标签:err 程序员 多层 rename digest 好的 源代码 元组 turn
定义:模块,用一砣代码实现了某类功能的代码集合。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,提供了代码的重用性。在Python中,一个.py文件就称之为一个模块(Module)。
注意:
模块分为三种:
使用模块有什么好处?
第一:最大的好处是大大提高了代码的可维护性。
其次:编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python
内置的模块和来自第三方的模块。
第三:使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,
不必考虑名字会与其他模块冲突。
但是也要注意:尽量不要与内置函数名字冲突。
注意:自定义模块不要与系统内置的模块同名!
2.模块须知:
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块用import:
import 语法:
import module1[, module2[,... moduleN]
Python 本身带着一些标准的模块库
#!/usr/bin/python3 # 文件名: using_sys.py import sys print(‘命令行参数如下:‘) for i in sys.argv: print(i) print(‘\n\nPython 路径为:‘, sys.path, ‘\n‘)
注意:
import os #获取文件的当前路径 current_path = os.path.dirname(__file__) #获取父级目录 pre_path = os.path.dirname(current_path) print(pre_path)
import拓展:
import module #导入整个模块,但是指定模块中的变量和函数并没有导入,导入之后就可以直接用module.[点]的方式访问里面的变量和方法了! from module.xx.xx import xx[,yy] #导入模块中某些变量或函数 from module.xx.xx import xx as rename[,yy as rename] #别名 from module.xx.xx import * #导入模块中所有的不是以下划线(_)开头的名字都导入到当前位置.[_]单下划线开头的是私有变量或者方法,只能在本模块使用,不可以在别的模块使用!
一般来说,应该避免使用from … import 而使用import语句,因为这样可以使你的程序更加易读,也可以避免名称冲突
导入模块其实就是告诉Python解释器去解释那个py文件
那么问题来了,导入模块时是根据那个路径作为基准来进行的呢?即:sys.path;如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append(‘路径‘) 添加。
sys.path.insert(0,‘/x/y/z‘) #排在前的目录,优先被搜索 sys.path.remove() #删除某个搜索目录
综上所述:当我们导入某个模块的时候,首先会从python内置的模块【内置模块如:sys】中找,找不到再去sys.path路径中查找【此路径包含当前目录(空目录)】
在一个模块中,我们可能会定义很多函数和变量,但有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。在Python中,是通过_前缀来实现的。
正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,x123,PI等;
类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途
比如:作者:__author__,文档注释__doc__就是特殊变量,hello模块定义的也可以用特殊变量访问,我们自己的变量一般不要用这种变量名;
类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;
之所以我们说,private函数和变量“不应该”被直接引用,而不是“不能”被直接引用,是因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量。
private函数或变量不应该被别人引用,那它们有什么用呢?请看例子:

def _private_1(name): return ‘Hello, %s‘ % name def _private_2(name): return ‘Hi, %s‘ % name def greeting(name): if len(name) > 3: return _private_1(name) else: return _private_2(name)
我们在模块里公开greeting()函数,而把内部逻辑用private函数隐藏起来了,这样,调用greeting()函数不用关心内部的private函数细节,这也是一种非常有用的代码封装和抽象的方法,即:
外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public。
__name__属性:
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
if __name__ == ‘__main__‘: print(‘程序自身在运行‘) else: print(‘我来自另一模块‘)
每个模块都有一个__name__属性,当其值是‘__main__‘时,表明该模块自身在运行,否则是被引入。
dir() 函数:
内置的函数 dir() 可以找到模块【可调用对象】内定义的所有属性和方法,这些方法可以以模块名.[点]的方式访问。以一个字符串列表的形式返回:
import sys print(sys.__name__) #注意:用import导入时是可以访问它的所有的属性和方法的! print(dir(sys))
如果没有参数,dir()列举出当前定义的名字
dir()不会列举出内建函数或者变量的名字,它们都被定义到了标准模块builtin中,可以列举出它们,
import builtins dir(builtins)
为了提高模块的加载速度,Python缓存编译的版本,每个模块在__pycache__目录的以module.version.pyc的形式命名,通常包含了python的版本号,如在CPython版本3.3,关于spam.py的编译版本将被缓存成__pycache__/spam.cpython-33.pyc,这种命名约定允许不同的版本,不同版本的Python编写模块共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA、NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
提示:
1.模块名区分大小写,foo.py与FOO.py代表的是两个模块
2.你可以使用-O或者-OO转换python命令来减少编译模块的大小
1 -O转换会帮你去掉assert语句 2 -OO转换会帮你去掉assert语句和__doc__文档字符串 3 由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要的情况下使用这些选项。
3.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的
4.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件
模块可以作为一个脚本(使用python -m compileall)编译Python源 python -m compileall /module_directory 递归着编译 如果使用python -O -m compileall /module_directory -l则只一层 命令行里使用compile()函数时,自动使用python -O -m compileall 详见:https://docs.python.org/3/library/compileall.html#module-compileall
总结:python并非完全是解释性语言,它是有编译的,先把源码py文件编译成pyc或者pyo,然后由python的虚拟机执行,相对于py文件来说,编译成pyc和pyo本质上和py没有太大区别,只是对于这个模块的加载速度提高了,并没有提高代码的执行速度,通常情况下不用主动去编译pyc文件,文档上说只要调用了import model那么model.py就会先编译成pyc然后加载。
你也许还想到,如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
函数就相当于工具,模块就是工具包,包就相当于工具包的集合!
举个例子,一个init.py的文件就是一个名字叫init的模块,一个Demo.py的文件就是一个名字叫Demo的模块。
现在,假设我们的init和Demo这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名,比如oop,按照如下目录存放:
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,init.py模块的名字就变成了oop.init,类似的,Demo.py的模块名变成了oop.Demo。
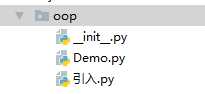
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。
__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是oop。
类似的,可以有多级目录,组成多级层次的包结构。比如如下的目录结构:
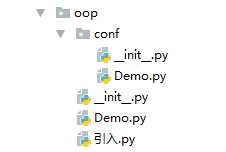
两个文件Demo.py的模块名分别是oop.Demo和oop.conf.Demo。
无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
包的本质就是一个包含__init__.py文件的目录。
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间:
glance/ #Top-level package ├── __init__.py #Initialize the glance package ├── api #Subpackage for api │ ├── __init__.py │ ├── policy.py │ └── versions.py ├── cmd #Subpackage for cmd │ ├── __init__.py │ └── manage.py └── db #Subpackage for db ├── __init__.py └── models.py
#文件内容 #policy.py def get(): print(‘from policy.py‘) #versions.py def create_resource(conf): print(‘from version.py: ‘,conf) #manage.py def main(): print(‘from manage.py‘) #models.py def register_models(engine): print(‘from models.py: ‘,engine)
2.1 注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点, 如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
import
我们在与包glance同级别的文件中测试
import glance.db.models glance.db.models.register_models(‘mysql‘)
from ... import ...
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
我们在与包glance同级别的文件中测试
from glance.db import models models.register_models(‘mysql‘) from glance.db.models import register_models register_models(‘mysql‘)
__init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有*,此处我们研究从一个包导入所有模块[*]。
此处是想从包api中导入所有,实际上该语句只会执行导入包api下__init__.py文件中的代码【,此时在导入的地方就可以引用定义在__init__文件的变量和方法了】,而没有导入这个包下的其它模块,要是想导入里面的某些或所有模块,我们可以在这个文件中定义__all__,然后将模块都放到__all__表示的列表中:
1 #在__init__.py中定义 2 x=10 3 4 def func(): 5 print(‘from api.__init.py‘) 6 7 __all__=[‘x‘,‘func‘,‘policy‘]
此时我们在于glance同级的文件中执行from glance.api import *就导入__all__中的内容(versions仍然不能导入),同时如果__init__文件中的变量或者函数如果不加入到__all__列表中,实际上在导入的地方也是不能够直接使用的,简言之:__all__限定了 glance.api import *导入包的时候只是导入了init文件的__all__中的所有内容[注意:__all__只是给from module import *用的哦]。
注意:上面的from glance.api import * 仅仅是导入一个包中的所有模块的时候是按着上面那么用,实际上如下:
从某个包中导入某个文件from glance.db import models即从glance.db包中导入models模块还是可以这么用的,然后使用models.register_models()函数也是可以的!
当然导入某个包某个文件中的所有不是以_开头的属性和方法也是可以的,如下所示:
from test.lib.aa import * #导入test包下lib包下的aa模块,然后就可以在下面使用aa模块中的af()函数了! af()
虽然有这种方式,但是不建议这么使用!
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/versions.py中想要导入glance/api/policy.py文件,这时候我们又在与glance包在同一级目录的py文件中导入了glance/api/versions.py就会出问题!如下所示:
import policy policy.get() #注意:此时导入policy模块,并调用policy模块中的get()方法是没问题的,此时执行的时候是以当前文件的相对路径导入的,所以没问题! def create_resource(conf): print(‘from version.py: ‘,conf)
import glance.api.versions #Demo.py与glance包在同一级目录,此时就会有问题,因为此时是以Demo的路径为当前路径执行的,当执行导入glance.api.versions的时候,在这个文件中 #又导入了policy文件,但是此时的policy文件查找路径是以Demo的路径为基准查找的,所以找不到,报错误!
出现如下错误[原因在上面已写]:
ImportError: No module named ‘policy‘
特别需要注意的是:可以用import导入内置或者第三方开源模块,但是要绝对避免使用import来导入自定义包的子模块,应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
这时我们可以导入例如:我们在glance/api/versions.py中想要导入glance/api/policy.py可以用相对路径和绝对路径的方式,如下所示:
from glance.api import policy #绝对路径 # from . import policy 相对路径 #from ..cmd import manage policy.get() def create_resource(conf): print(‘from version.py: ‘,conf)
尤其是我们在用到了包的概念的时候,我们对项目的组织结构就是一个项目下有多个包,包中再有子包或者py文件,此时我们包中的文件一定要用from ... import ... 的方式导入,方便自己在别的包使用,也方便给别人的时候使用!
单独导入包名称时不会导入包中所有包含的所有子模块,如:
#在与glance同级的test.py中 import glance glance.cmd.manage.main() ‘‘‘ 执行结果: AttributeError: module ‘glance‘ has no attribute ‘cmd‘ ‘‘‘
解决方法:
#glance/__init__.py from . import cmd #glance/cmd/__init__.py from . import manage
千万别问:__all__不能解决吗,__all__是用于控制from...import * ,fuck!
综上所述:在包内的py文件如果想要导入自己写的py文件就用from module import 导入【如果导入的是内置的或者第三方包可以用import】,在包外面导入包【导入包中的文件就不用这么做了】的时候,可以用我们上面这种方式,在包下面的__init__.py文件中加入 from . import module/py
下载安装有两种方式:
yum pip apt-get ...
下载源码
解压源码
进入目录
编译源码 python setup.py build
安装源码 python setup.py install
注:在使用源码安装时,需要使用到gcc编译和python开发环境,所以,需要先执行:
yum install gcc yum install python-devel 或 apt-get python-dev
安装成功后,模块会自动安装到 sys.path 中的某个目录中,如:
/usr/lib/python2.7/site-packages/
二、导入模块
同自定义模块中导入的方式
三、模块 paramiko
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实。
1、下载安装
pip3 install paramiko
或
# pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto # 下载安装 pycrypto wget http://files.cnblogs.com/files/wupeiqi/pycrypto-2.6.1.tar.gz tar -xvf pycrypto-2.6.1.tar.gz cd pycrypto-2.6.1 python setup.py build python setup.py install # 进入python环境,导入Crypto检查是否安装成功 # 下载安装 paramiko wget http://files.cnblogs.com/files/wupeiqi/paramiko-1.10.1.tar.gz tar -xvf paramiko-1.10.1.tar.gz cd paramiko-1.10.1 python setup.py build python setup.py install # 进入python环境,导入paramiko检查是否安装成功
2、使用模块
#!/usr/bin/env python #coding:utf-8 import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(‘192.168.1.108‘, 22, ‘alex‘, ‘123‘) stdin, stdout, stderr = ssh.exec_command(‘df‘) print stdout.read() ssh.close();
执行命令 - 过密钥链接服务器
import os,sys import paramiko t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,password=‘123‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.put(‘/tmp/test.py‘,‘/tmp/test.py‘) t.close() import os,sys import paramiko t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,password=‘123‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.get(‘/tmp/test.py‘,‘/tmp/test2.py‘) t.close()
上传或下载文件 - 通过密钥一、os
用于提供系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: (‘.‘) os.pardir 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
更多猛击这里
二、sys
用于提供对解释器相关的操作
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write(‘please:‘) val = sys.stdin.readline()[:-1]
更多猛击这里
三、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import md5 hash = md5.new() hash.update(‘admin‘) print hash.hexdigest()
import sha hash = sha.new() hash.update(‘admin‘) print hash.hexdigest()
import hashlib # ######## md5 ######## hash = hashlib.md5() hash.update(‘admin‘) print hash.hexdigest() # ######## sha1 ######## hash = hashlib.sha1() hash.update(‘admin‘) print hash.hexdigest() # ######## sha256 ######## hash = hashlib.sha256() hash.update(‘admin‘) print hash.hexdigest() # ######## sha384 ######## hash = hashlib.sha384() hash.update(‘admin‘) print hash.hexdigest() # ######## sha512 ######## hash = hashlib.sha512() hash.update(‘admin‘) print hash.hexdigest()
为什么要设计好目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
目录组织方式
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。在Stackoverflow的这个问题上,能看到大家对Python目录结构的讨论。
这里面说的已经很好了,我也不打算重新造轮子列举各种不同的方式,这里面我说一下我的理解和体会。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
简要解释一下:
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。docs/: 存放一些文档。setup.py: 安装、部署、打包的脚本。requirements.txt: 存放软件依赖的外部Python包列表。README: 项目说明文件。除此之外,有一些方案给出了更加多的内容。比如LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织,可以参考这篇文章。
下面,再简单讲一下我对这些目录的理解和个人要求吧。
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具setuptools来管理这些事情。这种方式普遍应用于开源项目中。不过这里的核心思想不是用标准化的工具来解决这些问题,而是说,一个项目一定要有一个安装部署工具,能快速便捷的在一台新机器上将环境装好、代码部署好和将程序运行起来。
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的文档比较庞大,刚接触的话,可能不太好找到切入点。学习技术的方式就是看他人是怎么用的,可以参考一下Python的一个Web框架,flask是如何写的: setup.py
当然,简单点自己写个安装脚本(deploy.sh)替代setup.py也未尝不可。
requirements.txt
这个文件存在的目的是:
setup.py安装依赖时漏掉软件包。这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明: 点这里。
关于配置文件的使用方法
注意,在上面的目录结构中,没有将conf.py放在源码目录下,而是放在docs/目录下。
很多项目对配置文件的使用做法是:
import conf这种形式来在代码中使用配置。这种做法我不太赞同:
conf.py这个文件。所以,我认为配置的使用,更好的方式是,
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的。
标签:err 程序员 多层 rename digest 好的 源代码 元组 turn
原文地址:http://www.cnblogs.com/python-machine/p/6836342.html
