list来管理的
1) free list
2) lru list
3) flush list
Buffer pool中的最小单位是page,在innodb中定义三种page
1) free page :此page未被使用,此种类型page位于free链表中
2) clean page:此page被使用,对应数据文件中的一个页面,但是页面没有被修改,此种类型page位于lru链表中
3) dirty page:此page被使用,对应数据文件中的一个页面,但是页面被修改过,此种类型page位于lru链表和flush链表中
Buffer pool flush list的工作原理
dirty page如何存在flush链表中?
在flush list中存在的page只能是dirty page,flush list中存在的dirty page是按着oldest_modification时间排序的,当页面访问/修改都被封装为一个mini-transaction,mini-transactin提交的时候,则mini-transaction涉及到的页面就进入了flush链表中,oldest_modification的值越大,说明page越晚被修改过,就排在flush链表的头部,oldest_modification的值越小,说明page越早被修改过,就排在flush链表的尾部,这样当flush链表做flush动作时,从flush链表的尾部开始scan,写出一定数量的dirty page到磁盘,推荐checkpoint点,使恢复的时间尽可能的短。除了flush链表本身的flush操作可以把dirty page从flush链表删除外,lru链表的flush操作也会让dirty page从flush链表删除。
Buffer pool lru list的工作原理
总的来说每当一个新页面被读取buffer pool之后,MySQL数据库InnoDB存储引擎都会判断当前buffer pool的free page是否足够,若不足,则尝试flush LRU链表。
在MySQL 5.6.2之前,用户线程在读入一个page (buf_read_page)、新建一个page(buf_page_create)、预读page(buf_read_ahead_linear) 等等操作时,都会在操作成功之后,调用buf_flush_free_margin函数,判断当前buffer pool是否有足够的free pages,若free pages不足,则进行LRU list flush,释放出足够的free pages,保证系统的可用性。
通过判断当前buf pool中需要flush多少dirty pages,才能够预留出足够的可被替换的页面(free pages or clean pages in LRU list tail)。
说明:
可用pages由以下两部分组成:
1. buf pool free list中的所有page,都是可以立即使用的。
2. buf pool LRU list尾部(5+2*BUF_READ_AHEAD_AREA)所有的clean pages。
其中:BUF_READ_AHEAD_AREA为64,是一个linear read ahead读取的大小,1 extent
由于buf_flush_free_margin函数是在用户线程中调用执行的,若需要flush LRU list,那么对于用户的响应时间有较大的影响。因此,在MySQL 5.6.2之后,InnoDB专门开辟了一个page cleaner线程,处理dirty page的flush动作(包括LRU list flush与flush list flush),降低page flush对于用户的影响。
在MySQL 5.6.2前后的版本中,LRU list flush的不同之处在于是由用户线程发起,还是有后台page cleaner线程发起。但是,无论是用户线程,还是后台page cleaner线程,再决定需要进行LRU list flush之后,都会调用buf_flush_LRU函数进行真正的flush操作。
不同之处在于,MySQL 5.6.2之前,用户线程调用的buf_flush_free_margin函数,在判断是否真正需要进行LRU list flush时,将LRU list tail部分的clean pages也归为可以被replace的pages,不需要flush。而在page cleaner线程中,每隔1s,无论如何都会进行一次LRU list flush调用,无论LRU list tail中的page是否clean。这也可以理解,用户线程,需要尽量降低flush的概率,提高用户响应;而后台线程,尽量进行flush尝试,释放足够的free pages,保证用户线程不会堵塞。
Buffer Pool LRU/Flush List flush对比
1).LRU list flush,由用户线程触发(MySQL 5.6.2之前);而Flush list flush由MySQL数据库InnoDB存储引擎后台srv_master线程处理。(在MySQL 5.6.2之后,都被迁移到page cleaner线程中)
2).LRU list flush,其目的是为了写出LRU 链表尾部的dirty page,释放足够的free pages,当buf pool满的时候,用户可以立即获得空闲页面,而不需要长时间等待;Flush list flush,其目的是推进Checkpoint LSN,使得InnoDB系统崩溃之后能够快速的恢复。
3).LRU list flush,其写出的dirty page,需要移动到LRU链表的尾部(MySQL 5.6.2之前版本);或者是直接从LRU链表中删除,移动到free list(MySQL 5.6.2之后版本)。Flush list flush,不需要移动page在LRU链表中的位置。
4).LRU list flush,由于可能是用户线程发起,已经持有其他的page latch,因此在LRU list flush中,不允许等待持有新的page latch,导致latch死锁;而Flush list flush由后台线程发起,未持有任何其他page latch,因此可以在flush时等待page latch。
5).LRU list flush,每次flush的dirty pages数量较少,基本固定,只要释放一定的free pages即可;Flush list flush,根据当前系统的更新繁忙程度,动态调整一次flush的dirty pages数量,量很大。
Buffer pool free list工作原理
free链表里存放的是空闲页面,初始化的时候申请一定数量的page,在使用的过程中,每次成功load页面到内存后,都会判断free page是否够用,如果不够用的话,就flush lru链表和flush链表来释放free page,这就可以满足其他进程在申请页面,使系统可用。
配置多个Buffer pool的innodb_buffer_pool_instances
官网说明 For systems with buffer pools in the multi-gigabyte range, dividing the buffer pool into separate instances can improve concurrency, by reducing contention as different threads read and write to cached pages. This feature is typically intended for systems with a buffer pool size in the multi-gigabyte range. Multiple buffer pool instances are configured using the innodb_buffer_pool_instances configuration option, and you might also adjust the innodb_buffer_pool_size value. When the InnoDB buffer pool is large, many data requests can be satisfied by retrieving from memory. You might encounter bottlenecks from multiple threads trying to access the buffer pool at once. You can enable multiple buffer pools to minimize this contention. Each page that is stored in or read from the buffer pool is assigned to one of the buffer pools randomly, using a hashing function. Each buffer pool manages its own free lists, flush lists, LRUs, and all other data structures connected to a buffer pool, and is protected by its own buffer pool mutex. To enable multiple buffer pool instances, set the innodb_buffer_pool_instances configuration option to a value greater than 1 (the default) up to 64 (the maximum). This option takes effect only when you set the innodb_buffer_pool_size to a size of 1 gigabyte or more. The total size you specify is divided among all the buffer pools. For best efficiency, specify a combination of innodb_buffer_pool_instances and innodb_buffer_pool_size so that each buffer pool instance is at least 1 gigabyte. 翻译: 对于使用较大Buffer Pool的实例,把Buffer Pool划分成多个独立的部分,可以提高并发性,减少不同的线程对缓存的页面读取与写入的竞争。这个配置通常用于Buffer Pool几GB或以上的数据量较大的实例。将Buffer Pool划分为多个可使用innodb_buffer_pool_instances配置选项(默认为1),你可能也调整innodb_buffer_pool_size值调整Buffer Pool大小。 当InnoDB的Buffer Pool很大时,查询的请求可以从内存中检索获取。您可能会遇到来自多个线程试图访问Buffer Pool的瓶颈。您可以启用多个Buffer Pool以缓解这一情况。存储或读取的每个Page是使用一个Hash算法随机的分配给多个Buffer Pool的。每个多个Buffer Pool管理它自己的free lists和flush lists还有LRU,其他数据结构连接Buffer Pool,由它自己的Buffer Pool保护互斥。 要启用多个Buffer Pool实例,设置innodb_buffer_pool_instances配置选项的值大于1(默认值)到64(最大)。此选项生效,只有当你将innodb_buffer_pool_size调整为1 GB或更大的尺寸才能生效。您所指定的Buffer Pool总大小会划分。为了获得最佳的效率,指定innodb_buffer_pool_instances和innodb_buffer_pool_size的结合,使每个缓冲池实例至少1千兆字节。
Log buffer刷盘机制修改的innodb_flush_log_at_trx_commit
If the value of innodb_flush_log_at_trx_commit is 0, the log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but nothing is done at a transaction commit. When the value is 1 (the default), the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file. When the value is 2, the log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. However, the flushing on the log file takes place once per second also when the value is 2. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues. The default value of 1 is required for full ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose up to one second worth of transactions in a crash. With a value of 0, any mysqld process crash can erase the last second of transactions. With a value of 2, only an operating system crash or a power outage can erase the last second of transactions. InnoDB‘s crash recovery works regardless of the value. 当值为0,log_buffer日志缓冲区(上面彩图Memery-Disk结构图最下面的部分)每秒一次写出刷新到磁盘上的日志文件ib_logfile中,在单个事务提交时什么都不做。
当值为1(默认值),日志缓冲区写入到日志文件在每个事务提交和刷新到磁盘操作的日志文件执行。
当该值是2,日志缓冲区写出到文件在每次提交,但并不在其上执行的刷新到磁盘的操作。然而,在日志文件中的潮红发生每秒一次也当值为2。注意,一旦每秒冲洗不保证100%的情况发生每一秒,因为要处理的调度问题。 需要完全符合ACID的默认值1。您可以通过设置该值从1不同实现更好的性能,但你可能会失去多达交易的崩溃一秒钟的。随着一个0值,任何mysqld进程的崩溃可擦写的交易最后一秒。为2的值,只有一个操作系统崩溃或断电时可擦写交易的最后一秒。 InnoDB的崩溃恢复工程,无论价值。
物理结构
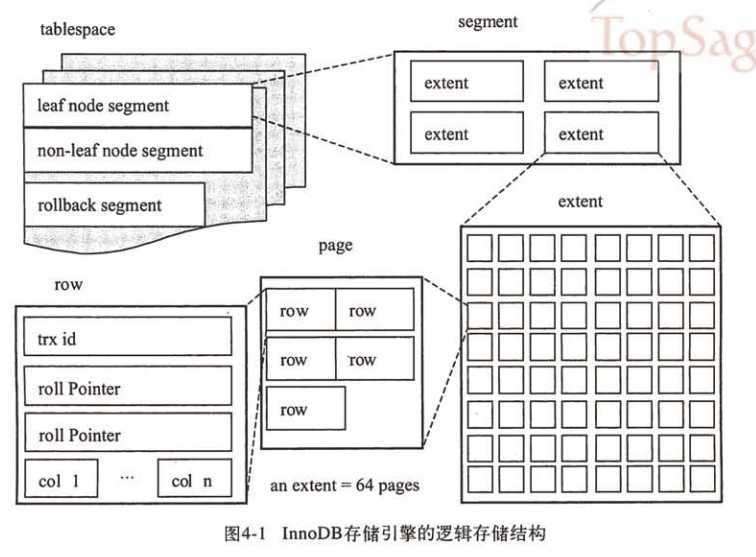
【转】mysql-innodb-buffer pool 结构分析
标签:des blog http os 使用 io strong 文件 for
原文地址:http://www.cnblogs.com/dba-fcl/p/3936985.html